 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJohn Palowitch
Where Do We Go from Here? Multi-scale Allocentric Relational Inference from Natural Spatial Descriptions
Feb 26, 2024
When communicating routes in natural language, the concept of {\em acquired spatial knowledge} is crucial for geographic information retrieval (GIR) and in spatial cognitive research. However, NLP navigation studies often overlook the impact of such acquired knowledge on textual descriptions. Current navigation studies concentrate on egocentric local descriptions (e.g., `it will be on your right') that require reasoning over the agent's local perception. These instructions are typically given as a sequence of steps, with each action-step explicitly mentioning and being followed by a landmark that the agent can use to verify they are on the right path (e.g., `turn right and then you will see...'). In contrast, descriptions based on knowledge acquired through a map provide a complete view of the environment and capture its overall structure. These instructions (e.g., `it is south of Central Park and a block north of a police station') are typically non-sequential, contain allocentric relations, with multiple spatial relations and implicit actions, without any explicit verification. This paper introduces the Rendezvous (RVS) task and dataset, which includes 10,404 examples of English geospatial instructions for reaching a target location using map-knowledge. Our analysis reveals that RVS exhibits a richer use of spatial allocentric relations, and requires resolving more spatial relations simultaneously compared to previous text-based navigation benchmarks.
Examining the Effects of Degree Distribution and Homophily in Graph Learning Models
Jul 17, 2023

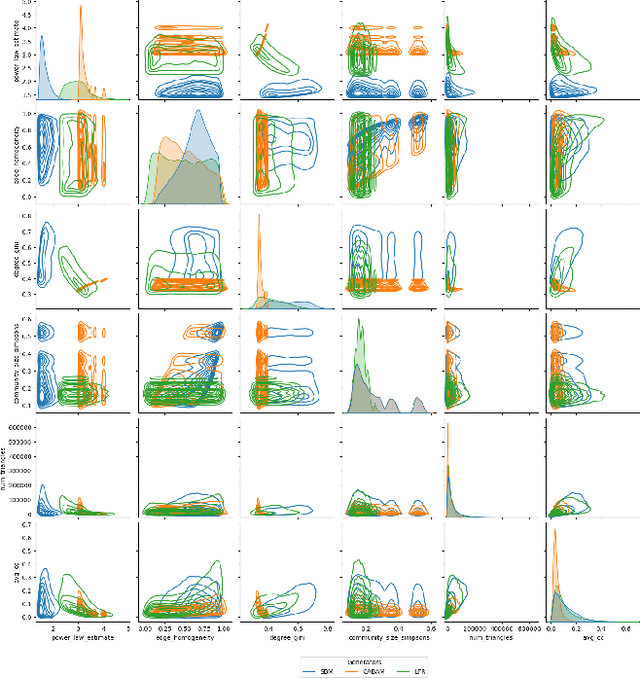

Despite a surge in interest in GNN development, homogeneity in benchmarking datasets still presents a fundamental issue to GNN research. GraphWorld is a recent solution which uses the Stochastic Block Model (SBM) to generate diverse populations of synthetic graphs for benchmarking any GNN task. Despite its success, the SBM imposed fundamental limitations on the kinds of graph structure GraphWorld could create. In this work we examine how two additional synthetic graph generators can improve GraphWorld's evaluation; LFR, a well-established model in the graph clustering literature and CABAM, a recent adaptation of the Barabasi-Albert model tailored for GNN benchmarking. By integrating these generators, we significantly expand the coverage of graph space within the GraphWorld framework while preserving key graph properties observed in real-world networks. To demonstrate their effectiveness, we generate 300,000 graphs to benchmark 11 GNN models on a node classification task. We find GNN performance variations in response to homophily, degree distribution and feature signal. Based on these findings, we classify models by their sensitivity to the new generators under these properties. Additionally, we release the extensions made to GraphWorld on the GitHub repository, offering further evaluation of GNN performance on new graphs.
Scalable Privacy-enhanced Benchmark Graph Generative Model for Graph Convolutional Networks
Jul 10, 2022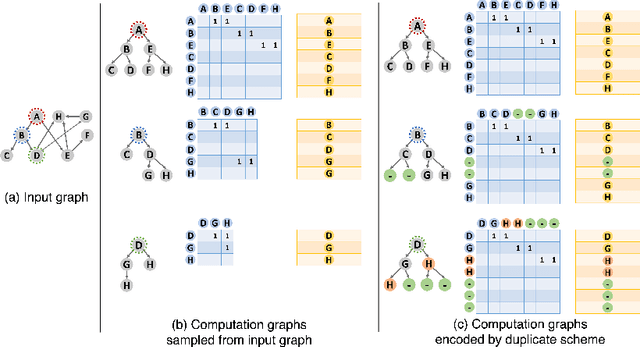
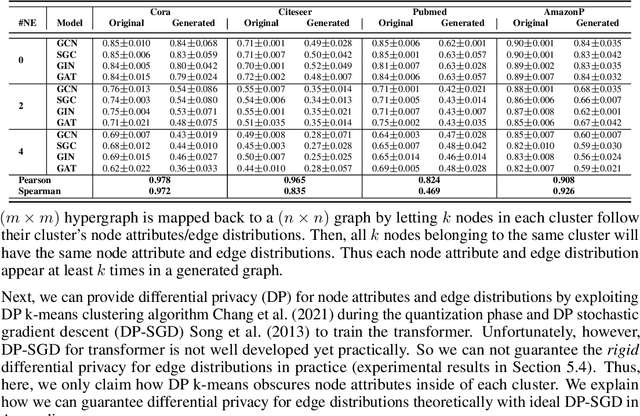
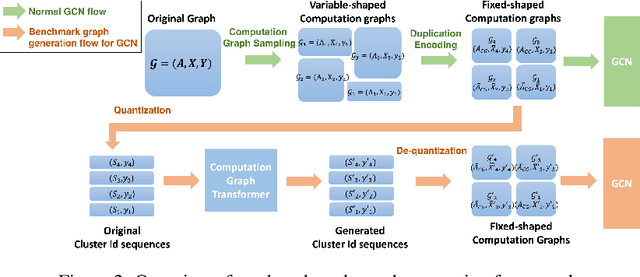
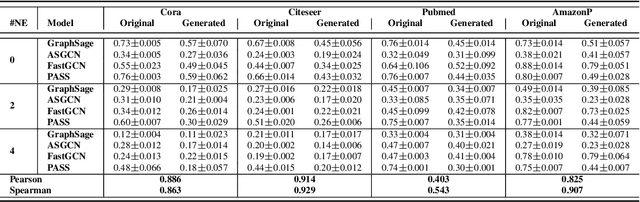
A surge of interest in Graph Convolutional Networks (GCN) has produced thousands of GCN variants, with hundreds introduced every year. In contrast, many GCN models re-use only a handful of benchmark datasets as many graphs of interest, such as social or commercial networks, are proprietary. We propose a new graph generation problem to enable generating a diverse set of benchmark graphs for GCNs following the distribution of a source graph -- possibly proprietary -- with three requirements: 1) benchmark effectiveness as a substitute for the source graph for GCN research, 2) scalability to process large-scale real-world graphs, and 3) a privacy guarantee for end-users. With a novel graph encoding scheme, we reframe large-scale graph generation problem into medium-length sequence generation problem and apply the strong generation power of the Transformer architecture to the graph domain. Extensive experiments across a vast body of graph generative models show that our model can successfully generate benchmark graphs with the realistic graph structure, node attributes, and node labels required to benchmark GCNs on node classification tasks.
TF-GNN: Graph Neural Networks in TensorFlow
Jul 07, 2022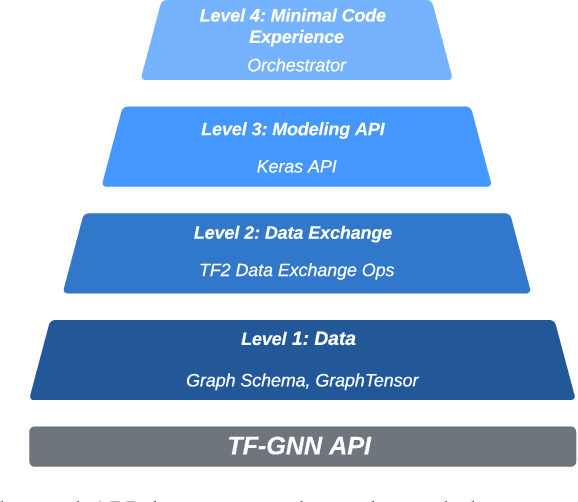
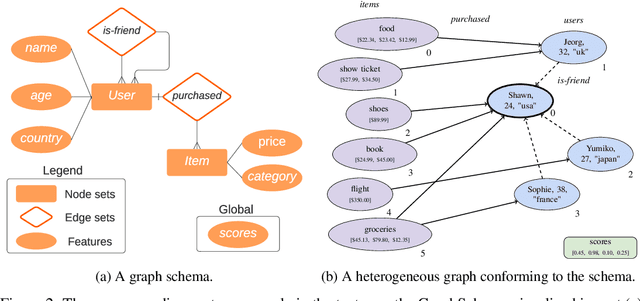
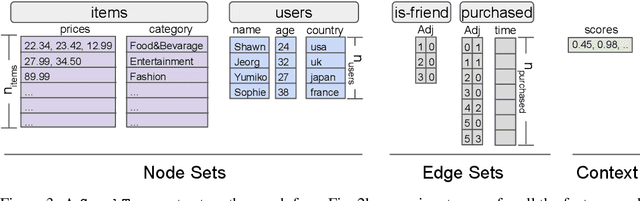
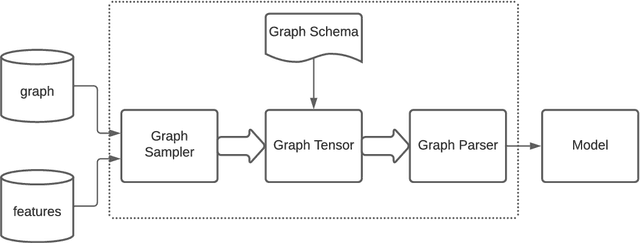
TensorFlow GNN (TF-GNN) is a scalable library for Graph Neural Networks in TensorFlow. It is designed from the bottom up to support the kinds of rich heterogeneous graph data that occurs in today's information ecosystems. Many production models at Google use TF-GNN and it has been recently released as an open source project. In this paper, we describe the TF-GNN data model, its Keras modeling API, and relevant capabilities such as graph sampling, distributed training, and accelerator support.
Synthetic Graph Generation to Benchmark Graph Learning
Apr 04, 2022


Graph learning algorithms have attained state-of-the-art performance on many graph analysis tasks such as node classification, link prediction, and clustering. It has, however, become hard to track the field's burgeoning progress. One reason is due to the very small number of datasets used in practice to benchmark the performance of graph learning algorithms. This shockingly small sample size (~10) allows for only limited scientific insight into the problem. In this work, we aim to address this deficiency. We propose to generate synthetic graphs, and study the behaviour of graph learning algorithms in a controlled scenario. We develop a fully-featured synthetic graph generator that allows deep inspection of different models. We argue that synthetic graph generations allows for thorough investigation of algorithms and provides more insights than overfitting on three citation datasets. In the case study, we show how our framework provides insight into unsupervised and supervised graph neural network models.
Zero-shot Domain Adaptation of Heterogeneous Graphs via Knowledge Transfer Networks
Mar 03, 2022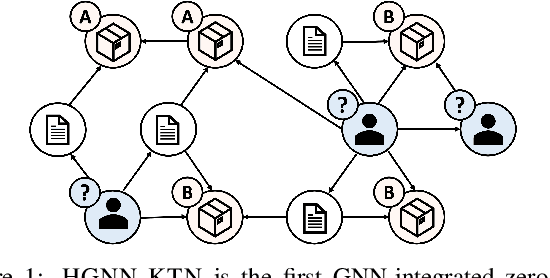
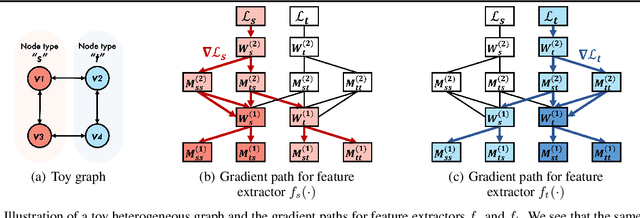

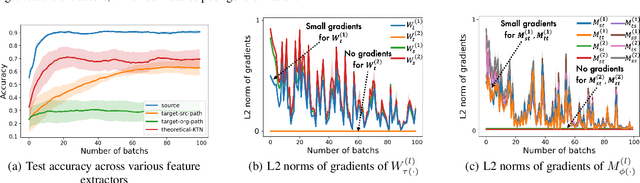
How can we make predictions for nodes in a heterogeneous graph when an entire type of node (e.g. user) has no labels (perhaps due to privacy issues) at all? Although heterogeneous graph neural networks (HGNNs) have shown superior performance as powerful representation learning techniques, there is no direct way to learn using labels rooted at different node types. Domain adaptation (DA) targets this setting, however, existing DA can not be applied directly to HGNNs. In heterogeneous graphs, the source and target domains have different modalities, thus HGNNs provide different feature extractors to them, while most of DA assumes source and target domains share a common feature extractor. In this work, we address the issue of zero-shot domain adaptation in HGNNs. We first theoretically induce a relationship between source and target domain features extracted from HGNNs, then propose a novel domain adaptation method, Knowledge Transfer Networks for HGNNs (HGNN-KTN). HGNN-KTN learns the relationship between source and target features, then maps the target distributions into the source domain. HGNN-KTN outperforms state-of-the-art baselines, showing up to 73.3% higher in MRR on 18 different domain adaptation tasks running on real-world benchmark graphs.
GraphWorld: Fake Graphs Bring Real Insights for GNNs
Feb 28, 2022



Despite advances in the field of Graph Neural Networks (GNNs), only a small number (~5) of datasets are currently used to evaluate new models. This continued reliance on a handful of datasets provides minimal insight into the performance differences between models, and is especially challenging for industrial practitioners who are likely to have datasets which look very different from those used as academic benchmarks. In the course of our work on GNN infrastructure and open-source software at Google, we have sought to develop improved benchmarks that are robust, tunable, scalable,and generalizable. In this work we introduce GraphWorld, a novel methodology and system for benchmarking GNN models on an arbitrarily-large population of synthetic graphs for any conceivable GNN task. GraphWorld allows a user to efficiently generate a world with millions of statistically diverse datasets. It is accessible, scalable, and easy to use. GraphWorld can be run on a single machine without specialized hardware, or it can be easily scaled up to run on arbitrary clusters or cloud frameworks. Using GraphWorld, a user has fine-grained control over graph generator parameters, and can benchmark arbitrary GNN models with built-in hyperparameter tuning. We present insights from GraphWorld experiments regarding the performance characteristics of tens of thousands of GNN models over millions of benchmark datasets. We further show that GraphWorld efficiently explores regions of benchmark dataset space uncovered by standard benchmarks, revealing comparisons between models that have not been historically obtainable. Using GraphWorld, we also are able to study in-detail the relationship between graph properties and task performance metrics, which is nearly impossible with the classic collection of real-world benchmarks.
Recurrent Graph Neural Networks for Rumor Detection in Online Forums
Aug 08, 2021


The widespread adoption of online social networks in daily life has created a pressing need for effectively classifying user-generated content. This work presents techniques for classifying linked content spread on forum websites -- specifically, links to news articles or blogs -- using user interaction signals alone. Importantly, online forums such as Reddit do not have a user-generated social graph, which is assumed in social network behavioral-based classification settings. Using Reddit as a case-study, we show how to obtain a derived social graph, and use this graph, Reddit post sequences, and comment trees as inputs to a Recurrent Graph Neural Network (R-GNN) encoder. We train the R-GNN on news link categorization and rumor detection, showing superior results to recent baselines. Our code is made publicly available at https://github.com/google-research/social_cascades.
Finding Stable Groups of Cross-Correlated Features in Multi-View data
Sep 10, 2020



Multi-view data, in which data of different types are obtained from a common set of samples, is now common in many scientific problems. An important problem in the analysis of multi-view data is identifying interactions between groups of features from different data types. A bimodule is a pair $(A,B)$ of feature sets from two different data types such that the aggregate cross-correlation between the features in $A$ and those in $B$ is large. A bimodule $(A,B)$ is stable if $A$ coincides with the set of features having significant aggregate correlation with the features in $B$, and vice-versa. At the population level, stable bimodules correspond to connected components of the cross-correlation network, which is the bipartite graph whose edges are pairs of features with non-zero cross-correlations. We develop an iterative, testing-based procedure, called BSP, to identify stable bimodules in two moderate- to high-dimensional data sets. BSP relies on permutation-based p-values for sums of squared cross-correlations. We efficiently approximate the p-values using tail probabilities of gamma distributions that are fit using analytical estimates of the permutation moments of the test statistic. Our moment estimates depend on the eigenvalues of the intra-correlation matrices of $A$ and $B$ and as a result, the significance of observed cross-correlations accounts for the correlations within each data type. We carry out a thorough simulation study to assess the performance of BSP, and present an extended application of BSP to the problem of expression quantitative trait loci (eQTL) analysis using recent data from the GTEx project. In addition, we apply BSP to climatology data in order to identify regions in North America where annual temperature variation affects precipitation.
Graph Clustering with Graph Neural Networks
Jun 30, 2020



Graph Neural Networks (GNNs) have achieved state-of-the-art results on many graph analysis tasks such as node classification and link prediction. However, important unsupervised problems on graphs, such as graph clustering, have proved more resistant to advances in GNNs. In this paper, we study unsupervised training of GNN pooling in terms of their clustering capabilities. We start by drawing a connection between graph clustering and graph pooling: intuitively, a good graph clustering is what one would expect from a GNN pooling layer. Counterintuitively, we show that this is not true for state-of-the-art pooling methods, such as MinCut pooling. To address these deficiencies, we introduce Deep Modularity Networks (DMoN), an unsupervised pooling method inspired by the modularity measure of clustering quality, and show how it tackles recovery of the challenging clustering structure of real-world graphs. In order to clarify the regimes where existing methods fail, we carefully design a set of experiments on synthetic data which show that DMoN is able to jointly leverage the signal from the graph structure and node attributes. Similarly, on real-world data, we show that DMoN produces high quality clusters which correlate strongly with ground truth labels, achieving state-of-the-art results.