 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVincent Cohen-Addad
Data-Efficient Learning via Clustering-Based Sensitivity Sampling: Foundation Models and Beyond
Feb 27, 2024
We study the data selection problem, whose aim is to select a small representative subset of data that can be used to efficiently train a machine learning model. We present a new data selection approach based on $k$-means clustering and sensitivity sampling. Assuming access to an embedding representation of the data with respect to which the model loss is H\"older continuous, our approach provably allows selecting a set of ``typical'' $k + 1/\varepsilon^2$ elements whose average loss corresponds to the average loss of the whole dataset, up to a multiplicative $(1\pm\varepsilon)$ factor and an additive $\varepsilon \lambda \Phi_k$, where $\Phi_k$ represents the $k$-means cost for the input embeddings and $\lambda$ is the H\"older constant. We furthermore demonstrate the performance and scalability of our approach on fine-tuning foundation models and show that it outperforms state-of-the-art methods. We also show how it can be applied on linear regression, leading to a new sampling strategy that surprisingly matches the performances of leverage score sampling, while being conceptually simpler and more scalable.
A Scalable Algorithm for Individually Fair K-means Clustering
Feb 09, 2024We present a scalable algorithm for the individually fair ($p$, $k$)-clustering problem introduced by Jung et al. and Mahabadi et al. Given $n$ points $P$ in a metric space, let $\delta(x)$ for $x\in P$ be the radius of the smallest ball around $x$ containing at least $n / k$ points. A clustering is then called individually fair if it has centers within distance $\delta(x)$ of $x$ for each $x\in P$. While good approximation algorithms are known for this problem no efficient practical algorithms with good theoretical guarantees have been presented. We design the first fast local-search algorithm that runs in ~$O(nk^2)$ time and obtains a bicriteria $(O(1), 6)$ approximation. Then we show empirically that not only is our algorithm much faster than prior work, but it also produces lower-cost solutions.
A quasi-polynomial time algorithm for Multi-Dimensional Scaling via LP hierarchies
Nov 29, 2023Multi-dimensional Scaling (MDS) is a family of methods for embedding pair-wise dissimilarities between $n$ objects into low-dimensional space. MDS is widely used as a data visualization tool in the social and biological sciences, statistics, and machine learning. We study the Kamada-Kawai formulation of MDS: given a set of non-negative dissimilarities $\{d_{i,j}\}_{i , j \in [n]}$ over $n$ points, the goal is to find an embedding $\{x_1,\dots,x_n\} \subset \mathbb{R}^k$ that minimizes \[ \text{OPT} = \min_{x} \mathbb{E}_{i,j \in [n]} \left[ \left(1-\frac{\|x_i - x_j\|}{d_{i,j}}\right)^2 \right] \] Despite its popularity, our theoretical understanding of MDS is extremely limited. Recently, Demaine, Hesterberg, Koehler, Lynch, and Urschel (arXiv:2109.11505) gave the first approximation algorithm with provable guarantees for Kamada-Kawai, which achieves an embedding with cost $\text{OPT} +\epsilon$ in $n^2 \cdot 2^{\tilde{\mathcal{O}}(k \Delta^4 / \epsilon^2)}$ time, where $\Delta$ is the aspect ratio of the input dissimilarities. In this work, we give the first approximation algorithm for MDS with quasi-polynomial dependency on $\Delta$: for target dimension $k$, we achieve a solution with cost $\mathcal{O}(\text{OPT}^{ \hspace{0.04in}1/k } \cdot \log(\Delta/\epsilon) )+ \epsilon$ in time $n^{ \mathcal{O}(1)} \cdot 2^{\tilde{\mathcal{O}}( k^2 (\log(\Delta)/\epsilon)^{k/2 + 1} ) }$. Our approach is based on a novel analysis of a conditioning-based rounding scheme for the Sherali-Adams LP Hierarchy. Crucially, our analysis exploits the geometry of low-dimensional Euclidean space, allowing us to avoid an exponential dependence on the aspect ratio $\Delta$. We believe our geometry-aware treatment of the Sherali-Adams Hierarchy is an important step towards developing general-purpose techniques for efficient metric optimization algorithms.
Multi-Swap $k$-Means++
Sep 28, 2023The $k$-means++ algorithm of Arthur and Vassilvitskii (SODA 2007) is often the practitioners' choice algorithm for optimizing the popular $k$-means clustering objective and is known to give an $O(\log k)$-approximation in expectation. To obtain higher quality solutions, Lattanzi and Sohler (ICML 2019) proposed augmenting $k$-means++ with $O(k \log \log k)$ local search steps obtained through the $k$-means++ sampling distribution to yield a $c$-approximation to the $k$-means clustering problem, where $c$ is a large absolute constant. Here we generalize and extend their local search algorithm by considering larger and more sophisticated local search neighborhoods hence allowing to swap multiple centers at the same time. Our algorithm achieves a $9 + \varepsilon$ approximation ratio, which is the best possible for local search. Importantly we show that our approach yields substantial practical improvements, we show significant quality improvements over the approach of Lattanzi and Sohler (ICML 2019) on several datasets.
Differentially-Private Hierarchical Clustering with Provable Approximation Guarantees
Jan 31, 2023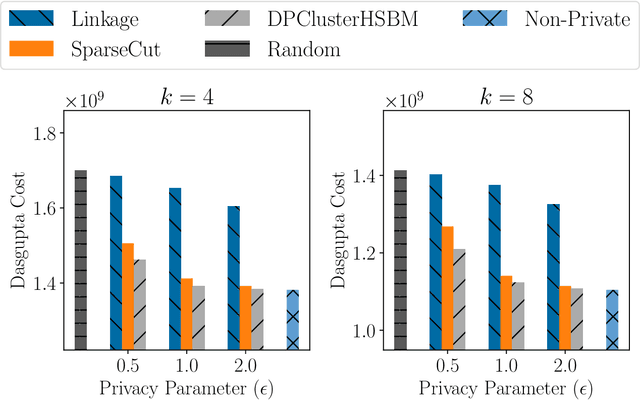
Hierarchical Clustering is a popular unsupervised machine learning method with decades of history and numerous applications. We initiate the study of differentially private approximation algorithms for hierarchical clustering under the rigorous framework introduced by (Dasgupta, 2016). We show strong lower bounds for the problem: that any $\epsilon$-DP algorithm must exhibit $O(|V|^2/ \epsilon)$-additive error for an input dataset $V$. Then, we exhibit a polynomial-time approximation algorithm with $O(|V|^{2.5}/ \epsilon)$-additive error, and an exponential-time algorithm that meets the lower bound. To overcome the lower bound, we focus on the stochastic block model, a popular model of graphs, and, with a separation assumption on the blocks, propose a private $1+o(1)$ approximation algorithm which also recovers the blocks exactly. Finally, we perform an empirical study of our algorithms and validate their performance.
Private estimation algorithms for stochastic block models and mixture models
Jan 11, 2023We introduce general tools for designing efficient private estimation algorithms, in the high-dimensional settings, whose statistical guarantees almost match those of the best known non-private algorithms. To illustrate our techniques, we consider two problems: recovery of stochastic block models and learning mixtures of spherical Gaussians. For the former, we present the first efficient $(\epsilon, \delta)$-differentially private algorithm for both weak recovery and exact recovery. Previously known algorithms achieving comparable guarantees required quasi-polynomial time. For the latter, we design an $(\epsilon, \delta)$-differentially private algorithm that recovers the centers of the $k$-mixture when the minimum separation is at least $ O(k^{1/t}\sqrt{t})$. For all choices of $t$, this algorithm requires sample complexity $n\geq k^{O(1)}d^{O(t)}$ and time complexity $(nd)^{O(t)}$. Prior work required minimum separation at least $O(\sqrt{k})$ as well as an explicit upper bound on the Euclidean norm of the centers.
Improved Coresets for Euclidean $k$-Means
Nov 16, 2022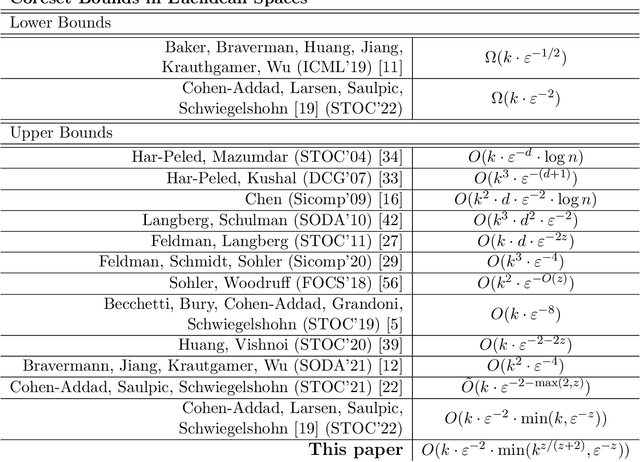
Given a set of $n$ points in $d$ dimensions, the Euclidean $k$-means problem (resp. the Euclidean $k$-median problem) consists of finding $k$ centers such that the sum of squared distances (resp. sum of distances) from every point to its closest center is minimized. The arguably most popular way of dealing with this problem in the big data setting is to first compress the data by computing a weighted subset known as a coreset and then run any algorithm on this subset. The guarantee of the coreset is that for any candidate solution, the ratio between coreset cost and the cost of the original instance is less than a $(1\pm \varepsilon)$ factor. The current state of the art coreset size is $\tilde O(\min(k^{2} \cdot \varepsilon^{-2},k\cdot \varepsilon^{-4}))$ for Euclidean $k$-means and $\tilde O(\min(k^{2} \cdot \varepsilon^{-2},k\cdot \varepsilon^{-3}))$ for Euclidean $k$-median. The best known lower bound for both problems is $\Omega(k \varepsilon^{-2})$. In this paper, we improve the upper bounds $\tilde O(\min(k^{3/2} \cdot \varepsilon^{-2},k\cdot \varepsilon^{-4}))$ for $k$-means and $\tilde O(\min(k^{4/3} \cdot \varepsilon^{-2},k\cdot \varepsilon^{-3}))$ for $k$-median. In particular, ours is the first provable bound that breaks through the $k^2$ barrier while retaining an optimal dependency on $\varepsilon$.
Scalable Differentially Private Clustering via Hierarchically Separated Trees
Jun 17, 2022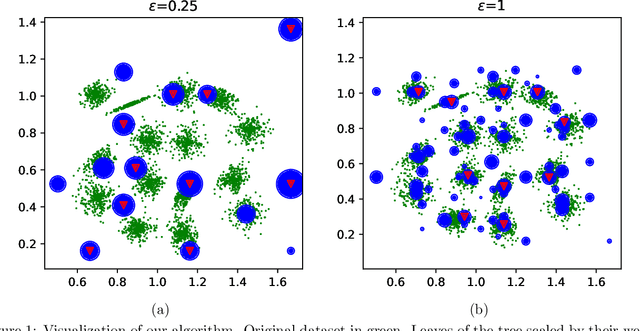
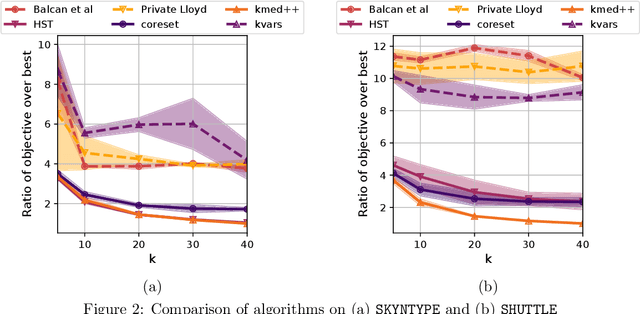
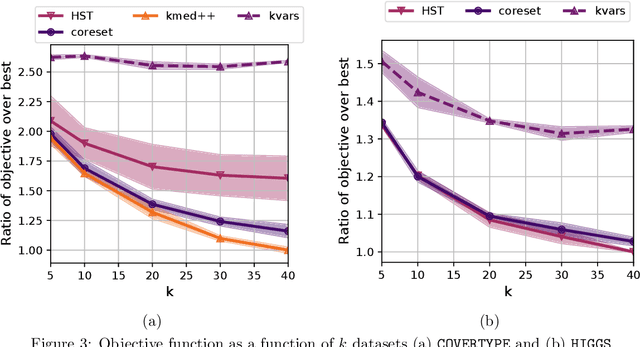
We study the private $k$-median and $k$-means clustering problem in $d$ dimensional Euclidean space. By leveraging tree embeddings, we give an efficient and easy to implement algorithm, that is empirically competitive with state of the art non private methods. We prove that our method computes a solution with cost at most $O(d^{3/2}\log n)\cdot OPT + O(k d^2 \log^2 n / \epsilon^2)$, where $\epsilon$ is the privacy guarantee. (The dimension term, $d$, can be replaced with $O(\log k)$ using standard dimension reduction techniques.) Although the worst-case guarantee is worse than that of state of the art private clustering methods, the algorithm we propose is practical, runs in near-linear, $\tilde{O}(nkd)$, time and scales to tens of millions of points. We also show that our method is amenable to parallelization in large-scale distributed computing environments. In particular we show that our private algorithms can be implemented in logarithmic number of MPC rounds in the sublinear memory regime. Finally, we complement our theoretical analysis with an empirical evaluation demonstrating the algorithm's efficiency and accuracy in comparison to other privacy clustering baselines.
Beyond Impossibility: Balancing Sufficiency, Separation and Accuracy
May 24, 2022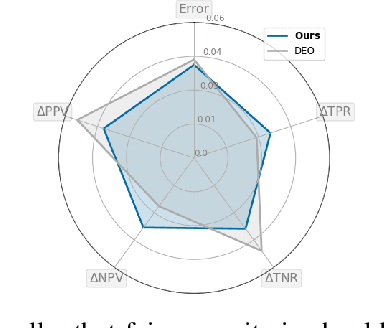

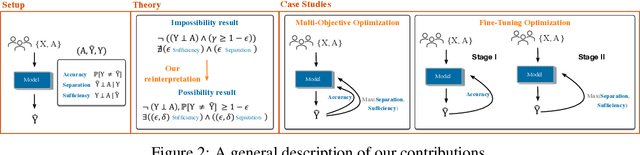
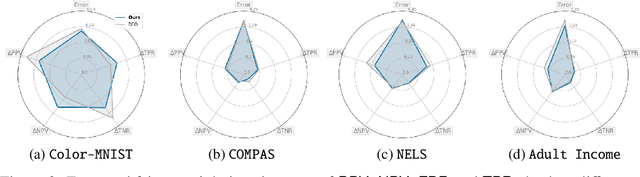
Among the various aspects of algorithmic fairness studied in recent years, the tension between satisfying both \textit{sufficiency} and \textit{separation} -- e.g. the ratios of positive or negative predictive values, and false positive or false negative rates across groups -- has received much attention. Following a debate sparked by COMPAS, a criminal justice predictive system, the academic community has responded by laying out important theoretical understanding, showing that one cannot achieve both with an imperfect predictor when there is no equal distribution of labels across the groups. In this paper, we shed more light on what might be still possible beyond the impossibility -- the existence of a trade-off means we should aim to find a good balance within it. After refining the existing theoretical result, we propose an objective that aims to balance \textit{sufficiency} and \textit{separation} measures, while maintaining similar accuracy levels. We show the use of such an objective in two empirical case studies, one involving a multi-objective framework, and the other fine-tuning of a model pre-trained for accuracy. We show promising results, where better trade-offs are achieved compared to existing alternatives.
Improved Approximations for Euclidean $k$-means and $k$-median, via Nested Quasi-Independent Sets
Apr 12, 2022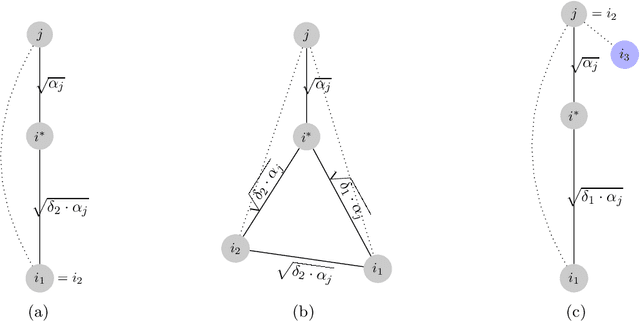
Motivated by data analysis and machine learning applications, we consider the popular high-dimensional Euclidean $k$-median and $k$-means problems. We propose a new primal-dual algorithm, inspired by the classic algorithm of Jain and Vazirani and the recent algorithm of Ahmadian, Norouzi-Fard, Svensson, and Ward. Our algorithm achieves an approximation ratio of $2.406$ and $5.912$ for Euclidean $k$-median and $k$-means, respectively, improving upon the 2.633 approximation ratio of Ahmadian et al. and the 6.1291 approximation ratio of Grandoni, Ostrovsky, Rabani, Schulman, and Venkat. Our techniques involve a much stronger exploitation of the Euclidean metric than previous work on Euclidean clustering. In addition, we introduce a new method of removing excess centers using a variant of independent sets over graphs that we dub a "nested quasi-independent set". In turn, this technique may be of interest for other optimization problems in Euclidean and $\ell_p$ metric spaces.