 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFengyu Zhang
Multimodal Fusion with Pre-Trained Model Features in Affective Behaviour Analysis In-the-wild
Mar 22, 2024
Multimodal fusion is a significant method for most multimodal tasks. With the recent surge in the number of large pre-trained models, combining both multimodal fusion methods and pre-trained model features can achieve outstanding performance in many multimodal tasks. In this paper, we present our approach, which leverages both advantages for addressing the task of Expression (Expr) Recognition and Valence-Arousal (VA) Estimation. We evaluate the Aff-Wild2 database using pre-trained models, then extract the final hidden layers of the models as features. Following preprocessing and interpolation or convolution to align the extracted features, different models are employed for modal fusion. Our code is available at GitHub - FulgenceWen/ABAW6th.
LiRank: Industrial Large Scale Ranking Models at LinkedIn
Feb 10, 2024We present LiRank, a large-scale ranking framework at LinkedIn that brings to production state-of-the-art modeling architectures and optimization methods. We unveil several modeling improvements, including Residual DCN, which adds attention and residual connections to the famous DCNv2 architecture. We share insights into combining and tuning SOTA architectures to create a unified model, including Dense Gating, Transformers and Residual DCN. We also propose novel techniques for calibration and describe how we productionalized deep learning based explore/exploit methods. To enable effective, production-grade serving of large ranking models, we detail how to train and compress models using quantization and vocabulary compression. We provide details about the deployment setup for large-scale use cases of Feed ranking, Jobs Recommendations, and Ads click-through rate (CTR) prediction. We summarize our learnings from various A/B tests by elucidating the most effective technical approaches. These ideas have contributed to relative metrics improvements across the board at LinkedIn: +0.5% member sessions in the Feed, +1.76% qualified job applications for Jobs search and recommendations, and +4.3% for Ads CTR. We hope this work can provide practical insights and solutions for practitioners interested in leveraging large-scale deep ranking systems.
FsaNet: Frequency Self-attention for Semantic Segmentation
Nov 28, 2022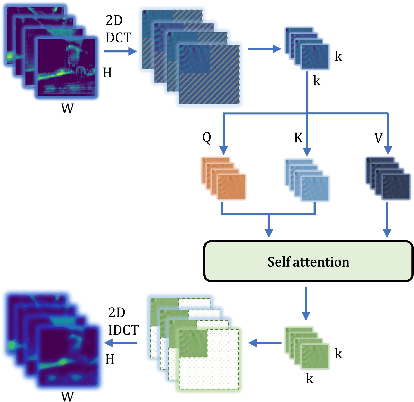
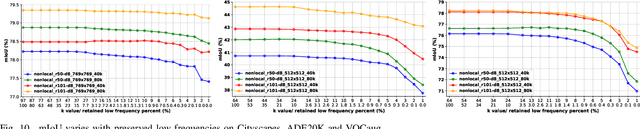
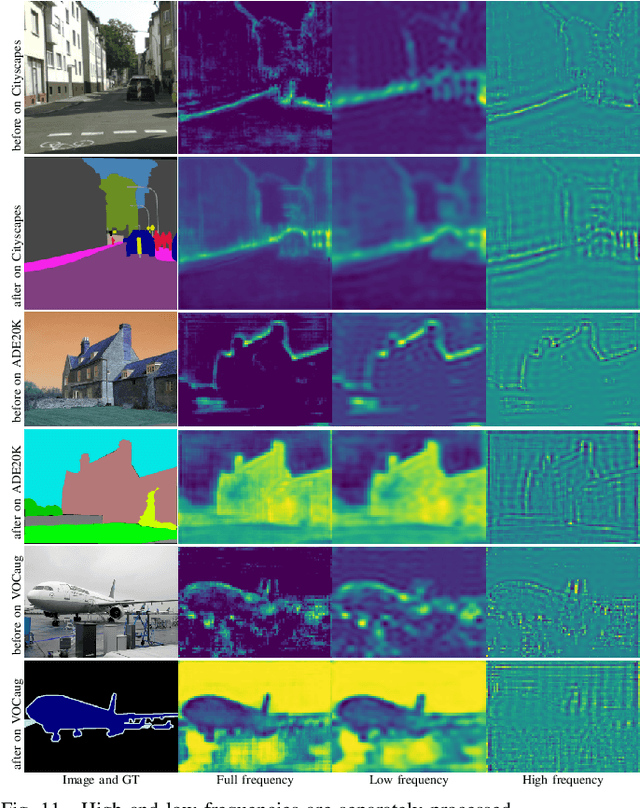

Considering the spectral properties of images, we propose a new self-attention mechanism with highly reduced computational complexity, up to a linear rate. To better preserve edges while promoting similarity within objects, we propose individualized processes over different frequency bands. In particular, we study a case where the process is merely over low-frequency components. By ablation study, we show that low frequency self-attention can achieve very close or better performance relative to full frequency even without retraining the network. Accordingly, we design and embed novel plug-and-play modules to the head of a CNN network that we refer to as FsaNet. The frequency self-attention 1) takes low frequency coefficients as input, 2) can be mathematically equivalent to spatial domain self-attention with linear structures, 3) simplifies token mapping ($1\times1$ convolution) stage and token mixing stage simultaneously. We show that the frequency self-attention requires $87.29\% \sim 90.04\%$ less memory, $96.13\% \sim 98.07\%$ less FLOPs, and $97.56\% \sim 98.18\%$ in run time than the regular self-attention. Compared to other ResNet101-based self-attention networks, FsaNet achieves a new state-of-the-art result ($83.0\%$ mIoU) on Cityscape test dataset and competitive results on ADE20k and VOCaug.