 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThuy-Trang Vu
Direct Evaluation of Chain-of-Thought in Multi-hop Reasoning with Knowledge Graphs
Feb 17, 2024
Large language models (LLMs) demonstrate strong reasoning abilities when prompted to generate chain-of-thought (CoT) explanations alongside answers. However, previous research on evaluating LLMs has solely focused on answer accuracy, neglecting the correctness of the generated CoT. In this paper, we delve deeper into the CoT reasoning capabilities of LLMs in multi-hop question answering by utilizing knowledge graphs (KGs). We propose a novel discriminative and generative CoT evaluation paradigm to assess LLMs' knowledge of reasoning and the accuracy of the generated CoT. Through experiments conducted on 5 different families of LLMs across 2 multi-hop question-answering datasets, we find that LLMs possess sufficient knowledge to perform reasoning. However, there exists a significant disparity between answer accuracy and faithfulness of the CoT reasoning generated by LLMs, indicating that they often arrive at correct answers through incorrect reasoning.
Conversational SimulMT: Efficient Simultaneous Translation with Large Language Models
Feb 16, 2024Simultaneous machine translation (SimulMT) presents a challenging trade-off between translation quality and latency. Recent studies have shown that LLMs can achieve good performance in SimulMT tasks. However, this often comes at the expense of high inference cost and latency. In this paper, we propose a conversational SimulMT framework to enhance the inference efficiency of LLM-based SimulMT through multi-turn-dialogue-based decoding. Our experiments with Llama2-7b-chat on two SimulMT benchmarks demonstrate the superiority of LLM in translation quality while achieving comparable computational latency to specialized SimulMT models.
Continual Learning for Large Language Models: A Survey
Feb 07, 2024Large language models (LLMs) are not amenable to frequent re-training, due to high training costs arising from their massive scale. However, updates are necessary to endow LLMs with new skills and keep them up-to-date with rapidly evolving human knowledge. This paper surveys recent works on continual learning for LLMs. Due to the unique nature of LLMs, we catalog continue learning techniques in a novel multi-staged categorization scheme, involving continual pretraining, instruction tuning, and alignment. We contrast continual learning for LLMs with simpler adaptation methods used in smaller models, as well as with other enhancement strategies like retrieval-augmented generation and model editing. Moreover, informed by a discussion of benchmarks and evaluation, we identify several challenges and future work directions for this crucial task.
Adapting Large Language Models for Document-Level Machine Translation
Jan 12, 2024Large language models (LLMs) have made significant strides in various natural language processing (NLP) tasks. Recent research shows that the moderately-sized LLMs often outperform their larger counterparts after task-specific fine-tuning. In this work, we delve into the process of adapting LLMs to specialize in document-level machine translation (DocMT) for a specific language pair. Firstly, we explore how prompt strategies affect downstream translation performance. Then, we conduct extensive experiments with two fine-tuning methods, three LLM backbones, and 18 translation tasks across nine language pairs. Our findings indicate that in some cases, these specialized models even surpass GPT-4 in translation performance, while they still significantly suffer from the off-target translation issue in others, even if they are exclusively fine-tuned on bilingual parallel documents. Furthermore, we provide an in-depth analysis of these LLMs tailored for DocMT, exploring aspects such as translation errors, the scaling law of parallel documents, out-of-domain generalization, and the impact of zero-shot crosslingual transfer. The findings of this research not only shed light on the strengths and limitations of LLM-based DocMT models but also provide a foundation for future research in DocMT.
Systematic Assessment of Factual Knowledge in Large Language Models
Oct 30, 2023Previous studies have relied on existing question-answering benchmarks to evaluate the knowledge stored in large language models (LLMs). However, this approach has limitations regarding factual knowledge coverage, as it mostly focuses on generic domains which may overlap with the pretraining data. This paper proposes a framework to systematically assess the factual knowledge of LLMs by leveraging knowledge graphs (KGs). Our framework automatically generates a set of questions and expected answers from the facts stored in a given KG, and then evaluates the accuracy of LLMs in answering these questions. We systematically evaluate the state-of-the-art LLMs with KGs in generic and specific domains. The experiment shows that ChatGPT is consistently the top performer across all domains. We also find that LLMs performance depends on the instruction finetuning, domain and question complexity and is prone to adversarial context.
Simultaneous Machine Translation with Large Language Models
Sep 13, 2023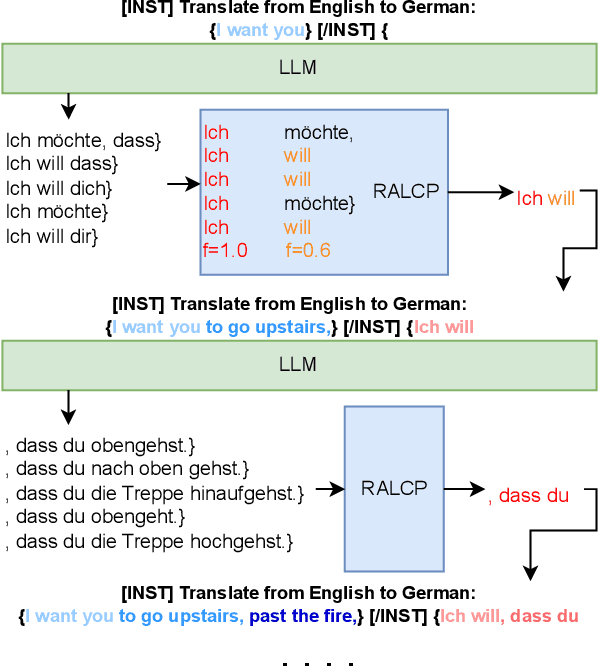
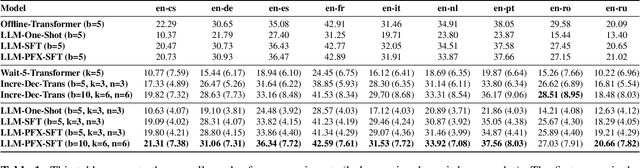
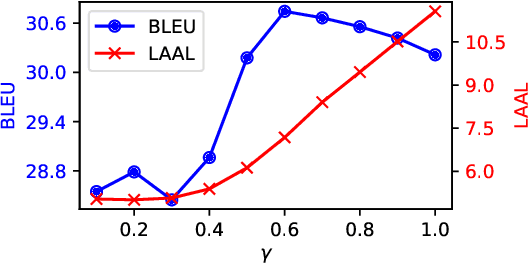
Large language models (LLM) have demonstrated their abilities to solve various natural language processing tasks through dialogue-based interactions. For instance, research indicates that LLMs can achieve competitive performance in offline machine translation tasks for high-resource languages. However, applying LLMs to simultaneous machine translation (SimulMT) poses many challenges, including issues related to the training-inference mismatch arising from different decoding patterns. In this paper, we explore the feasibility of utilizing LLMs for SimulMT. Building upon conventional approaches, we introduce a simple yet effective mixture policy that enables LLMs to engage in SimulMT without requiring additional training. Furthermore, after Supervised Fine-Tuning (SFT) on a mixture of full and prefix sentences, the model exhibits significant performance improvements. Our experiments, conducted with Llama2-7B-chat on nine language pairs from the MUST-C dataset, demonstrate that LLM can achieve translation quality and latency comparable to dedicated SimulMT models.
Active Continual Learning: Labelling Queries in a Sequence of Tasks
May 06, 2023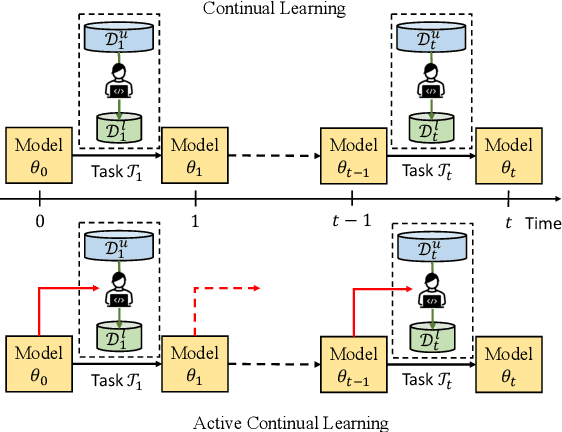
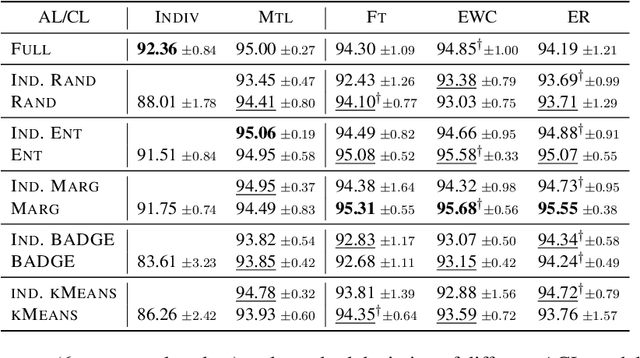
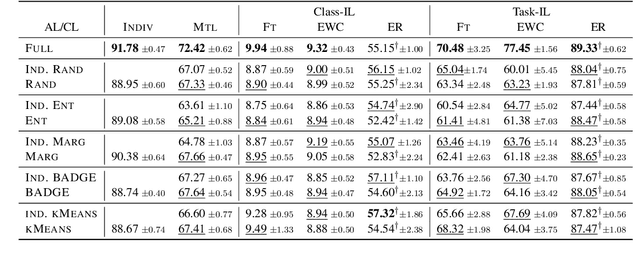
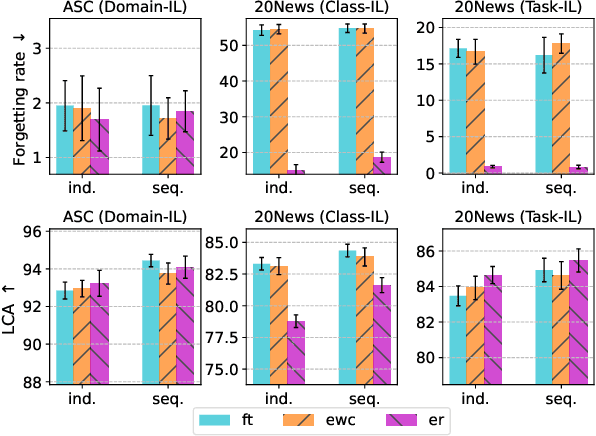
Acquiring new knowledge without forgetting what has been learned in a sequence of tasks is the central focus of continual learning (CL). While tasks arrive sequentially, the training data are often prepared and annotated independently, leading to CL of incoming supervised learning tasks. This paper considers the under-explored problem of active continual learning (ACL) for a sequence of active learning (AL) tasks, where each incoming task includes a pool of unlabelled data and an annotation budget. We investigate the effectiveness and interplay between several AL and CL algorithms in the domain, class and task-incremental scenarios. Our experiments reveal the trade-off between two contrasting goals of not forgetting the old knowledge and the ability to quickly learn in CL and AL. While conditioning the query strategy on the annotations collected for the previous tasks leads to improved task performance on the domain and task incremental learning, our proposed forgetting-learning profile suggests a gap in balancing the effect of AL and CL for the class-incremental scenario.
Koala: An Index for Quantifying Overlaps with Pre-training Corpora
Mar 26, 2023



In very recent years more attention has been placed on probing the role of pre-training data in Large Language Models (LLMs) downstream behaviour. Despite the importance, there is no public tool that supports such analysis of pre-training corpora at large scale. To help research in this space, we launch Koala, a searchable index over large pre-training corpora using compressed suffix arrays with highly efficient compression rate and search support. In its first release we index the public proportion of OPT 175B pre-training data. Koala provides a framework to do forensic analysis on the current and future benchmarks as well as to assess the degree of memorization in the output from the LLMs. Koala is available for public use at https://koala-index.erc.monash.edu/.
Generalised Unsupervised Domain Adaptation of Neural Machine Translation with Cross-Lingual Data Selection
Sep 09, 2021



This paper considers the unsupervised domain adaptation problem for neural machine translation (NMT), where we assume the access to only monolingual text in either the source or target language in the new domain. We propose a cross-lingual data selection method to extract in-domain sentences in the missing language side from a large generic monolingual corpus. Our proposed method trains an adaptive layer on top of multilingual BERT by contrastive learning to align the representation between the source and target language. This then enables the transferability of the domain classifier between the languages in a zero-shot manner. Once the in-domain data is detected by the classifier, the NMT model is then adapted to the new domain by jointly learning translation and domain discrimination tasks. We evaluate our cross-lingual data selection method on NMT across five diverse domains in three language pairs, as well as a real-world scenario of translation for COVID-19. The results show that our proposed method outperforms other selection baselines up to +1.5 BLEU score.
Effective Unsupervised Domain Adaptation with Adversarially Trained Language Models
Oct 05, 2020



Recent work has shown the importance of adaptation of broad-coverage contextualised embedding models on the domain of the target task of interest. Current self-supervised adaptation methods are simplistic, as the training signal comes from a small percentage of \emph{randomly} masked-out tokens. In this paper, we show that careful masking strategies can bridge the knowledge gap of masked language models (MLMs) about the domains more effectively by allocating self-supervision where it is needed. Furthermore, we propose an effective training strategy by adversarially masking out those tokens which are harder to reconstruct by the underlying MLM. The adversarial objective leads to a challenging combinatorial optimisation problem over \emph{subsets} of tokens, which we tackle efficiently through relaxation to a variational lowerbound and dynamic programming. On six unsupervised domain adaptation tasks involving named entity recognition, our method strongly outperforms the random masking strategy and achieves up to +1.64 F1 score improvements.