 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJian Gao
Hunting imaging biomarkers in pulmonary fibrosis: Benchmarks of the AIIB23 challenge
Dec 21, 2023
Airway-related quantitative imaging biomarkers are crucial for examination, diagnosis, and prognosis in pulmonary diseases. However, the manual delineation of airway trees remains prohibitively time-consuming. While significant efforts have been made towards enhancing airway modelling, current public-available datasets concentrate on lung diseases with moderate morphological variations. The intricate honeycombing patterns present in the lung tissues of fibrotic lung disease patients exacerbate the challenges, often leading to various prediction errors. To address this issue, the 'Airway-Informed Quantitative CT Imaging Biomarker for Fibrotic Lung Disease 2023' (AIIB23) competition was organized in conjunction with the official 2023 International Conference on Medical Image Computing and Computer Assisted Intervention (MICCAI). The airway structures were meticulously annotated by three experienced radiologists. Competitors were encouraged to develop automatic airway segmentation models with high robustness and generalization abilities, followed by exploring the most correlated QIB of mortality prediction. A training set of 120 high-resolution computerised tomography (HRCT) scans were publicly released with expert annotations and mortality status. The online validation set incorporated 52 HRCT scans from patients with fibrotic lung disease and the offline test set included 140 cases from fibrosis and COVID-19 patients. The results have shown that the capacity of extracting airway trees from patients with fibrotic lung disease could be enhanced by introducing voxel-wise weighted general union loss and continuity loss. In addition to the competitive image biomarkers for prognosis, a strong airway-derived biomarker (Hazard ratio>1.5, p<0.0001) was revealed for survival prognostication compared with existing clinical measurements, clinician assessment and AI-based biomarkers.
Relightable 3D Gaussian: Real-time Point Cloud Relighting with BRDF Decomposition and Ray Tracing
Nov 27, 2023We present a novel differentiable point-based rendering framework for material and lighting decomposition from multi-view images, enabling editing, ray-tracing, and real-time relighting of the 3D point cloud. Specifically, a 3D scene is represented as a set of relightable 3D Gaussian points, where each point is additionally associated with a normal direction, BRDF parameters, and incident lights from different directions. To achieve robust lighting estimation, we further divide incident lights of each point into global and local components, as well as view-dependent visibilities. The 3D scene is optimized through the 3D Gaussian Splatting technique while BRDF and lighting are decomposed by physically-based differentiable rendering. Moreover, we introduce an innovative point-based ray-tracing approach based on the bounding volume hierarchy for efficient visibility baking, enabling real-time rendering and relighting of 3D Gaussian points with accurate shadow effects. Extensive experiments demonstrate improved BRDF estimation and novel view rendering results compared to state-of-the-art material estimation approaches. Our framework showcases the potential to revolutionize the mesh-based graphics pipeline with a relightable, traceable, and editable rendering pipeline solely based on point cloud. Project page:https://nju-3dv.github.io/projects/Relightable3DGaussian/.
An Intelligent Social Learning-based Optimization Strategy for Black-box Robotic Control with Reinforcement Learning
Nov 11, 2023Implementing intelligent control of robots is a difficult task, especially when dealing with complex black-box systems, because of the lack of visibility and understanding of how these robots work internally. This paper proposes an Intelligent Social Learning (ISL) algorithm to enable intelligent control of black-box robotic systems. Inspired by mutual learning among individuals in human social groups, ISL includes learning, imitation, and self-study styles. Individuals in the learning style use the Levy flight search strategy to learn from the best performer and form the closest relationships. In the imitation style, individuals mimic the best performer with a second-level rapport by employing a random perturbation strategy. In the self-study style, individuals learn independently using a normal distribution sampling method while maintaining a distant relationship with the best performer. Individuals in the population are regarded as autonomous intelligent agents in each style. Neural networks perform strategic actions in three styles to interact with the environment and the robot and iteratively optimize the network policy. Overall, ISL builds on the principles of intelligent optimization, incorporating ideas from reinforcement learning, and possesses strong search capabilities, fast computation speed, fewer hyperparameters, and insensitivity to sparse rewards. The proposed ISL algorithm is compared with four state-of-the-art methods on six continuous control benchmark cases in MuJoCo to verify its effectiveness and advantages. Furthermore, ISL is adopted in the simulation and experimental grasping tasks of the UR3 robot for validations, and satisfactory solutions are yielded.
Human Transcription Quality Improvement
Sep 24, 2023
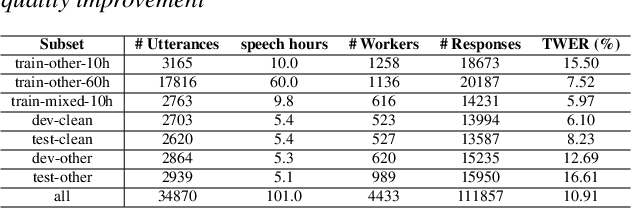
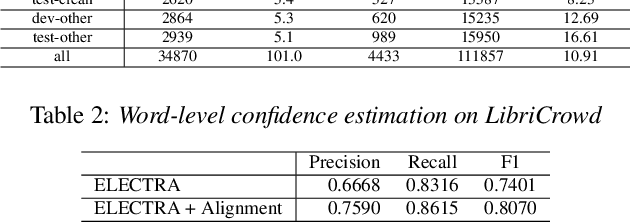
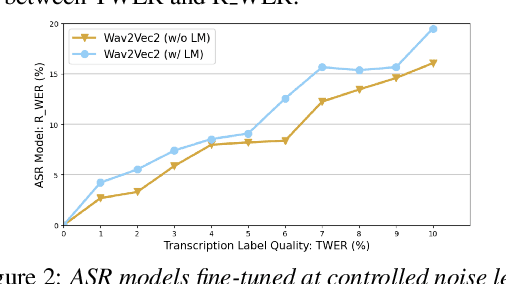
High quality transcription data is crucial for training automatic speech recognition (ASR) systems. However, the existing industry-level data collection pipelines are expensive to researchers, while the quality of crowdsourced transcription is low. In this paper, we propose a reliable method to collect speech transcriptions. We introduce two mechanisms to improve transcription quality: confidence estimation based reprocessing at labeling stage, and automatic word error correction at post-labeling stage. We collect and release LibriCrowd - a large-scale crowdsourced dataset of audio transcriptions on 100 hours of English speech. Experiment shows the Transcription WER is reduced by over 50%. We further investigate the impact of transcription error on ASR model performance and found a strong correlation. The transcription quality improvement provides over 10% relative WER reduction for ASR models. We release the dataset and code to benefit the research community.
* 5 pages, 3 figures, 5 tables, INTERSPEECH 2023
Human-AI Interactions and Societal Pitfalls
Sep 19, 2023
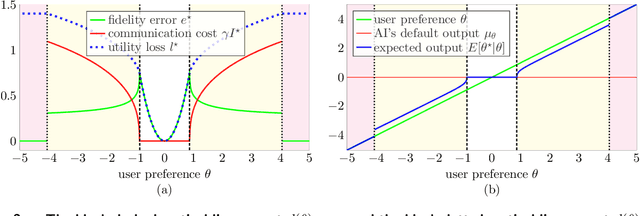
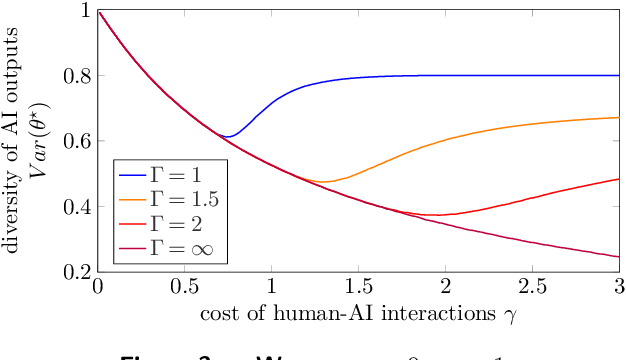
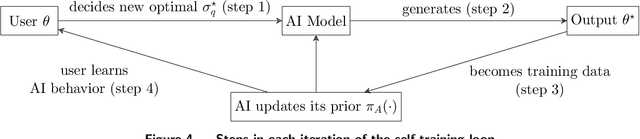
When working with generative artificial intelligence (AI), users may see productivity gains, but the AI-generated content may not match their preferences exactly. To study this effect, we introduce a Bayesian framework in which heterogeneous users choose how much information to share with the AI, facing a trade-off between output fidelity and communication cost. We show that the interplay between these individual-level decisions and AI training may lead to societal challenges. Outputs may become more homogenized, especially when the AI is trained on AI-generated content. And any AI bias may become societal bias. A solution to the homogenization and bias issues is to improve human-AI interactions, enabling personalized outputs without sacrificing productivity.
HTEC: Human Transcription Error Correction
Sep 18, 2023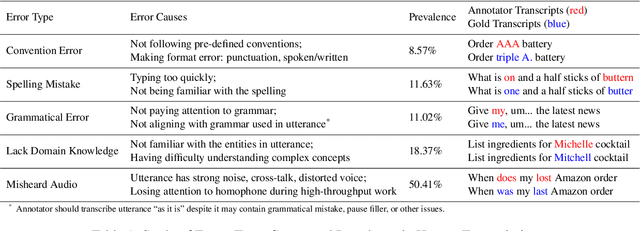
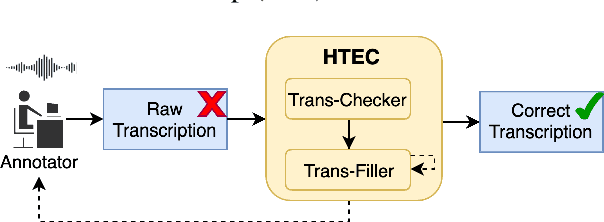

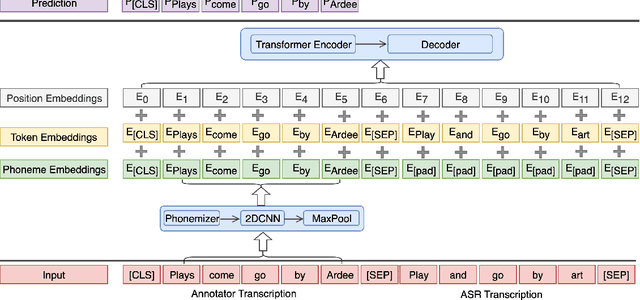
High-quality human transcription is essential for training and improving Automatic Speech Recognition (ASR) models. Recent study~\cite{libricrowd} has found that every 1% worse transcription Word Error Rate (WER) increases approximately 2% ASR WER by using the transcriptions to train ASR models. Transcription errors are inevitable for even highly-trained annotators. However, few studies have explored human transcription correction. Error correction methods for other problems, such as ASR error correction and grammatical error correction, do not perform sufficiently for this problem. Therefore, we propose HTEC for Human Transcription Error Correction. HTEC consists of two stages: Trans-Checker, an error detection model that predicts and masks erroneous words, and Trans-Filler, a sequence-to-sequence generative model that fills masked positions. We propose a holistic list of correction operations, including four novel operations handling deletion errors. We further propose a variant of embeddings that incorporates phoneme information into the input of the transformer. HTEC outperforms other methods by a large margin and surpasses human annotators by 2.2% to 4.5% in WER. Finally, we deployed HTEC to assist human annotators and showed HTEC is particularly effective as a co-pilot, which improves transcription quality by 15.1% without sacrificing transcription velocity.
Distributed UAV Swarm Augmented Wideband Spectrum Sensing Using Nyquist Folding Receiver
Aug 14, 2023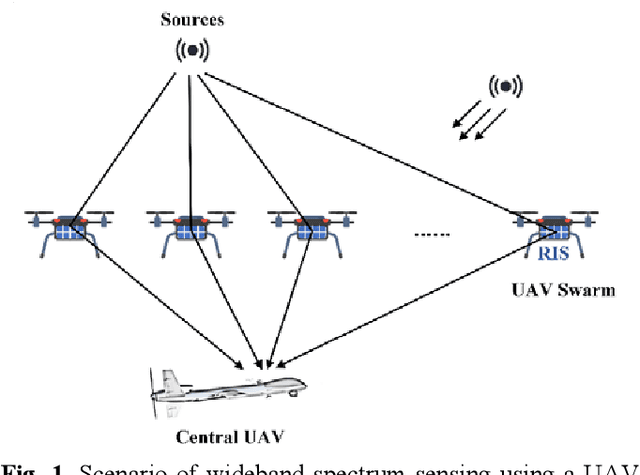
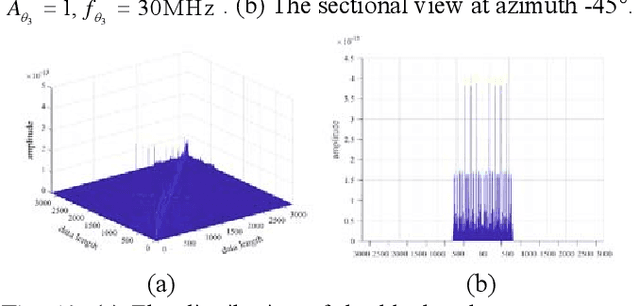
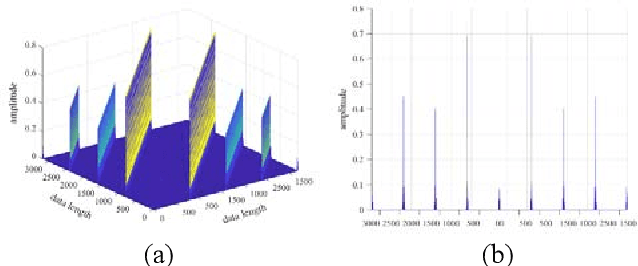
Distributed unmanned aerial vehicle (UAV) swarms are formed by multiple UAVs with increased portability, higher levels of sensing capabilities, and more powerful autonomy. These features make them attractive for many recent applica-tions, potentially increasing the shortage of spectrum resources. In this paper, wideband spectrum sensing augmented technology is discussed for distributed UAV swarms to improve the utilization of spectrum. However, the sub-Nyquist sampling applied in existing schemes has high hardware complexity, power consumption, and low recovery efficiency for non-strictly sparse conditions. Thus, the Nyquist folding receiver (NYFR) is considered for the distributed UAV swarms, which can theoretically achieve full-band spectrum detection and reception using a single analog-to-digital converter (ADC) at low speed for all circuit components. There is a focus on the sensing model of two multichannel scenarios for the distributed UAV swarms, one with a complete functional receiver for the UAV swarm with RIS, and another with a decentralized UAV swarm equipped with a complete functional receiver for each UAV element. The key issue is to consider whether the application of RIS technology will bring advantages to spectrum sensing and the data fusion problem of decentralized UAV swarms based on the NYFR architecture. Therefore, the property for multiple pulse reconstruction is analyzed through the Gershgorin circle theorem, especially for very short pulses. Further, the block sparse recovery property is analyzed for wide bandwidth signals. The proposed technology can improve the processing capability for multiple signals and wide bandwidth signals while reducing interference from folded noise and subsampled harmonics. Experiment results show augmented spectrum sensing efficiency under non-strictly sparse conditions.
Wideband Power Spectrum Sensing: a Fast Practical Solution for Nyquist Folding Receiver
Aug 14, 2023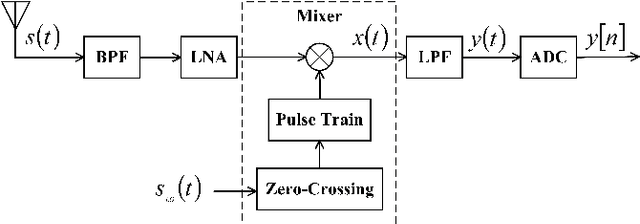
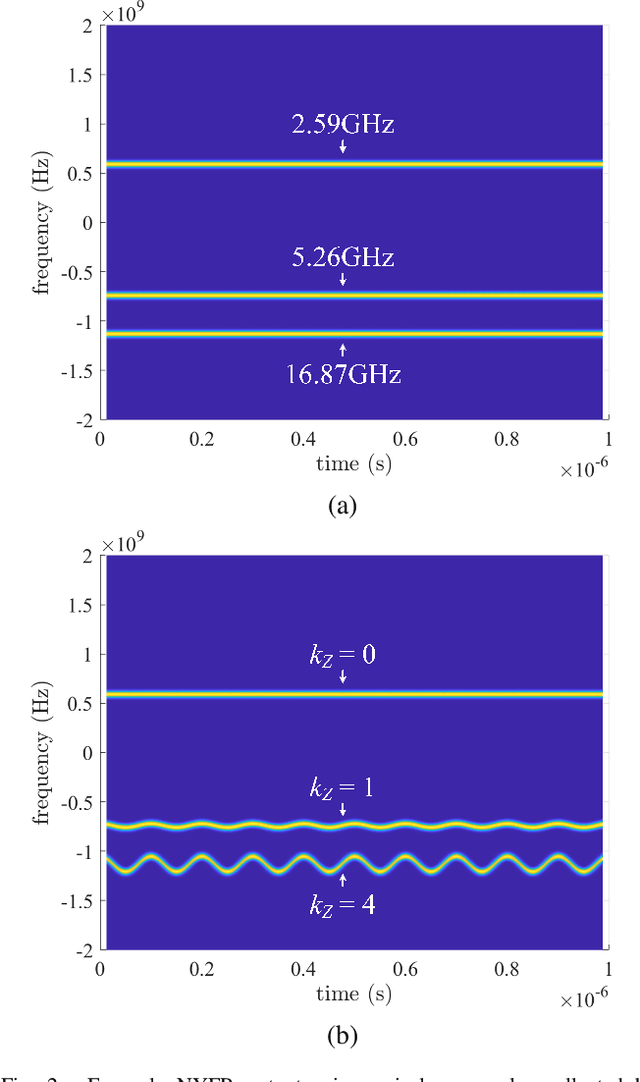
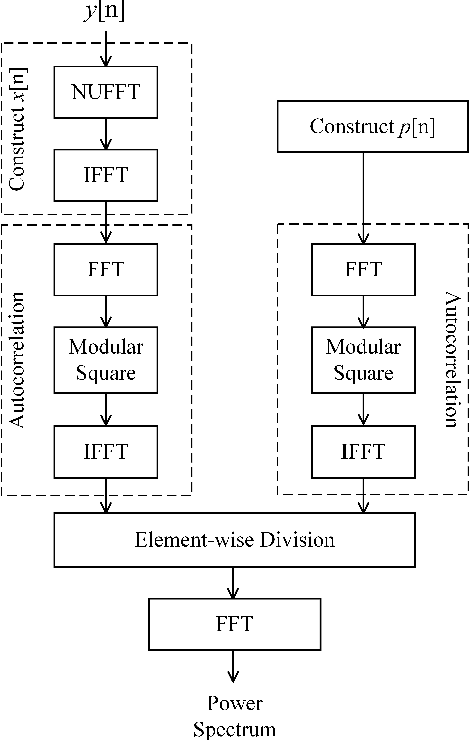
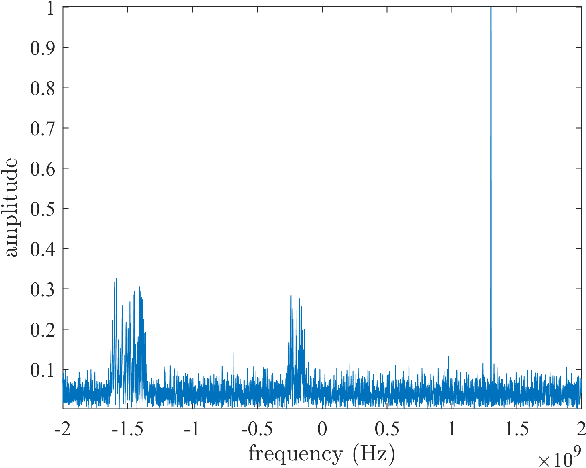
The limited availability of spectrum resources has been growing into a critical problem in wireless communications, remote sensing, and electronic surveillance, etc. To address the high-speed sampling bottleneck of wideband spectrum sensing, a fast and practical solution of power spectrum estimation for Nyquist folding receiver (NYFR) is proposed in this paper. The NYFR architectures is can theoretically achieve the full-band signal sensing with a hundred percent of probability of intercept. But the existing algorithm is difficult to realize in real-time due to its high complexity and complicated calculations. By exploring the sub-sampling principle inherent in NYFR, a computationally efficient method is introduced with compressive covariance sensing. That can be efficient implemented via only the non-uniform fast Fourier transform, fast Fourier transform, and some simple multiplication operations. Meanwhile, the state-of-the-art power spectrum reconstruction model for NYFR of time-domain and frequency-domain is constructed in this paper as a comparison. Furthermore, the computational complexity of the proposed method scales linearly with the Nyquist-rate sampled number of samples and the sparsity of spectrum occupancy. Simulation results and discussion demonstrate that the low complexity in sampling and computation is a more practical solution to meet the real-time wideband spectrum sensing applications.
Quantifying the Benefit of Artificial Intelligence for Scientific Research
Apr 17, 2023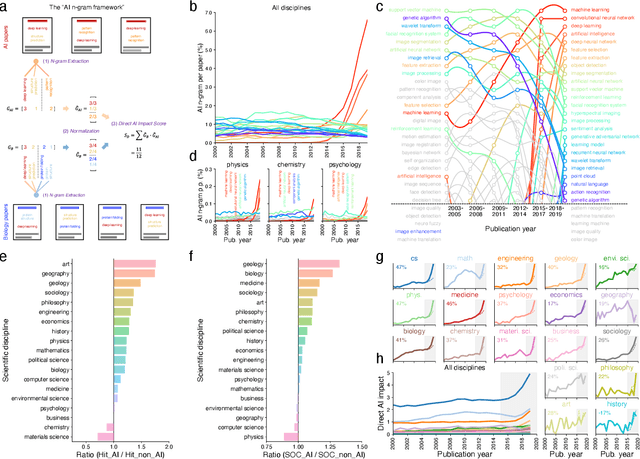
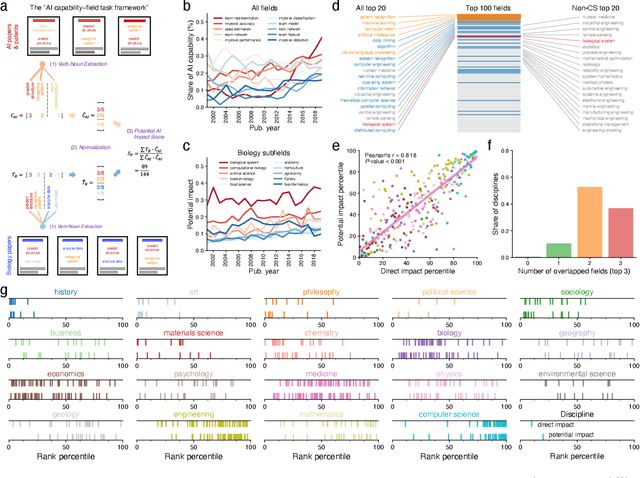
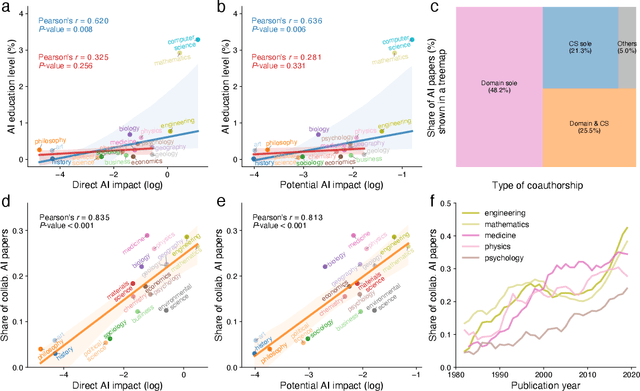
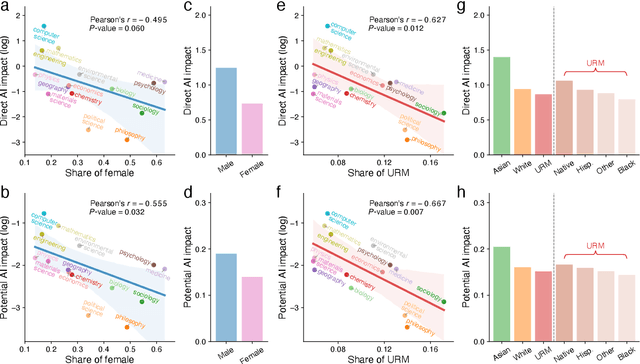
The ongoing artificial intelligence (AI) revolution has the potential to change almost every line of work. As AI capabilities continue to improve in accuracy, robustness, and reach, AI may outperform and even replace human experts across many valuable tasks. Despite enormous efforts devoted to understanding AI's impact on labor and the economy and its recent success in accelerating scientific discovery and progress, we lack a systematic understanding of how advances in AI may benefit scientific research across disciplines and fields. Here we develop a measurement framework to estimate both the direct use of AI and the potential benefit of AI in scientific research by applying natural language processing techniques to 87.6 million publications and 7.1 million patents. We find that the use of AI in research appears widespread throughout the sciences, growing especially rapidly since 2015, and papers that use AI exhibit an impact premium, more likely to be highly cited both within and outside their disciplines. While almost every discipline contains some subfields that benefit substantially from AI, analyzing 4.6 million course syllabi across various educational disciplines, we find a systematic misalignment between the education of AI and its impact on research, suggesting the supply of AI talents in scientific disciplines is not commensurate with AI research demands. Lastly, examining who benefits from AI within the scientific workforce, we find that disciplines with a higher proportion of women or black scientists tend to be associated with less benefit, suggesting that AI's growing impact on research may further exacerbate existing inequalities in science. As the connection between AI and scientific research deepens, our findings may have an increasing value, with important implications for the equity and sustainability of the research enterprise.
Rational Polynomial Camera Model Warping for Deep Learning Based Satellite Multi-View Stereo Matching
Sep 23, 2021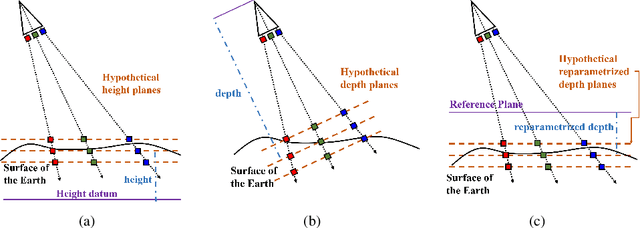

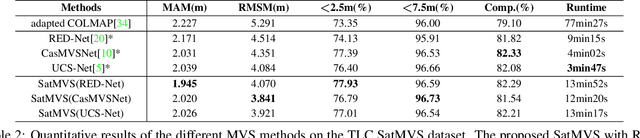
Satellite multi-view stereo (MVS) imagery is particularly suited for large-scale Earth surface reconstruction. Differing from the perspective camera model (pin-hole model) that is commonly used for close-range and aerial cameras, the cubic rational polynomial camera (RPC) model is the mainstream model for push-broom linear-array satellite cameras. However, the homography warping used in the prevailing learning based MVS methods is only applicable to pin-hole cameras. In order to apply the SOTA learning based MVS technology to the satellite MVS task for large-scale Earth surface reconstruction, RPC warping should be considered. In this work, we propose, for the first time, a rigorous RPC warping module. The rational polynomial coefficients are recorded as a tensor, and the RPC warping is formulated as a series of tensor transformations. Based on the RPC warping, we propose the deep learning based satellite MVS (SatMVS) framework for large-scale and wide depth range Earth surface reconstruction. We also introduce a large-scale satellite image dataset consisting of 519 5120${\times}$5120 images, which we call the TLC SatMVS dataset. The satellite images were acquired from a three-line camera (TLC) that catches triple-view images simultaneously, forming a valuable supplement to the existing open-source WorldView-3 datasets with single-scanline images. Experiments show that the proposed RPC warping module and the SatMVS framework can achieve a superior reconstruction accuracy compared to the pin-hole fitting method and conventional MVS methods. Code and data are available at https://github.com/WHU-GPCV/SatMVS.