 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMatteo Papini
Learning Optimal Deterministic Policies with Stochastic Policy Gradients
May 03, 2024
Policy gradient (PG) methods are successful approaches to deal with continuous reinforcement learning (RL) problems. They learn stochastic parametric (hyper)policies by either exploring in the space of actions or in the space of parameters. Stochastic controllers, however, are often undesirable from a practical perspective because of their lack of robustness, safety, and traceability. In common practice, stochastic (hyper)policies are learned only to deploy their deterministic version. In this paper, we make a step towards the theoretical understanding of this practice. After introducing a novel framework for modeling this scenario, we study the global convergence to the best deterministic policy, under (weak) gradient domination assumptions. Then, we illustrate how to tune the exploration level used for learning to optimize the trade-off between the sample complexity and the performance of the deployed deterministic policy. Finally, we quantitatively compare action-based and parameter-based exploration, giving a formal guise to intuitive results.
Optimisic Information Directed Sampling
Feb 23, 2024We study the problem of online learning in contextual bandit problems where the loss function is assumed to belong to a known parametric function class. We propose a new analytic framework for this setting that bridges the Bayesian theory of information-directed sampling due to Russo and Van Roy (2018) and the worst-case theory of Foster, Kakade, Qian, and Rakhlin (2021) based on the decision-estimation coefficient. Drawing from both lines of work, we propose a algorithmic template called Optimistic Information-Directed Sampling and show that it can achieve instance-dependent regret guarantees similar to the ones achievable by the classic Bayesian IDS method, but with the major advantage of not requiring any Bayesian assumptions. The key technical innovation of our analysis is introducing an optimistic surrogate model for the regret and using it to define a frequentist version of the Information Ratio of Russo and Van Roy (2018), and a less conservative version of the Decision Estimation Coefficient of Foster et al. (2021). Keywords: Contextual bandits, information-directed sampling, decision estimation coefficient, first-order regret bounds.
No-Regret Reinforcement Learning in Smooth MDPs
Feb 06, 2024Obtaining no-regret guarantees for reinforcement learning (RL) in the case of problems with continuous state and/or action spaces is still one of the major open challenges in the field. Recently, a variety of solutions have been proposed, but besides very specific settings, the general problem remains unsolved. In this paper, we introduce a novel structural assumption on the Markov decision processes (MDPs), namely $\nu-$smoothness, that generalizes most of the settings proposed so far (e.g., linear MDPs and Lipschitz MDPs). To face this challenging scenario, we propose two algorithms for regret minimization in $\nu-$smooth MDPs. Both algorithms build upon the idea of constructing an MDP representation through an orthogonal feature map based on Legendre polynomials. The first algorithm, \textsc{Legendre-Eleanor}, archives the no-regret property under weaker assumptions but is computationally inefficient, whereas the second one, \textsc{Legendre-LSVI}, runs in polynomial time, although for a smaller class of problems. After analyzing their regret properties, we compare our results with state-of-the-art ones from RL theory, showing that our algorithms achieve the best guarantees.
Importance-Weighted Offline Learning Done Right
Sep 27, 2023We study the problem of offline policy optimization in stochastic contextual bandit problems, where the goal is to learn a near-optimal policy based on a dataset of decision data collected by a suboptimal behavior policy. Rather than making any structural assumptions on the reward function, we assume access to a given policy class and aim to compete with the best comparator policy within this class. In this setting, a standard approach is to compute importance-weighted estimators of the value of each policy, and select a policy that minimizes the estimated value up to a "pessimistic" adjustment subtracted from the estimates to reduce their random fluctuations. In this paper, we show that a simple alternative approach based on the "implicit exploration" estimator of \citet{Neu2015} yields performance guarantees that are superior in nearly all possible terms to all previous results. Most notably, we remove an extremely restrictive "uniform coverage" assumption made in all previous works. These improvements are made possible by the observation that the upper and lower tails importance-weighted estimators behave very differently from each other, and their careful control can massively improve on previous results that were all based on symmetric two-sided concentration inequalities. We also extend our results to infinite policy classes in a PAC-Bayesian fashion, and showcase the robustness of our algorithm to the choice of hyper-parameters by means of numerical simulations.
Offline Primal-Dual Reinforcement Learning for Linear MDPs
May 22, 2023
Offline Reinforcement Learning (RL) aims to learn a near-optimal policy from a fixed dataset of transitions collected by another policy. This problem has attracted a lot of attention recently, but most existing methods with strong theoretical guarantees are restricted to finite-horizon or tabular settings. In constrast, few algorithms for infinite-horizon settings with function approximation and minimal assumptions on the dataset are both sample and computationally efficient. Another gap in the current literature is the lack of theoretical analysis for the average-reward setting, which is more challenging than the discounted setting. In this paper, we address both of these issues by proposing a primal-dual optimization method based on the linear programming formulation of RL. Our key contribution is a new reparametrization that allows us to derive low-variance gradient estimators that can be used in a stochastic optimization scheme using only samples from the behavior policy. Our method finds an $\varepsilon$-optimal policy with $O(\varepsilon^{-4})$ samples, improving on the previous $O(\varepsilon^{-5})$, while being computationally efficient for infinite-horizon discounted and average-reward MDPs with realizable linear function approximation and partial coverage. Moreover, to the best of our knowledge, this is the first theoretical result for average-reward offline RL.
Scalable Representation Learning in Linear Contextual Bandits with Constant Regret Guarantees
Oct 24, 2022
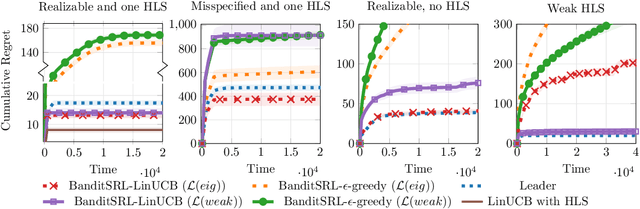
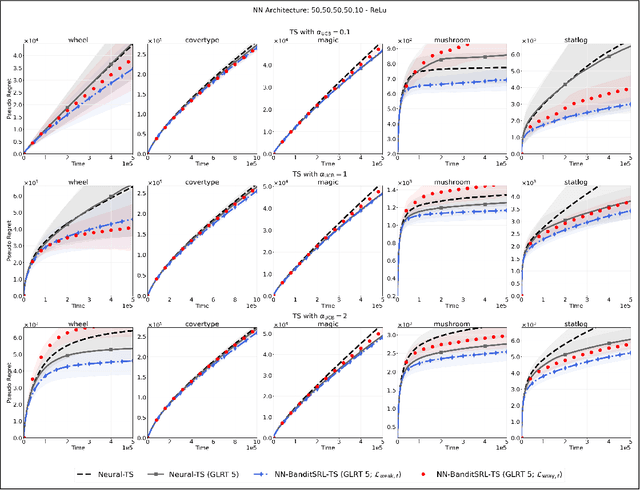
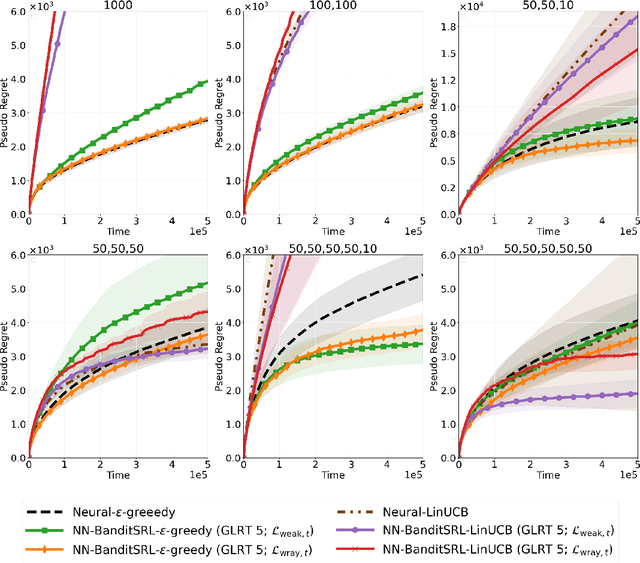
We study the problem of representation learning in stochastic contextual linear bandits. While the primary concern in this domain is usually to find realizable representations (i.e., those that allow predicting the reward function at any context-action pair exactly), it has been recently shown that representations with certain spectral properties (called HLS) may be more effective for the exploration-exploitation task, enabling LinUCB to achieve constant (i.e., horizon-independent) regret. In this paper, we propose BanditSRL, a representation learning algorithm that combines a novel constrained optimization problem to learn a realizable representation with good spectral properties with a generalized likelihood ratio test to exploit the recovered representation and avoid excessive exploration. We prove that BanditSRL can be paired with any no-regret algorithm and achieve constant regret whenever an HLS representation is available. Furthermore, BanditSRL can be easily combined with deep neural networks and we show how regularizing towards HLS representations is beneficial in standard benchmarks.
Online Learning with Off-Policy Feedback
Jul 18, 2022
We study the problem of online learning in adversarial bandit problems under a partial observability model called off-policy feedback. In this sequential decision making problem, the learner cannot directly observe its rewards, but instead sees the ones obtained by another unknown policy run in parallel (behavior policy). Instead of a standard exploration-exploitation dilemma, the learner has to face another challenge in this setting: due to limited observations outside of their control, the learner may not be able to estimate the value of each policy equally well. To address this issue, we propose a set of algorithms that guarantee regret bounds that scale with a natural notion of mismatch between any comparator policy and the behavior policy, achieving improved performance against comparators that are well-covered by the observations. We also provide an extension to the setting of adversarial linear contextual bandits, and verify the theoretical guarantees via a set of experiments. Our key algorithmic idea is adapting the notion of pessimistic reward estimators that has been recently popular in the context of off-policy reinforcement learning.
Lifting the Information Ratio: An Information-Theoretic Analysis of Thompson Sampling for Contextual Bandits
May 27, 2022We study the Bayesian regret of the renowned Thompson Sampling algorithm in contextual bandits with binary losses and adversarially-selected contexts. We adapt the information-theoretic perspective of Russo and Van Roy [2016] to the contextual setting by introducing a new concept of information ratio based on the mutual information between the unknown model parameter and the observed loss. This allows us to bound the regret in terms of the entropy of the prior distribution through a remarkably simple proof, and with no structural assumptions on the likelihood or the prior. The extension to priors with infinite entropy only requires a Lipschitz assumption on the log-likelihood. An interesting special case is that of logistic bandits with d-dimensional parameters, K actions, and Lipschitz logits, for which we provide a $\widetilde{O}(\sqrt{dKT})$ regret upper-bound that does not depend on the smallest slope of the sigmoid link function.
Reinforcement Learning in Linear MDPs: Constant Regret and Representation Selection
Oct 27, 2021



We study the role of the representation of state-action value functions in regret minimization in finite-horizon Markov Decision Processes (MDPs) with linear structure. We first derive a necessary condition on the representation, called universally spanning optimal features (UNISOFT), to achieve constant regret in any MDP with linear reward function. This result encompasses the well-known settings of low-rank MDPs and, more generally, zero inherent Bellman error (also known as the Bellman closure assumption). We then demonstrate that this condition is also sufficient for these classes of problems by deriving a constant regret bound for two optimistic algorithms (LSVI-UCB and ELEANOR). Finally, we propose an algorithm for representation selection and we prove that it achieves constant regret when one of the given representations, or a suitable combination of them, satisfies the UNISOFT condition.
Leveraging Good Representations in Linear Contextual Bandits
Apr 08, 2021



The linear contextual bandit literature is mostly focused on the design of efficient learning algorithms for a given representation. However, a contextual bandit problem may admit multiple linear representations, each one with different characteristics that directly impact the regret of the learning algorithm. In particular, recent works showed that there exist "good" representations for which constant problem-dependent regret can be achieved. In this paper, we first provide a systematic analysis of the different definitions of "good" representations proposed in the literature. We then propose a novel selection algorithm able to adapt to the best representation in a set of $M$ candidates. We show that the regret is indeed never worse than the regret obtained by running LinUCB on the best representation (up to a $\ln M$ factor). As a result, our algorithm achieves constant regret whenever a "good" representation is available in the set. Furthermore, we show that the algorithm may still achieve constant regret by implicitly constructing a "good" representation, even when none of the initial representations is "good". Finally, we empirically validate our theoretical findings in a number of standard contextual bandit problems.