 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHao Zhu
STAG4D: Spatial-Temporal Anchored Generative 4D Gaussians
Mar 22, 2024
Recent progress in pre-trained diffusion models and 3D generation have spurred interest in 4D content creation. However, achieving high-fidelity 4D generation with spatial-temporal consistency remains a challenge. In this work, we propose STAG4D, a novel framework that combines pre-trained diffusion models with dynamic 3D Gaussian splatting for high-fidelity 4D generation. Drawing inspiration from 3D generation techniques, we utilize a multi-view diffusion model to initialize multi-view images anchoring on the input video frames, where the video can be either real-world captured or generated by a video diffusion model. To ensure the temporal consistency of the multi-view sequence initialization, we introduce a simple yet effective fusion strategy to leverage the first frame as a temporal anchor in the self-attention computation. With the almost consistent multi-view sequences, we then apply the score distillation sampling to optimize the 4D Gaussian point cloud. The 4D Gaussian spatting is specially crafted for the generation task, where an adaptive densification strategy is proposed to mitigate the unstable Gaussian gradient for robust optimization. Notably, the proposed pipeline does not require any pre-training or fine-tuning of diffusion networks, offering a more accessible and practical solution for the 4D generation task. Extensive experiments demonstrate that our method outperforms prior 4D generation works in rendering quality, spatial-temporal consistency, and generation robustness, setting a new state-of-the-art for 4D generation from diverse inputs, including text, image, and video.
Champ: Controllable and Consistent Human Image Animation with 3D Parametric Guidance
Mar 21, 2024In this study, we introduce a methodology for human image animation by leveraging a 3D human parametric model within a latent diffusion framework to enhance shape alignment and motion guidance in curernt human generative techniques. The methodology utilizes the SMPL(Skinned Multi-Person Linear) model as the 3D human parametric model to establish a unified representation of body shape and pose. This facilitates the accurate capture of intricate human geometry and motion characteristics from source videos. Specifically, we incorporate rendered depth images, normal maps, and semantic maps obtained from SMPL sequences, alongside skeleton-based motion guidance, to enrich the conditions to the latent diffusion model with comprehensive 3D shape and detailed pose attributes. A multi-layer motion fusion module, integrating self-attention mechanisms, is employed to fuse the shape and motion latent representations in the spatial domain. By representing the 3D human parametric model as the motion guidance, we can perform parametric shape alignment of the human body between the reference image and the source video motion. Experimental evaluations conducted on benchmark datasets demonstrate the methodology's superior ability to generate high-quality human animations that accurately capture both pose and shape variations. Furthermore, our approach also exhibits superior generalization capabilities on the proposed wild dataset. Project page: https://fudan-generative-vision.github.io/champ.
What Are Tools Anyway? A Survey from the Language Model Perspective
Mar 18, 2024Language models (LMs) are powerful yet mostly for text generation tasks. Tools have substantially enhanced their performance for tasks that require complex skills. However, many works adopt the term "tool" in different ways, raising the question: What is a tool anyway? Subsequently, where and how do tools help LMs? In this survey, we provide a unified definition of tools as external programs used by LMs, and perform a systematic review of LM tooling scenarios and approaches. Grounded on this review, we empirically study the efficiency of various tooling methods by measuring their required compute and performance gains on various benchmarks, and highlight some challenges and potential future research in the field.
SOTOPIA-$π$: Interactive Learning of Socially Intelligent Language Agents
Mar 14, 2024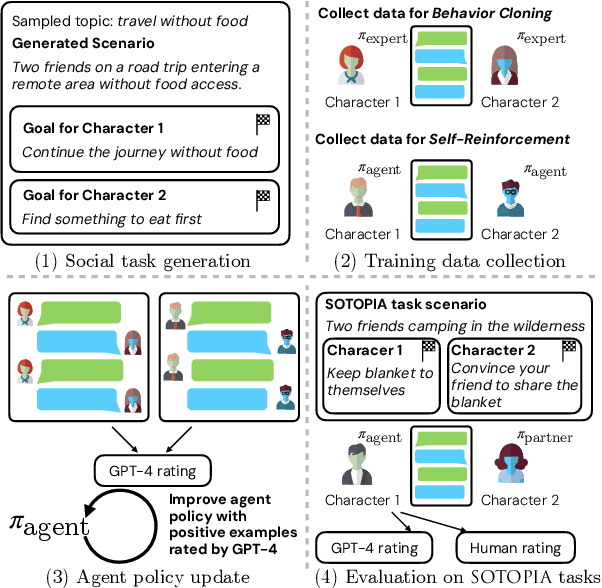

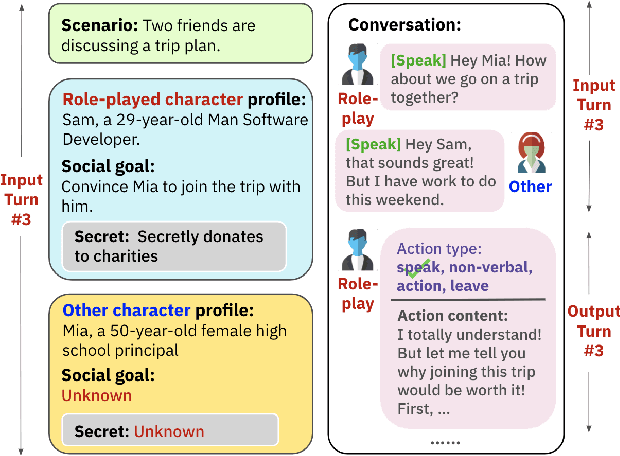
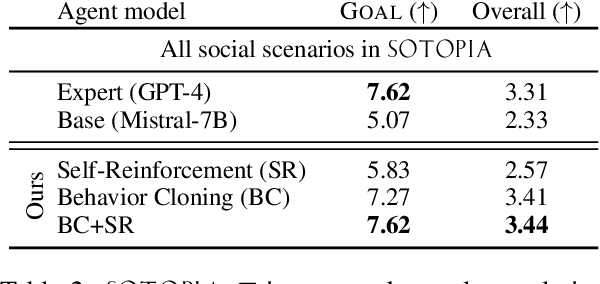
Humans learn social skills through both imitation and social interaction. This social learning process is largely understudied by existing research on building language agents. Motivated by this gap, we propose an interactive learning method, SOTOPIA-$\pi$, improving the social intelligence of language agents. This method leverages behavior cloning and self-reinforcement training on filtered social interaction data according to large language model (LLM) ratings. We show that our training method allows a 7B LLM to reach the social goal completion ability of an expert model (GPT-4-based agent), while improving the safety of language agents and maintaining general QA ability on the MMLU benchmark. We also find that this training paradigm uncovers some difficulties in LLM-based evaluation of social intelligence: LLM-based evaluators overestimate the abilities of the language agents trained specifically for social interaction.
DevEval: Evaluating Code Generation in Practical Software Projects
Jan 26, 2024How to evaluate Large Language Models (LLMs) in code generation is an open question. Many benchmarks have been proposed but are inconsistent with practical software projects, e.g., unreal program distributions, insufficient dependencies, and small-scale project contexts. Thus, the capabilities of LLMs in practical projects are still unclear. In this paper, we propose a new benchmark named DevEval, aligned with Developers' experiences in practical projects. DevEval is collected through a rigorous pipeline, containing 2,690 samples from 119 practical projects and covering 10 domains. Compared to previous benchmarks, DevEval aligns to practical projects in multiple dimensions, e.g., real program distributions, sufficient dependencies, and enough-scale project contexts. We assess five popular LLMs on DevEval (e.g., gpt-4, gpt-3.5-turbo, CodeLLaMa, and StarCoder) and reveal their actual abilities in code generation. For instance, the highest Pass@1 of gpt-3.5-turbo only is 42 in our experiments. We also discuss the challenges and future directions of code generation in practical projects. We open-source DevEval and hope it can facilitate the development of code generation in practical projects.
VividTalk: One-Shot Audio-Driven Talking Head Generation Based on 3D Hybrid Prior
Dec 07, 2023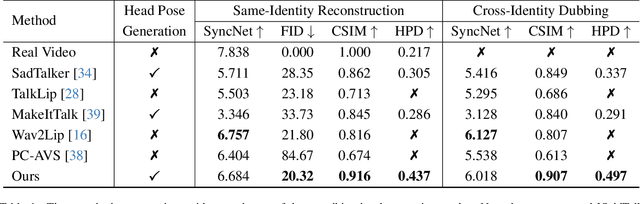
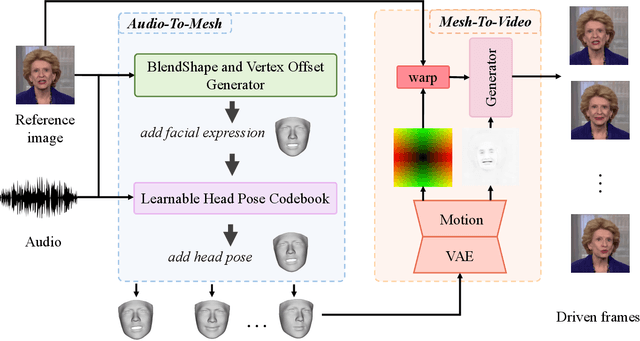
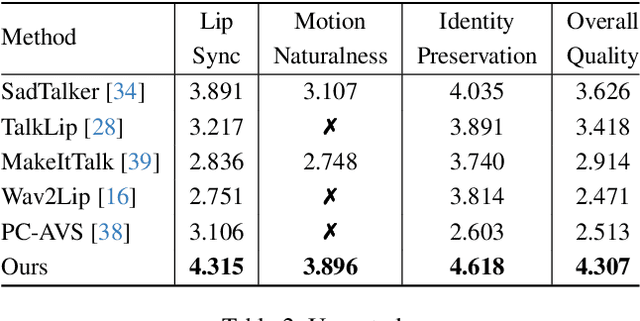
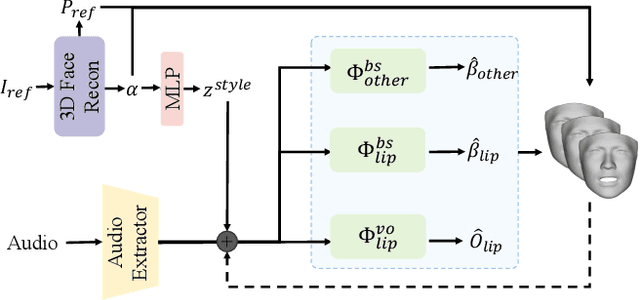
Audio-driven talking head generation has drawn much attention in recent years, and many efforts have been made in lip-sync, expressive facial expressions, natural head pose generation, and high video quality. However, no model has yet led or tied on all these metrics due to the one-to-many mapping between audio and motion. In this paper, we propose VividTalk, a two-stage generic framework that supports generating high-visual quality talking head videos with all the above properties. Specifically, in the first stage, we map the audio to mesh by learning two motions, including non-rigid expression motion and rigid head motion. For expression motion, both blendshape and vertex are adopted as the intermediate representation to maximize the representation ability of the model. For natural head motion, a novel learnable head pose codebook with a two-phase training mechanism is proposed. In the second stage, we proposed a dual branch motion-vae and a generator to transform the meshes into dense motion and synthesize high-quality video frame-by-frame. Extensive experiments show that the proposed VividTalk can generate high-visual quality talking head videos with lip-sync and realistic enhanced by a large margin, and outperforms previous state-of-the-art works in objective and subjective comparisons.
FINER: Flexible spectral-bias tuning in Implicit NEural Representation by Variable-periodic Activation Functions
Dec 05, 2023Implicit Neural Representation (INR), which utilizes a neural network to map coordinate inputs to corresponding attributes, is causing a revolution in the field of signal processing. However, current INR techniques suffer from a restricted capability to tune their supported frequency set, resulting in imperfect performance when representing complex signals with multiple frequencies. We have identified that this frequency-related problem can be greatly alleviated by introducing variable-periodic activation functions, for which we propose FINER. By initializing the bias of the neural network within different ranges, sub-functions with various frequencies in the variable-periodic function are selected for activation. Consequently, the supported frequency set of FINER can be flexibly tuned, leading to improved performance in signal representation. We demonstrate the capabilities of FINER in the contexts of 2D image fitting, 3D signed distance field representation, and 5D neural radiance fields optimization, and we show that it outperforms existing INRs.
Relightable 3D Gaussian: Real-time Point Cloud Relighting with BRDF Decomposition and Ray Tracing
Nov 27, 2023We present a novel differentiable point-based rendering framework for material and lighting decomposition from multi-view images, enabling editing, ray-tracing, and real-time relighting of the 3D point cloud. Specifically, a 3D scene is represented as a set of relightable 3D Gaussian points, where each point is additionally associated with a normal direction, BRDF parameters, and incident lights from different directions. To achieve robust lighting estimation, we further divide incident lights of each point into global and local components, as well as view-dependent visibilities. The 3D scene is optimized through the 3D Gaussian Splatting technique while BRDF and lighting are decomposed by physically-based differentiable rendering. Moreover, we introduce an innovative point-based ray-tracing approach based on the bounding volume hierarchy for efficient visibility baking, enabling real-time rendering and relighting of 3D Gaussian points with accurate shadow effects. Extensive experiments demonstrate improved BRDF estimation and novel view rendering results compared to state-of-the-art material estimation approaches. Our framework showcases the potential to revolutionize the mesh-based graphics pipeline with a relightable, traceable, and editable rendering pipeline solely based on point cloud. Project page:https://nju-3dv.github.io/projects/Relightable3DGaussian/.