 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlorian Grötschla
CoRe-GD: A Hierarchical Framework for Scalable Graph Visualization with GNNs
Feb 09, 2024
Graph Visualization, also known as Graph Drawing, aims to find geometric embeddings of graphs that optimize certain criteria. Stress is a widely used metric; stress is minimized when every pair of nodes is positioned at their shortest path distance. However, stress optimization presents computational challenges due to its inherent complexity and is usually solved using heuristics in practice. We introduce a scalable Graph Neural Network (GNN) based Graph Drawing framework with sub-quadratic runtime that can learn to optimize stress. Inspired by classical stress optimization techniques and force-directed layout algorithms, we create a coarsening hierarchy for the input graph. Beginning at the coarsest level, we iteratively refine and un-coarsen the layout, until we generate an embedding for the original graph. To enhance information propagation within the network, we propose a novel positional rewiring technique based on intermediate node positions. Our empirical evaluation demonstrates that the framework achieves state-of-the-art performance while remaining scalable.
Decentralized Federated Policy Gradient with Byzantine Fault-Tolerance and Provably Fast Convergence
Jan 07, 2024In Federated Reinforcement Learning (FRL), agents aim to collaboratively learn a common task, while each agent is acting in its local environment without exchanging raw trajectories. Existing approaches for FRL either (a) do not provide any fault-tolerance guarantees (against misbehaving agents), or (b) rely on a trusted central agent (a single point of failure) for aggregating updates. We provide the first decentralized Byzantine fault-tolerant FRL method. Towards this end, we first propose a new centralized Byzantine fault-tolerant policy gradient (PG) algorithm that improves over existing methods by relying only on assumptions standard for non-fault-tolerant PG. Then, as our main contribution, we show how a combination of robust aggregation and Byzantine-resilient agreement methods can be leveraged in order to eliminate the need for a trusted central entity. Since our results represent the first sample complexity analysis for Byzantine fault-tolerant decentralized federated non-convex optimization, our technical contributions may be of independent interest. Finally, we corroborate our theoretical results experimentally for common RL environments, demonstrating the speed-up of decentralized federations w.r.t. the number of participating agents and resilience against various Byzantine attacks.
SURF: A Generalization Benchmark for GNNs Predicting Fluid Dynamics
Nov 20, 2023Simulating fluid dynamics is crucial for the design and development process, ranging from simple valves to complex turbomachinery. Accurately solving the underlying physical equations is computationally expensive. Therefore, learning-based solvers that model interactions on meshes have gained interest due to their promising speed-ups. However, it is unknown to what extent these models truly understand the underlying physical principles and can generalize rather than interpolate. Generalization is a key requirement for a general-purpose fluid simulator, which should adapt to different topologies, resolutions, or thermodynamic ranges. We propose SURF, a benchmark designed to test the $\textit{generalization}$ of learned graph-based fluid simulators. SURF comprises individual datasets and provides specific performance and generalization metrics for evaluating and comparing different models. We empirically demonstrate the applicability of SURF by thoroughly investigating the two state-of-the-art graph-based models, yielding new insights into their generalization.
Flood and Echo: Algorithmic Alignment of GNNs with Distributed Computing
Oct 12, 2023Graph Neural Networks are a natural fit for learning algorithms. They can directly represent tasks through an abstract but versatile graph structure and handle inputs of different sizes. This opens up the possibility for scaling and extrapolation to larger graphs, one of the most important advantages of an algorithm. However, this raises two core questions i) How can we enable nodes to gather the required information in a given graph ($\textit{information exchange}$), even if is far away and ii) How can we design an execution framework which enables this information exchange for extrapolation to larger graph sizes ($\textit{algorithmic alignment for extrapolation}$). We propose a new execution framework that is inspired by the design principles of distributed algorithms: Flood and Echo Net. It propagates messages through the entire graph in a wave like activation pattern, which naturally generalizes to larger instances. Through its sparse but parallel activations it is provably more efficient in terms of message complexity. We study the proposed model and provide both empirical evidence and theoretical insights in terms of its expressiveness, efficiency, information exchange and ability to extrapolate.
SALSA-CLRS: A Sparse and Scalable Benchmark for Algorithmic Reasoning
Sep 21, 2023We introduce an extension to the CLRS algorithmic learning benchmark, prioritizing scalability and the utilization of sparse representations. Many algorithms in CLRS require global memory or information exchange, mirrored in its execution model, which constructs fully connected (not sparse) graphs based on the underlying problem. Despite CLRS's aim of assessing how effectively learned algorithms can generalize to larger instances, the existing execution model becomes a significant constraint due to its demanding memory requirements and runtime (hard to scale). However, many important algorithms do not demand a fully connected graph; these algorithms, primarily distributed in nature, align closely with the message-passing paradigm employed by Graph Neural Networks. Hence, we propose SALSA-CLRS, an extension of the current CLRS benchmark specifically with scalability and sparseness in mind. Our approach includes adapted algorithms from the original CLRS benchmark and introduces new problems from distributed and randomized algorithms. Moreover, we perform a thorough empirical evaluation of our benchmark. Code is publicly available at https://github.com/jkminder/SALSA-CLRS.
Graphtester: Exploring Theoretical Boundaries of GNNs on Graph Datasets
Jun 30, 2023



Graph Neural Networks (GNNs) have emerged as a powerful tool for learning from graph-structured data. However, even state-of-the-art architectures have limitations on what structures they can distinguish, imposing theoretical limits on what the networks can achieve on different datasets. In this paper, we provide a new tool called Graphtester for a comprehensive analysis of the theoretical capabilities of GNNs for various datasets, tasks, and scores. We use Graphtester to analyze over 40 different graph datasets, determining upper bounds on the performance of various GNNs based on the number of layers. Further, we show that the tool can also be used for Graph Transformers using positional node encodings, thereby expanding its scope. Finally, we demonstrate that features generated by Graphtester can be used for practical applications such as Graph Transformers, and provide a synthetic dataset to benchmark node and edge features, such as positional encodings. The package is freely available at the following URL: https://github.com/meakbiyik/graphtester.
DISCO-10M: A Large-Scale Music Dataset
Jun 23, 2023



Music datasets play a crucial role in advancing research in machine learning for music. However, existing music datasets suffer from limited size, accessibility, and lack of audio resources. To address these shortcomings, we present DISCO-10M, a novel and extensive music dataset that surpasses the largest previously available music dataset by an order of magnitude. To ensure high-quality data, we implement a multi-stage filtering process. This process incorporates similarities based on textual descriptions and audio embeddings. Moreover, we provide precomputed CLAP embeddings alongside DISCO-10M, facilitating direct application on various downstream tasks. These embeddings enable efficient exploration of machine learning applications on the provided data. With DISCO-10M, we aim to democratize and facilitate new research to help advance the development of novel machine learning models for music.
Traffic4cast at NeurIPS 2022 -- Predict Dynamics along Graph Edges from Sparse Node Data: Whole City Traffic and ETA from Stationary Vehicle Detectors
Mar 14, 2023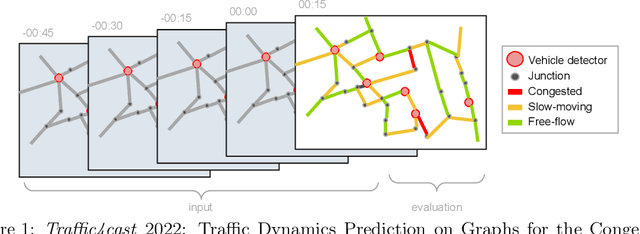
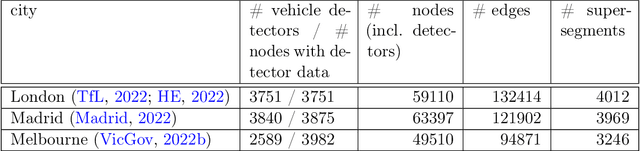
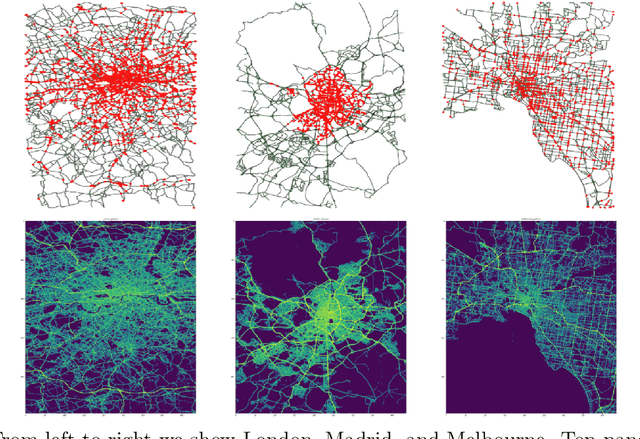
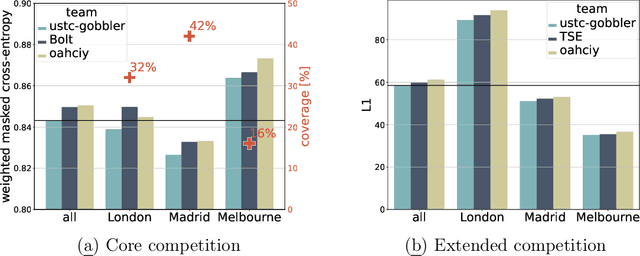
The global trends of urbanization and increased personal mobility force us to rethink the way we live and use urban space. The Traffic4cast competition series tackles this problem in a data-driven way, advancing the latest methods in machine learning for modeling complex spatial systems over time. In this edition, our dynamic road graph data combine information from road maps, $10^{12}$ probe data points, and stationary vehicle detectors in three cities over the span of two years. While stationary vehicle detectors are the most accurate way to capture traffic volume, they are only available in few locations. Traffic4cast 2022 explores models that have the ability to generalize loosely related temporal vertex data on just a few nodes to predict dynamic future traffic states on the edges of the entire road graph. In the core challenge, participants are invited to predict the likelihoods of three congestion classes derived from the speed levels in the GPS data for the entire road graph in three cities 15 min into the future. We only provide vehicle count data from spatially sparse stationary vehicle detectors in these three cities as model input for this task. The data are aggregated in 15 min time bins for one hour prior to the prediction time. For the extended challenge, participants are tasked to predict the average travel times on super-segments 15 min into the future - super-segments are longer sequences of road segments in the graph. The competition results provide an important advance in the prediction of complex city-wide traffic states just from publicly available sparse vehicle data and without the need for large amounts of real-time floating vehicle data.
Learning Graph Algorithms With Recurrent Graph Neural Networks
Dec 09, 2022



Classical graph algorithms work well for combinatorial problems that can be thoroughly formalized and abstracted. Once the algorithm is derived, it generalizes to instances of any size. However, developing an algorithm that handles complex structures and interactions in the real world can be challenging. Rather than specifying the algorithm, we can try to learn it from the graph-structured data. Graph Neural Networks (GNNs) are inherently capable of working on graph structures; however, they struggle to generalize well, and learning on larger instances is challenging. In order to scale, we focus on a recurrent architecture design that can learn simple graph problems end to end on smaller graphs and then extrapolate to larger instances. As our main contribution, we identify three essential techniques for recurrent GNNs to scale. By using (i) skip connections, (ii) state regularization, and (iii) edge convolutions, we can guide GNNs toward extrapolation. This allows us to train on small graphs and apply the same model to much larger graphs during inference. Moreover, we empirically validate the extrapolation capabilities of our GNNs on algorithmic datasets.
Hierarchical Graph Structures for Congestion and ETA Prediction
Nov 21, 2022



Traffic4cast is an annual competition to predict spatio temporal traffic based on real world data. We propose an approach using Graph Neural Networks that directly works on the road graph topology which was extracted from OpenStreetMap data. Our architecture can incorporate a hierarchical graph representation to improve the information flow between key intersections of the graph and the shortest paths connecting them. Furthermore, we investigate how the road graph can be compacted to ease the flow of information and make use of a multi-task approach to predict congestion classes and ETA simultaneously. Our code and models are released here: https://github.com/floriangroetschla/NeurIPS2022-traffic4cast