 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLuca A. Lanzendörfer
CAESAR: Enhancing Federated RL in Heterogeneous MDPs through Convergence-Aware Sampling with Screening
Mar 29, 2024
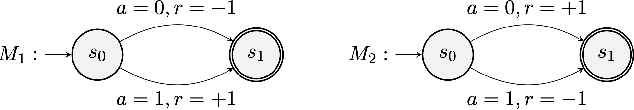


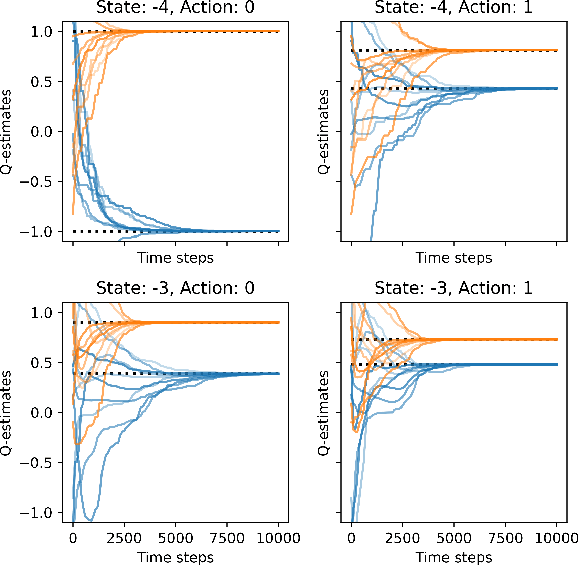
In this study, we delve into Federated Reinforcement Learning (FedRL) in the context of value-based agents operating across diverse Markov Decision Processes (MDPs). Existing FedRL methods typically aggregate agents' learning by averaging the value functions across them to improve their performance. However, this aggregation strategy is suboptimal in heterogeneous environments where agents converge to diverse optimal value functions. To address this problem, we introduce the Convergence-AwarE SAmpling with scReening (CAESAR) aggregation scheme designed to enhance the learning of individual agents across varied MDPs. CAESAR is an aggregation strategy used by the server that combines convergence-aware sampling with a screening mechanism. By exploiting the fact that agents learning in identical MDPs are converging to the same optimal value function, CAESAR enables the selective assimilation of knowledge from more proficient counterparts, thereby significantly enhancing the overall learning efficiency. We empirically validate our hypothesis and demonstrate the effectiveness of CAESAR in enhancing the learning efficiency of agents, using both a custom-built GridWorld environment and the classical FrozenLake-v1 task, each presenting varying levels of environmental heterogeneity.
DISCO-10M: A Large-Scale Music Dataset
Jun 23, 2023



Music datasets play a crucial role in advancing research in machine learning for music. However, existing music datasets suffer from limited size, accessibility, and lack of audio resources. To address these shortcomings, we present DISCO-10M, a novel and extensive music dataset that surpasses the largest previously available music dataset by an order of magnitude. To ensure high-quality data, we implement a multi-stage filtering process. This process incorporates similarities based on textual descriptions and audio embeddings. Moreover, we provide precomputed CLAP embeddings alongside DISCO-10M, facilitating direct application on various downstream tasks. These embeddings enable efficient exploration of machine learning applications on the provided data. With DISCO-10M, we aim to democratize and facilitate new research to help advance the development of novel machine learning models for music.
Siamese SIREN: Audio Compression with Implicit Neural Representations
Jun 22, 2023



Implicit Neural Representations (INRs) have emerged as a promising method for representing diverse data modalities, including 3D shapes, images, and audio. While recent research has demonstrated successful applications of INRs in image and 3D shape compression, their potential for audio compression remains largely unexplored. Motivated by this, we present a preliminary investigation into the use of INRs for audio compression. Our study introduces Siamese SIREN, a novel approach based on the popular SIREN architecture. Our experimental results indicate that Siamese SIREN achieves superior audio reconstruction fidelity while utilizing fewer network parameters compared to previous INR architectures.
Examining the Emergence of Deductive Reasoning in Generative Language Models
May 31, 2023



We conduct a preliminary inquiry into the ability of generative transformer models to deductively reason from premises provided. We observe notable differences in the performance of models coming from different training setups and find that the deductive reasoning ability increases with scale. Further, we discover that the performance generally does not decrease with the length of the deductive chain needed to reach the conclusion, with the exception of OpenAI GPT-3 and GPT-3.5 models. Our study considers a wide variety of transformer-decoder models, ranging from 117 million to 175 billion parameters in size.