 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYuguang Wang
Can neural networks learn persistent homology features?
Nov 30, 2020
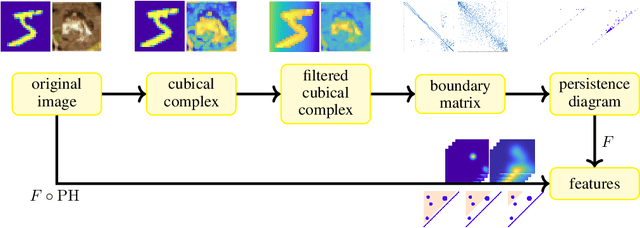
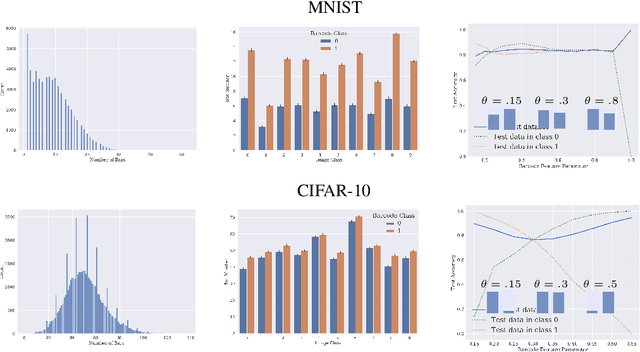
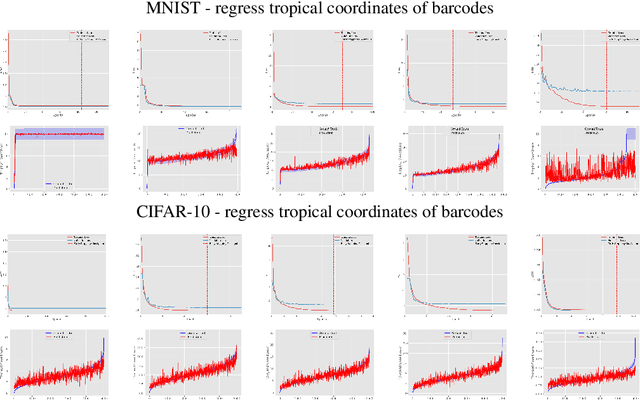
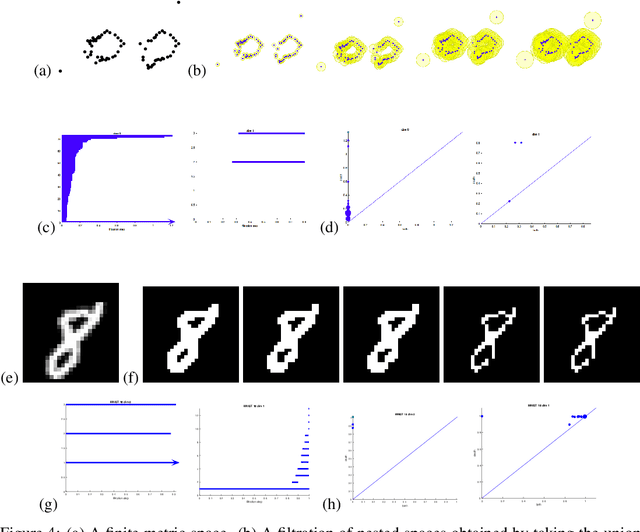
Topological data analysis uses tools from topology -- the mathematical area that studies shapes -- to create representations of data. In particular, in persistent homology, one studies one-parameter families of spaces associated with data, and persistence diagrams describe the lifetime of topological invariants, such as connected components or holes, across the one-parameter family. In many applications, one is interested in working with features associated with persistence diagrams rather than the diagrams themselves. In our work, we explore the possibility of learning several types of features extracted from persistence diagrams using neural networks.
PAN: Path Integral Based Convolution for Deep Graph Neural Networks
Apr 24, 2019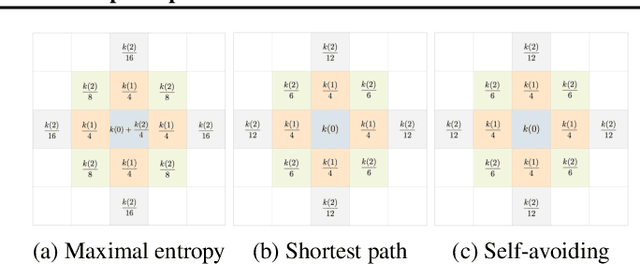
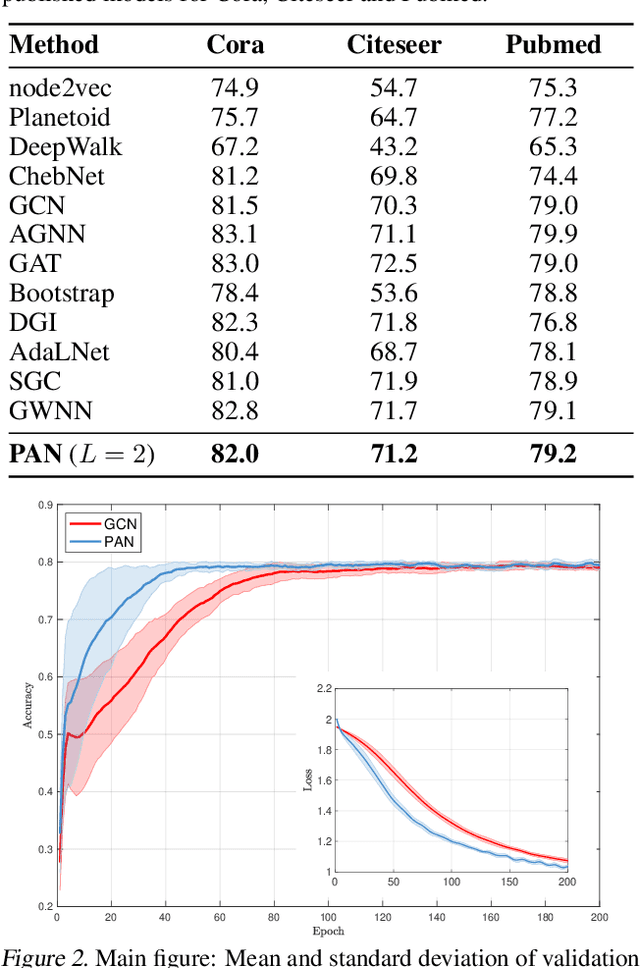
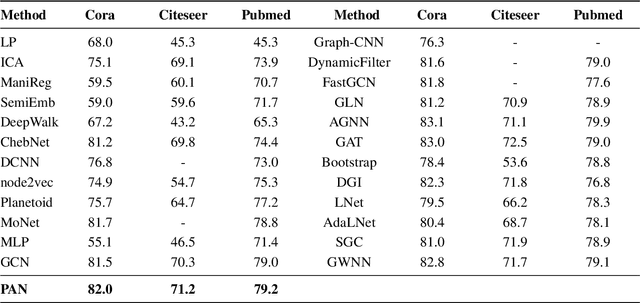
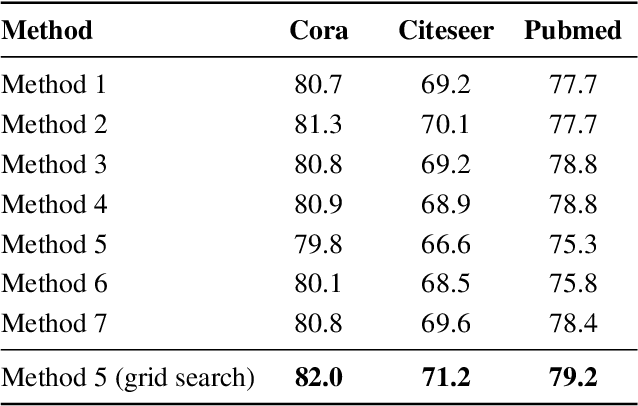
Convolution operations designed for graph-structured data usually utilize the graph Laplacian, which can be seen as message passing between the adjacent neighbors through a generic random walk. In this paper, we propose PAN, a new graph convolution framework that involves every path linking the message sender and receiver with learnable weights depending on the path length, which corresponds to the maximal entropy random walk. PAN generalizes the graph Laplacian to a new transition matrix we call \emph{maximal entropy transition} (MET) matrix derived from a path integral formalism. Most previous graph convolutional network architectures can be adapted to our framework, and many variations and derivatives based on the path integral idea can be developed. Experimental results show that the path integral based graph neural networks have great learnability and fast convergence rate, and achieve state-of-the-art performance on benchmark tasks.
A study on effectiveness of extreme learning machine
Sep 13, 2014
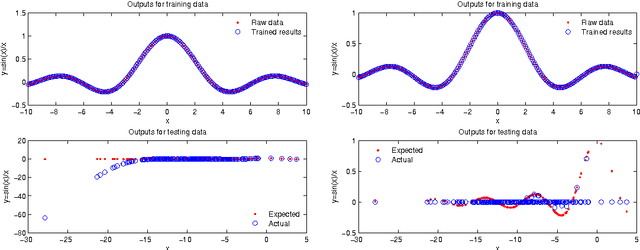
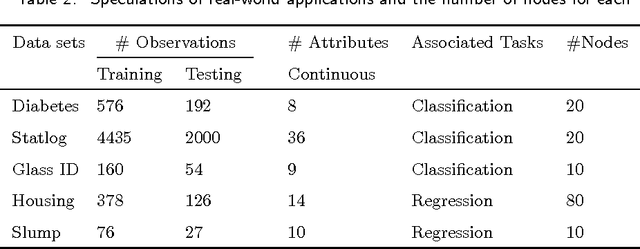
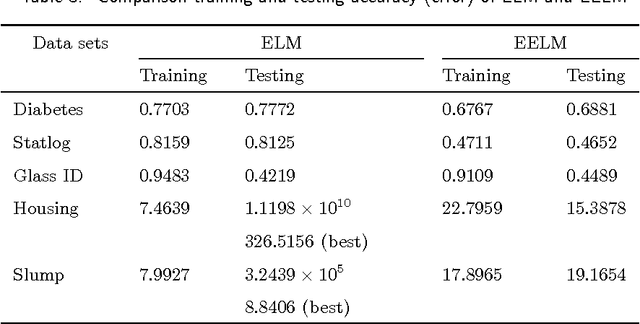
Extreme learning machine (ELM), proposed by Huang et al., has been shown a promising learning algorithm for single-hidden layer feedforward neural networks (SLFNs). Nevertheless, because of the random choice of input weights and biases, the ELM algorithm sometimes makes the hidden layer output matrix H of SLFN not full column rank, which lowers the effectiveness of ELM. This paper discusses the effectiveness of ELM and proposes an improved algorithm called EELM that makes a proper selection of the input weights and bias before calculating the output weights, which ensures the full column rank of H in theory. This improves to some extend the learning rate (testing accuracy, prediction accuracy, learning time) and the robustness property of the networks. The experimental results based on both the benchmark function approximation and real-world problems including classification and regression applications show the good performances of EELM.