 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGergely Neu
Optimisic Information Directed Sampling
Feb 23, 2024
We study the problem of online learning in contextual bandit problems where the loss function is assumed to belong to a known parametric function class. We propose a new analytic framework for this setting that bridges the Bayesian theory of information-directed sampling due to Russo and Van Roy (2018) and the worst-case theory of Foster, Kakade, Qian, and Rakhlin (2021) based on the decision-estimation coefficient. Drawing from both lines of work, we propose a algorithmic template called Optimistic Information-Directed Sampling and show that it can achieve instance-dependent regret guarantees similar to the ones achievable by the classic Bayesian IDS method, but with the major advantage of not requiring any Bayesian assumptions. The key technical innovation of our analysis is introducing an optimistic surrogate model for the regret and using it to define a frequentist version of the Information Ratio of Russo and Van Roy (2018), and a less conservative version of the Decision Estimation Coefficient of Foster et al. (2021). Keywords: Contextual bandits, information-directed sampling, decision estimation coefficient, first-order regret bounds.
Dealing with unbounded gradients in stochastic saddle-point optimization
Feb 21, 2024We study the performance of stochastic first-order methods for finding saddle points of convex-concave functions. A notorious challenge faced by such methods is that the gradients can grow arbitrarily large during optimization, which may result in instability and divergence. In this paper, we propose a simple and effective regularization technique that stabilizes the iterates and yields meaningful performance guarantees even if the domain and the gradient noise scales linearly with the size of the iterates (and is thus potentially unbounded). Besides providing a set of general results, we also apply our algorithm to a specific problem in reinforcement learning, where it leads to performance guarantees for finding near-optimal policies in an average-reward MDP without prior knowledge of the bias span.
Adversarial Contextual Bandits Go Kernelized
Oct 02, 2023We study a generalization of the problem of online learning in adversarial linear contextual bandits by incorporating loss functions that belong to a reproducing kernel Hilbert space, which allows for a more flexible modeling of complex decision-making scenarios. We propose a computationally efficient algorithm that makes use of a new optimistically biased estimator for the loss functions and achieves near-optimal regret guarantees under a variety of eigenvalue decay assumptions made on the underlying kernel. Specifically, under the assumption of polynomial eigendecay with exponent $c>1$, the regret is $\widetilde{O}(KT^{\frac{1}{2}(1+\frac{1}{c})})$, where $T$ denotes the number of rounds and $K$ the number of actions. Furthermore, when the eigendecay follows an exponential pattern, we achieve an even tighter regret bound of $\widetilde{O}(\sqrt{T})$. These rates match the lower bounds in all special cases where lower bounds are known at all, and match the best known upper bounds available for the more well-studied stochastic counterpart of our problem.
Importance-Weighted Offline Learning Done Right
Sep 27, 2023We study the problem of offline policy optimization in stochastic contextual bandit problems, where the goal is to learn a near-optimal policy based on a dataset of decision data collected by a suboptimal behavior policy. Rather than making any structural assumptions on the reward function, we assume access to a given policy class and aim to compete with the best comparator policy within this class. In this setting, a standard approach is to compute importance-weighted estimators of the value of each policy, and select a policy that minimizes the estimated value up to a "pessimistic" adjustment subtracted from the estimates to reduce their random fluctuations. In this paper, we show that a simple alternative approach based on the "implicit exploration" estimator of \citet{Neu2015} yields performance guarantees that are superior in nearly all possible terms to all previous results. Most notably, we remove an extremely restrictive "uniform coverage" assumption made in all previous works. These improvements are made possible by the observation that the upper and lower tails importance-weighted estimators behave very differently from each other, and their careful control can massively improve on previous results that were all based on symmetric two-sided concentration inequalities. We also extend our results to infinite policy classes in a PAC-Bayesian fashion, and showcase the robustness of our algorithm to the choice of hyper-parameters by means of numerical simulations.
Online-to-PAC Conversions: Generalization Bounds via Regret Analysis
May 31, 2023We present a new framework for deriving bounds on the generalization bound of statistical learning algorithms from the perspective of online learning. Specifically, we construct an online learning game called the "generalization game", where an online learner is trying to compete with a fixed statistical learning algorithm in predicting the sequence of generalization gaps on a training set of i.i.d. data points. We establish a connection between the online and statistical learning setting by showing that the existence of an online learning algorithm with bounded regret in this game implies a bound on the generalization error of the statistical learning algorithm, up to a martingale concentration term that is independent of the complexity of the statistical learning method. This technique allows us to recover several standard generalization bounds including a range of PAC-Bayesian and information-theoretic guarantees, as well as generalizations thereof.
Offline Primal-Dual Reinforcement Learning for Linear MDPs
May 22, 2023
Offline Reinforcement Learning (RL) aims to learn a near-optimal policy from a fixed dataset of transitions collected by another policy. This problem has attracted a lot of attention recently, but most existing methods with strong theoretical guarantees are restricted to finite-horizon or tabular settings. In constrast, few algorithms for infinite-horizon settings with function approximation and minimal assumptions on the dataset are both sample and computationally efficient. Another gap in the current literature is the lack of theoretical analysis for the average-reward setting, which is more challenging than the discounted setting. In this paper, we address both of these issues by proposing a primal-dual optimization method based on the linear programming formulation of RL. Our key contribution is a new reparametrization that allows us to derive low-variance gradient estimators that can be used in a stochastic optimization scheme using only samples from the behavior policy. Our method finds an $\varepsilon$-optimal policy with $O(\varepsilon^{-4})$ samples, improving on the previous $O(\varepsilon^{-5})$, while being computationally efficient for infinite-horizon discounted and average-reward MDPs with realizable linear function approximation and partial coverage. Moreover, to the best of our knowledge, this is the first theoretical result for average-reward offline RL.
First- and Second-Order Bounds for Adversarial Linear Contextual Bandits
May 01, 2023We consider the adversarial linear contextual bandit setting, which allows for the loss functions associated with each of $K$ arms to change over time without restriction. Assuming the $d$-dimensional contexts are drawn from a fixed known distribution, the worst-case expected regret over the course of $T$ rounds is known to scale as $\tilde O(\sqrt{Kd T})$. Under the additional assumption that the density of the contexts is log-concave, we obtain a second-order bound of order $\tilde O(K\sqrt{d V_T})$ in terms of the cumulative second moment of the learner's losses $V_T$, and a closely related first-order bound of order $\tilde O(K\sqrt{d L_T^*})$ in terms of the cumulative loss of the best policy $L_T^*$. Since $V_T$ or $L_T^*$ may be significantly smaller than $T$, these improve over the worst-case regret whenever the environment is relatively benign. Our results are obtained using a truncated version of the continuous exponential weights algorithm over the probability simplex, which we analyse by exploiting a novel connection to the linear bandit setting without contexts.
Optimistic Planning by Regularized Dynamic Programming
Mar 03, 2023We propose a new method for optimistic planning in infinite-horizon discounted Markov decision processes based on the idea of adding regularization to the updates of an otherwise standard approximate value iteration procedure. This technique allows us to avoid contraction and monotonicity arguments that are typically required by existing analyses of approximate dynamic programming methods, and in particular to use approximate transition functions estimated via least-squares procedures in MDPs with linear function approximation. We use our method to provide a computationally efficient algorithm for learning near-optimal policies in discounted linear kernel MDPs from a single stream of experience, and show that it achieves near-optimal statistical guarantees.
Sufficient Exploration for Convex Q-learning
Oct 17, 2022



In recent years there has been a collective research effort to find new formulations of reinforcement learning that are simultaneously more efficient and more amenable to analysis. This paper concerns one approach that builds on the linear programming (LP) formulation of optimal control of Manne. A primal version is called logistic Q-learning, and a dual variant is convex Q-learning. This paper focuses on the latter, while building bridges with the former. The main contributions follow: (i) The dual of convex Q-learning is not precisely Manne's LP or a version of logistic Q-learning, but has similar structure that reveals the need for regularization to avoid over-fitting. (ii) A sufficient condition is obtained for a bounded solution to the Q-learning LP. (iii) Simulation studies reveal numerical challenges when addressing sampled-data systems based on a continuous time model. The challenge is addressed using state-dependent sampling. The theory is illustrated with applications to examples from OpenAI gym. It is shown that convex Q-learning is successful in cases where standard Q-learning diverges, such as the LQR problem.
Proximal Point Imitation Learning
Sep 22, 2022
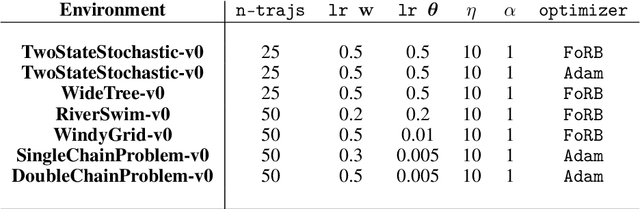


This work develops new algorithms with rigorous efficiency guarantees for infinite horizon imitation learning (IL) with linear function approximation without restrictive coherence assumptions. We begin with the minimax formulation of the problem and then outline how to leverage classical tools from optimization, in particular, the proximal-point method (PPM) and dual smoothing, for online and offline IL, respectively. Thanks to PPM, we avoid nested policy evaluation and cost updates for online IL appearing in the prior literature. In particular, we do away with the conventional alternating updates by the optimization of a single convex and smooth objective over both cost and Q-functions. When solved inexactly, we relate the optimization errors to the suboptimality of the recovered policy. As an added bonus, by re-interpreting PPM as dual smoothing with the expert policy as a center point, we also obtain an offline IL algorithm enjoying theoretical guarantees in terms of required expert trajectories. Finally, we achieve convincing empirical performance for both linear and neural network function approximation.