 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrank F. Xu
WebArena: A Realistic Web Environment for Building Autonomous Agents
Jul 25, 2023
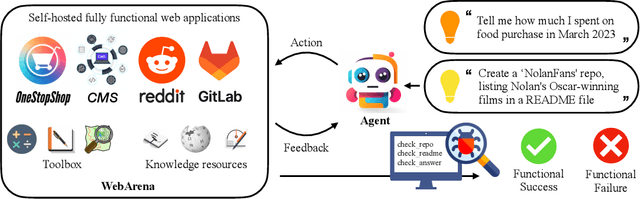

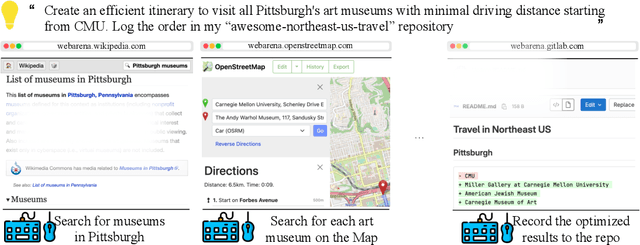

With generative AI advances, the exciting potential for autonomous agents to manage daily tasks via natural language commands has emerged. However, cur rent agents are primarily created and tested in simplified synthetic environments, substantially limiting real-world scenario representation. In this paper, we build an environment for agent command and control that is highly realistic and reproducible. Specifically, we focus on agents that perform tasks on websites, and we create an environment with fully functional websites from four common domains: e-commerce, social forum discussions, collaborative software development, and content management. Our environment is enriched with tools (e.g., a map) and external knowledge bases (e.g., user manuals) to encourage human-like task-solving. Building upon our environment, we release a set of benchmark tasks focusing on evaluating the functional correctness of task completions. The tasks in our benchmark are diverse, long-horizon, and are designed to emulate tasks that humans routinely perform on the internet. We design and implement several autonomous agents, integrating recent techniques such as reasoning before acting. The results demonstrate that solving complex tasks is challenging: our best GPT-4-based agent only achieves an end-to-end task success rate of 10.59%. These results highlight the need for further development of robust agents, that current state-of-the-art LMs are far from perfect performance in these real-life tasks, and that WebArena can be used to measure such progress. Our code, data, environment reproduction resources, and video demonstrations are publicly available at https://webarena.dev/.
Hierarchical Prompting Assists Large Language Model on Web Navigation
May 23, 2023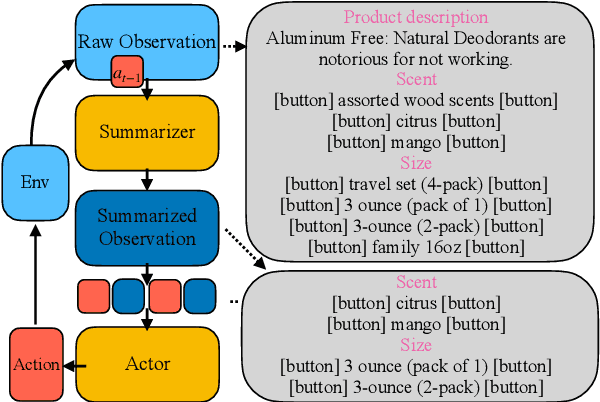


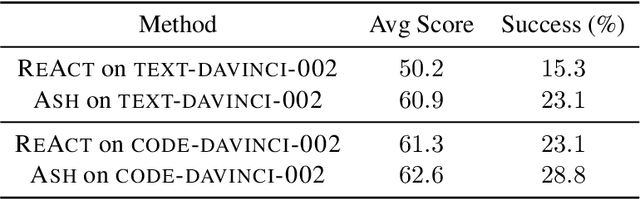
Large language models (LLMs) struggle on processing complicated observations in interactive decision making. To alleviate this issue, we propose a simple hierarchical prompting approach. Diverging from previous prompting approaches that always put the \emph{full} observation~(\eg a web page) to the prompt, we propose to first construct an action-aware observation which is more \emph{condensed} and \emph{relevant} with a dedicated \summ prompt. The \actor prompt then predicts the next action based on the summarized history. While our method has broad applicability, we particularly demonstrate its efficacy in the complex domain of web navigation where a full observation often contains redundant and irrelevant information. Our approach outperforms the previous state-of-the-art prompting mechanism with the same LLM by 6.2\% on task success rate, demonstrating its potential on interactive decision making tasks with long observation traces.
Active Retrieval Augmented Generation
May 11, 2023

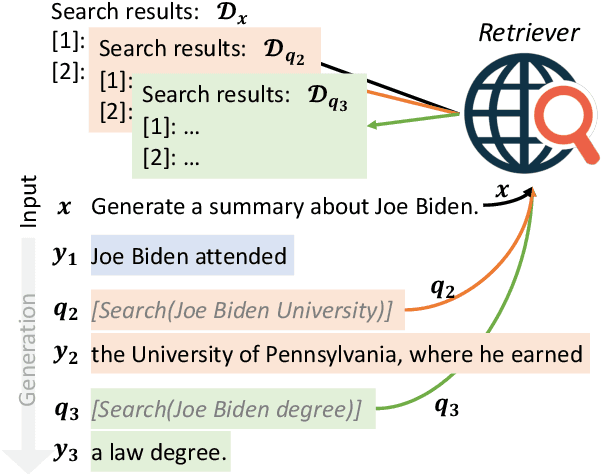
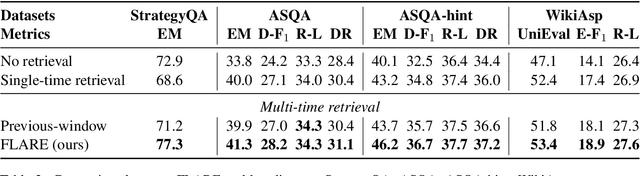
Despite the remarkable ability of large language models (LMs) to comprehend and generate language, they have a tendency to hallucinate and create factually inaccurate output. Augmenting LMs by retrieving information from external knowledge resources is one promising solution. Most existing retrieval-augmented LMs employ a retrieve-and-generate setup that only retrieves information once based on the input. This is limiting, however, in more general scenarios involving generation of long texts, where continually gathering information throughout the generation process is essential. There have been some past efforts to retrieve information multiple times while generating outputs, which mostly retrieve documents at fixed intervals using the previous context as queries. In this work, we provide a generalized view of active retrieval augmented generation, methods that actively decide when and what to retrieve across the course of the generation. We propose Forward-Looking Active REtrieval augmented generation (FLARE), a generic retrieval-augmented generation method which iteratively uses a prediction of the upcoming sentence to anticipate future content, which is then utilized as a query to retrieve relevant documents to regenerate the sentence if it contains low-confidence tokens. We test FLARE along with baselines comprehensively over 4 long-form knowledge-intensive generation tasks/datasets. FLARE achieves superior or competitive performance on all tasks, demonstrating the effectiveness of our method. Code and datasets are available at https://github.com/jzbjyb/FLARE.
Why do Nearest Neighbor Language Models Work?
Jan 17, 2023



Language models (LMs) compute the probability of a text by sequentially computing a representation of an already-seen context and using this representation to predict the next word. Currently, most LMs calculate these representations through a neural network consuming the immediate previous context. However recently, retrieval-augmented LMs have shown to improve over standard neural LMs, by accessing information retrieved from a large datastore, in addition to their standard, parametric, next-word prediction. In this paper, we set out to understand why retrieval-augmented language models, and specifically why k-nearest neighbor language models (kNN-LMs) perform better than standard parametric LMs, even when the k-nearest neighbor component retrieves examples from the same training set that the LM was originally trained on. To this end, we perform a careful analysis of the various dimensions over which kNN-LM diverges from standard LMs, and investigate these dimensions one by one. Empirically, we identify three main reasons why kNN-LM performs better than standard LMs: using a different input representation for predicting the next tokens, approximate kNN search, and the importance of softmax temperature for the kNN distribution. Further, we incorporate these insights into the model architecture or the training procedure of the standard parametric LM, improving its results without the need for an explicit retrieval component. The code is available at https://github.com/frankxu2004/knnlm-why.
DocCoder: Generating Code by Retrieving and Reading Docs
Jul 13, 2022



Natural-language-to-code models learn to generate a code snippet given a natural language (NL) intent. However, the rapid growth of both publicly available and proprietary libraries and functions makes it impossible to cover all APIs using training examples, as new libraries and functions are introduced daily. Thus, existing models inherently cannot generalize to using unseen functions and libraries merely through incorporating them into the training data. In contrast, when human programmers write programs, they frequently refer to textual resources such as code manuals, documentation, and tutorials, to explore and understand available library functionality. Inspired by this observation, we introduce DocCoder: an approach that explicitly leverages code manuals and documentation by (1) retrieving the relevant documentation given the NL intent, and (2) generating the code based on the NL intent and the retrieved documentation. Our approach is general, can be applied to any programming language, and is agnostic to the underlying neural model. We demonstrate that DocCoder consistently improves NL-to-code models: DocCoder achieves 11x higher exact match accuracy than strong baselines on a new Bash dataset tldr; on the popular Python CoNaLa benchmark, DocCoder improves over strong baselines by 1.65 BLEU.
MCoNaLa: A Benchmark for Code Generation from Multiple Natural Languages
Mar 16, 2022



While there has been a recent burgeoning of applications at the intersection of natural and programming languages, such as code generation and code summarization, these applications are usually English-centric. This creates a barrier for program developers who are not proficient in English. To mitigate this gap in technology development across languages, we propose a multilingual dataset, MCoNaLa, to benchmark code generation from natural language commands extending beyond English. Modeled off of the methodology from the English Code/Natural Language Challenge (CoNaLa) dataset, we annotated a total of 896 NL-code pairs in three languages: Spanish, Japanese, and Russian. We present a quantitative evaluation of performance on the MCoNaLa dataset by testing with state-of-the-art code generation systems. While the difficulties vary across these three languages, all systems lag significantly behind their English counterparts, revealing the challenges in adapting code generation to new languages.
A Systematic Evaluation of Large Language Models of Code
Mar 01, 2022



Large language models (LMs) of code have recently shown tremendous promise in completing code and synthesizing code from natural language descriptions. However, the current state-of-the-art code LMs (e.g., Codex (Chen et al., 2021)) are not publicly available, leaving many questions about their model and data design decisions. We aim to fill in some of these blanks through a systematic evaluation of the largest existing models: Codex, GPT-J, GPT-Neo, GPT-NeoX-20B, and CodeParrot, across various programming languages. Although Codex itself is not open-source, we find that existing open-source models do achieve close results in some programming languages, although targeted mainly for natural language modeling. We further identify an important missing piece in the form of a large open-source model trained exclusively on a multi-lingual corpus of code. We release a new model, PolyCoder, with 2.7B parameters based on the GPT-2 architecture, which was trained on 249GB of code across 12 programming languages on a single machine. In the C programming language, PolyCoder outperforms all models including Codex. Our trained models are open-source and publicly available at https://github.com/VHellendoorn/Code-LMs, which enables future research and application in this area.
Neuro-Symbolic Language Modeling with Automaton-augmented Retrieval
Jan 28, 2022



Retrieval-based language models (R-LM) model the probability of natural language text by combining a standard language model (LM) with examples retrieved from an external datastore at test time. While effective, a major bottleneck of using these models in practice is the computationally costly datastore search, which can be performed as frequently as every time step. In this paper, we present RetoMaton -- retrieval automaton -- which approximates the datastore search, based on (1) clustering of entries into "states", and (2) state transitions from previous entries. This effectively results in a weighted finite automaton built on top of the datastore, instead of representing the datastore as a flat list. The creation of the automaton is unsupervised, and a RetoMaton can be constructed from any text collection: either the original training corpus or from another domain. Traversing this automaton at inference time, in parallel to the LM inference, reduces its perplexity, or alternatively saves up to 83% of the nearest neighbor searches over kNN-LM (Khandelwal et al., 2020), without hurting perplexity.
Capturing Structural Locality in Non-parametric Language Models
Oct 06, 2021



Structural locality is a ubiquitous feature of real-world datasets, wherein data points are organized into local hierarchies. Some examples include topical clusters in text or project hierarchies in source code repositories. In this paper, we explore utilizing this structural locality within non-parametric language models, which generate sequences that reference retrieved examples from an external source. We propose a simple yet effective approach for adding locality information into such models by adding learned parameters that improve the likelihood of retrieving examples from local neighborhoods. Experiments on two different domains, Java source code and Wikipedia text, demonstrate that locality features improve model efficacy over models without access to these features, with interesting differences. We also perform an analysis of how and where locality features contribute to improved performance and why the traditionally used contextual similarity metrics alone are not enough to grasp the locality structure.
Learning Structural Edits via Incremental Tree Transformations
Jan 28, 2021



While most neural generative models generate outputs in a single pass, the human creative process is usually one of iterative building and refinement. Recent work has proposed models of editing processes, but these mostly focus on editing sequential data and/or only model a single editing pass. In this paper, we present a generic model for incremental editing of structured data (i.e., "structural edits"). Particularly, we focus on tree-structured data, taking abstract syntax trees of computer programs as our canonical example. Our editor learns to iteratively generate tree edits (e.g., deleting or adding a subtree) and applies them to the partially edited data, thereby the entire editing process can be formulated as consecutive, incremental tree transformations. To show the unique benefits of modeling tree edits directly, we further propose a novel edit encoder for learning to represent edits, as well as an imitation learning method that allows the editor to be more robust. We evaluate our proposed editor on two source code edit datasets, where results show that, with the proposed edit encoder, our editor significantly improves accuracy over previous approaches that generate the edited program directly in one pass. Finally, we demonstrate that training our editor to imitate experts and correct its mistakes dynamically can further improve its performance.