 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGholamreza Haffari
IMO: Greedy Layer-Wise Sparse Representation Learning for Out-of-Distribution Text Classification with Pre-trained Models
Apr 21, 2024
Machine learning models have made incredible progress, but they still struggle when applied to examples from unseen domains. This study focuses on a specific problem of domain generalization, where a model is trained on one source domain and tested on multiple target domains that are unseen during training. We propose IMO: Invariant features Masks for Out-of-Distribution text classification, to achieve OOD generalization by learning invariant features. During training, IMO would learn sparse mask layers to remove irrelevant features for prediction, where the remaining features keep invariant. Additionally, IMO has an attention module at the token level to focus on tokens that are useful for prediction. Our comprehensive experiments show that IMO substantially outperforms strong baselines in terms of various evaluation metrics and settings.
Double Mixture: Towards Continual Event Detection from Speech
Apr 20, 2024Speech event detection is crucial for multimedia retrieval, involving the tagging of both semantic and acoustic events. Traditional ASR systems often overlook the interplay between these events, focusing solely on content, even though the interpretation of dialogue can vary with environmental context. This paper tackles two primary challenges in speech event detection: the continual integration of new events without forgetting previous ones, and the disentanglement of semantic from acoustic events. We introduce a new task, continual event detection from speech, for which we also provide two benchmark datasets. To address the challenges of catastrophic forgetting and effective disentanglement, we propose a novel method, 'Double Mixture.' This method merges speech expertise with robust memory mechanisms to enhance adaptability and prevent forgetting. Our comprehensive experiments show that this task presents significant challenges that are not effectively addressed by current state-of-the-art methods in either computer vision or natural language processing. Our approach achieves the lowest rates of forgetting and the highest levels of generalization, proving robust across various continual learning sequences. Our code and data are available at https://anonymous.4open.science/status/Continual-SpeechED-6461.
Modelling Political Coalition Negotiations Using LLM-based Agents
Feb 18, 2024Coalition negotiations are a cornerstone of parliamentary democracies, characterised by complex interactions and strategic communications among political parties. Despite its significance, the modelling of these negotiations has remained unexplored with the domain of Natural Language Processing (NLP), mostly due to lack of proper data. In this paper, we introduce coalition negotiations as a novel NLP task, and model it as a negotiation between large language model-based agents. We introduce a multilingual dataset, POLCA, comprising manifestos of European political parties and coalition agreements over a number of elections in these countries. This dataset addresses the challenge of the current scope limitations in political negotiation modelling by providing a diverse, real-world basis for simulation. Additionally, we propose a hierarchical Markov decision process designed to simulate the process of coalition negotiation between political parties and predict the outcomes. We evaluate the performance of state-of-the-art large language models (LLMs) as agents in handling coalition negotiations, offering insights into their capabilities and paving the way for future advancements in political modelling.
Direct Evaluation of Chain-of-Thought in Multi-hop Reasoning with Knowledge Graphs
Feb 17, 2024Large language models (LLMs) demonstrate strong reasoning abilities when prompted to generate chain-of-thought (CoT) explanations alongside answers. However, previous research on evaluating LLMs has solely focused on answer accuracy, neglecting the correctness of the generated CoT. In this paper, we delve deeper into the CoT reasoning capabilities of LLMs in multi-hop question answering by utilizing knowledge graphs (KGs). We propose a novel discriminative and generative CoT evaluation paradigm to assess LLMs' knowledge of reasoning and the accuracy of the generated CoT. Through experiments conducted on 5 different families of LLMs across 2 multi-hop question-answering datasets, we find that LLMs possess sufficient knowledge to perform reasoning. However, there exists a significant disparity between answer accuracy and faithfulness of the CoT reasoning generated by LLMs, indicating that they often arrive at correct answers through incorrect reasoning.
RENOVI: A Benchmark Towards Remediating Norm Violations in Socio-Cultural Conversations
Feb 17, 2024Norm violations occur when individuals fail to conform to culturally accepted behaviors, which may lead to potential conflicts. Remediating norm violations requires social awareness and cultural sensitivity of the nuances at play. To equip interactive AI systems with a remediation ability, we offer ReNoVi - a large-scale corpus of 9,258 multi-turn dialogues annotated with social norms, as well as define a sequence of tasks to help understand and remediate norm violations step by step. ReNoVi consists of two parts: 512 human-authored dialogues (real data), and 8,746 synthetic conversations generated by ChatGPT through prompt learning. While collecting sufficient human-authored data is costly, synthetic conversations provide suitable amounts of data to help mitigate the scarcity of training data, as well as the chance to assess the alignment between LLMs and humans in the awareness of social norms. We thus harness the power of ChatGPT to generate synthetic training data for our task. To ensure the quality of both human-authored and synthetic data, we follow a quality control protocol during data collection. Our experimental results demonstrate the importance of remediating norm violations in socio-cultural conversations, as well as the improvement in performance obtained from synthetic data.
Conversational SimulMT: Efficient Simultaneous Translation with Large Language Models
Feb 16, 2024Simultaneous machine translation (SimulMT) presents a challenging trade-off between translation quality and latency. Recent studies have shown that LLMs can achieve good performance in SimulMT tasks. However, this often comes at the expense of high inference cost and latency. In this paper, we propose a conversational SimulMT framework to enhance the inference efficiency of LLM-based SimulMT through multi-turn-dialogue-based decoding. Our experiments with Llama2-7b-chat on two SimulMT benchmarks demonstrate the superiority of LLM in translation quality while achieving comparable computational latency to specialized SimulMT models.
Continual Learning for Large Language Models: A Survey
Feb 07, 2024Large language models (LLMs) are not amenable to frequent re-training, due to high training costs arising from their massive scale. However, updates are necessary to endow LLMs with new skills and keep them up-to-date with rapidly evolving human knowledge. This paper surveys recent works on continual learning for LLMs. Due to the unique nature of LLMs, we catalog continue learning techniques in a novel multi-staged categorization scheme, involving continual pretraining, instruction tuning, and alignment. We contrast continual learning for LLMs with simpler adaptation methods used in smaller models, as well as with other enhancement strategies like retrieval-augmented generation and model editing. Moreover, informed by a discussion of benchmarks and evaluation, we identify several challenges and future work directions for this crucial task.
Improving Cross-Domain Low-Resource Text Generation through LLM Post-Editing: A Programmer-Interpreter Approach
Feb 07, 2024Post-editing has proven effective in improving the quality of text generated by large language models (LLMs) such as GPT-3.5 or GPT-4, particularly when direct updating of their parameters to enhance text quality is infeasible or expensive. However, relying solely on smaller language models for post-editing can limit the LLMs' ability to generalize across domains. Moreover, the editing strategies in these methods are not optimally designed for text-generation tasks. To address these limitations, we propose a neural programmer-interpreter approach that preserves the domain generalization ability of LLMs when editing their output. The editing actions in this framework are specifically devised for text generation. Extensive experiments demonstrate that the programmer-interpreter significantly enhances GPT-3.5's performance in logical form-to-text conversion and low-resource machine translation, surpassing other state-of-the-art (SOTA) LLM post-editing methods in cross-domain settings.
Let's Negotiate! A Survey of Negotiation Dialogue Systems
Feb 02, 2024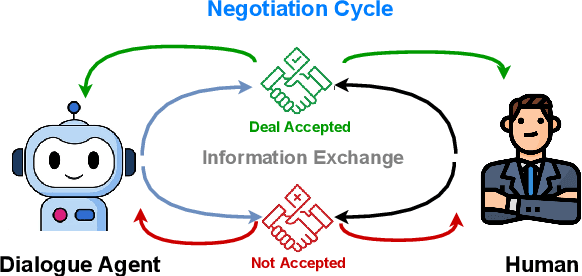
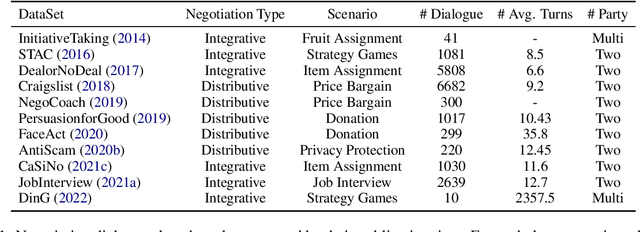

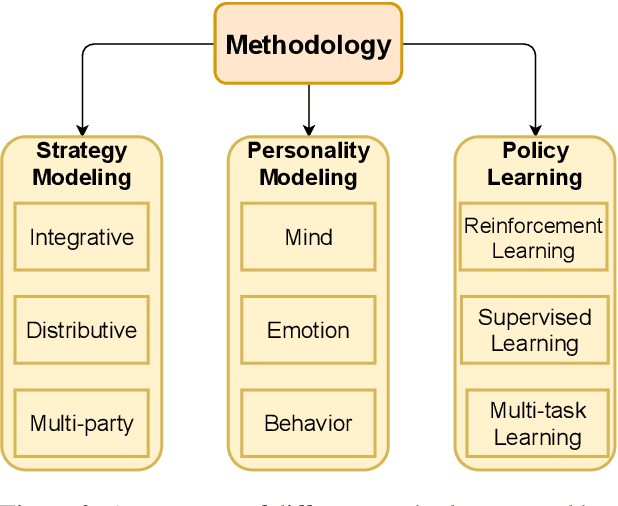
Negotiation is a crucial ability in human communication. Recently, there has been a resurgent research interest in negotiation dialogue systems, whose goal is to create intelligent agents that can assist people in resolving conflicts or reaching agreements. Although there have been many explorations into negotiation dialogue systems, a systematic review of this task has not been performed to date. We aim to fill this gap by investigating recent studies in the field of negotiation dialogue systems, and covering benchmarks, evaluations and methodologies within the literature. We also discuss potential future directions, including multi-modal, multi-party and cross-cultural negotiation scenarios. Our goal is to provide the community with a systematic overview of negotiation dialogue systems and to inspire future research.
Assistive Large Language Model Agents for Socially-Aware Negotiation Dialogues
Jan 29, 2024In this work, we aim to develop LLM agents to mitigate social norm violations in negotiations in a multi-agent setting. We simulate real-world negotiations by letting two large Language Models (LLMs) play the roles of two negotiators in each conversation. A third LLM acts as a remediation agent to rewrite utterances violating norms for improving negotiation outcomes. As it is a novel task, no manually constructed data is available. To address this limitation, we introduce a value impact based In-Context Learning (ICL) method to identify high-quality ICL examples for the LLM-based remediation agents, where the value impact function measures the quality of negotiation outcomes. We show the connection of this method to policy learning and provide rich empirical evidence to demonstrate its effectiveness in negotiations across three different topics: product sale, housing price, and salary negotiation. The source code and the generated dataset will be publicly available upon acceptance.