 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeilong Cao
On the Approximation Lower Bound for Neural Nets with Random Weights
Aug 19, 2020
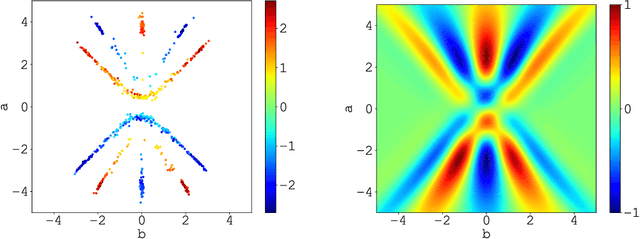
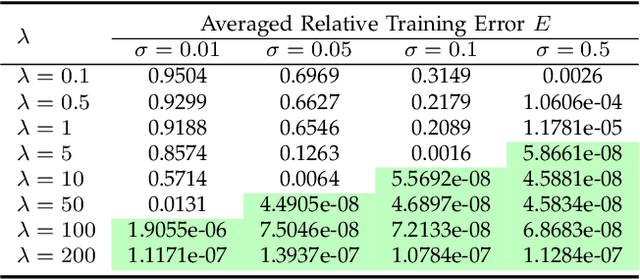
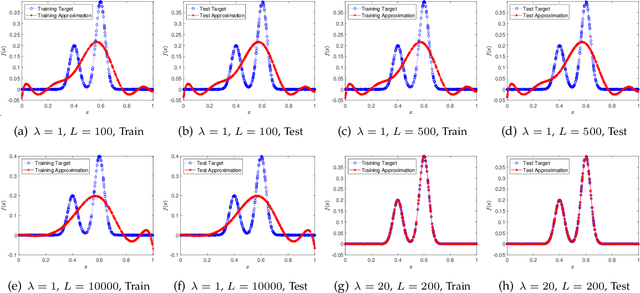
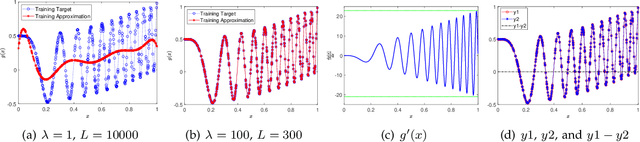
A random net is a shallow neural network where the hidden layer is frozen with random assignment and the output layer is trained by convex optimization. Using random weights for a hidden layer is an effective method to avoid the inevitable non-convexity in standard gradient descent learning. It has recently been adopted in the study of deep learning theory. Here, we investigate the expressive power of random nets. We show that, despite the well-known fact that a shallow neural network is a universal approximator, a random net cannot achieve zero approximation error even for smooth functions. In particular, we prove that for a class of smooth functions, if the proposal distribution is compactly supported, then a lower bound is positive. Based on the ridgelet analysis and harmonic analysis for neural networks, the proof uses the Plancherel theorem and an estimate for the truncated tail of the parameter distribution. We corroborate our theoretical results with various simulation studies, and generally two main take-home messages are offered: (i) Not any distribution for selecting random weights is feasible to build a universal approximator; (ii) A suitable assignment of random weights exists but to some degree is associated with the complexity of the target function.
A study on effectiveness of extreme learning machine
Sep 13, 2014
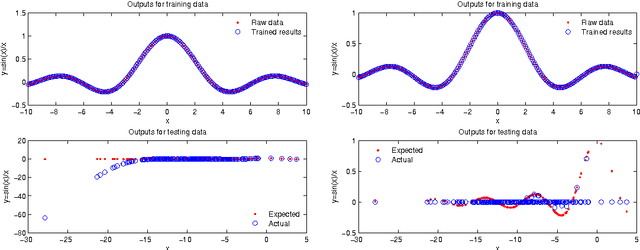
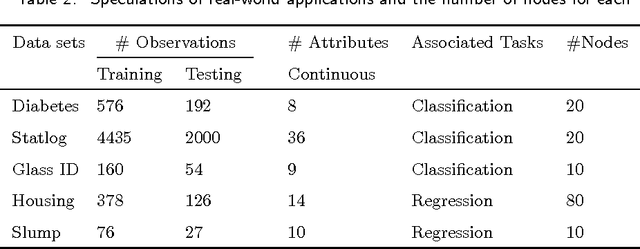
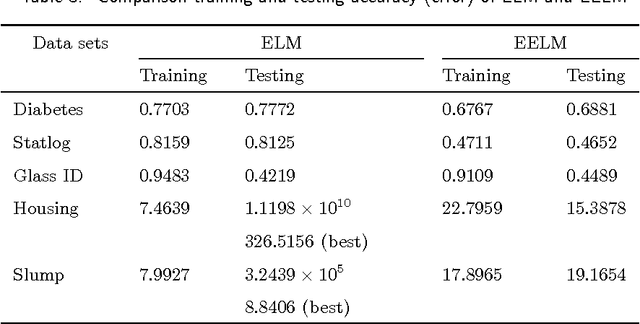
Extreme learning machine (ELM), proposed by Huang et al., has been shown a promising learning algorithm for single-hidden layer feedforward neural networks (SLFNs). Nevertheless, because of the random choice of input weights and biases, the ELM algorithm sometimes makes the hidden layer output matrix H of SLFN not full column rank, which lowers the effectiveness of ELM. This paper discusses the effectiveness of ELM and proposes an improved algorithm called EELM that makes a proper selection of the input weights and bias before calculating the output weights, which ensures the full column rank of H in theory. This improves to some extend the learning rate (testing accuracy, prediction accuracy, learning time) and the robustness property of the networks. The experimental results based on both the benchmark function approximation and real-world problems including classification and regression applications show the good performances of EELM.