 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGilles Tredan
Under manipulations, are some AI models harder to audit?
Feb 14, 2024
Auditors need robust methods to assess the compliance of web platforms with the law. However, since they hardly ever have access to the algorithm, implementation, or training data used by a platform, the problem is harder than a simple metric estimation. Within the recent framework of manipulation-proof auditing, we study in this paper the feasibility of robust audits in realistic settings, in which models exhibit large capacities. We first prove a constraining result: if a web platform uses models that may fit any data, no audit strategy -- whether active or not -- can outperform random sampling when estimating properties such as demographic parity. To better understand the conditions under which state-of-the-art auditing techniques may remain competitive, we then relate the manipulability of audits to the capacity of the targeted models, using the Rademacher complexity. We empirically validate these results on popular models of increasing capacities, thus confirming experimentally that large-capacity models, which are commonly used in practice, are particularly hard to audit robustly. These results refine the limits of the auditing problem, and open up enticing questions on the connection between model capacity and the ability of platforms to manipulate audit attempts.
Fairness Auditing with Multi-Agent Collaboration
Feb 13, 2024Existing work in fairness audits assumes that agents operate independently. In this paper, we consider the case of multiple agents auditing the same platform for different tasks. Agents have two levers: their collaboration strategy, with or without coordination beforehand, and their sampling method. We theoretically study their interplay when agents operate independently or collaborate. We prove that, surprisingly, coordination can sometimes be detrimental to audit accuracy, whereas uncoordinated collaboration generally yields good results. Experimentation on real-world datasets confirms this observation, as the audit accuracy of uncoordinated collaboration matches that of collaborative optimal sampling.
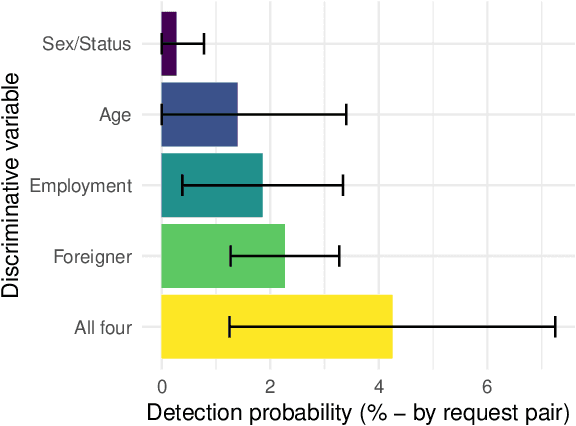
On the relevance of APIs facing fairwashed audits
May 23, 2023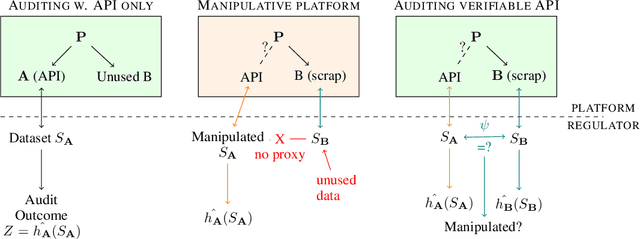


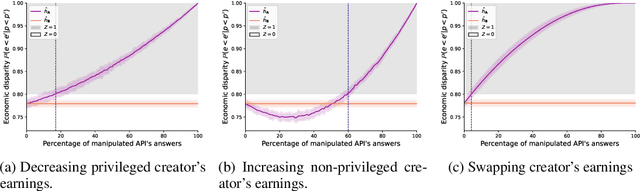
Recent legislation required AI platforms to provide APIs for regulators to assess their compliance with the law. Research has nevertheless shown that platforms can manipulate their API answers through fairwashing. Facing this threat for reliable auditing, this paper studies the benefits of the joint use of platform scraping and of APIs. In this setup, we elaborate on the use of scraping to detect manipulated answers: since fairwashing only manipulates API answers, exploiting scraps may reveal a manipulation. To abstract the wide range of specific API-scrap situations, we introduce a notion of proxy that captures the consistency an auditor might expect between both data sources. If the regulator has a good proxy of the consistency, then she can easily detect manipulation and even bypass the API to conduct her audit. On the other hand, without a good proxy, relying on the API is necessary, and the auditor cannot defend against fairwashing. We then simulate practical scenarios in which the auditor may mostly rely on the API to conveniently conduct the audit task, while maintaining her chances to detect a potential manipulation. To highlight the tension between the audit task and the API fairwashing detection task, we identify Pareto-optimal strategies in a practical audit scenario. We believe this research sets the stage for reliable audits in practical and manipulation-prone setups.
The Bouncer Problem: Challenges to Remote Explainability
Oct 03, 2019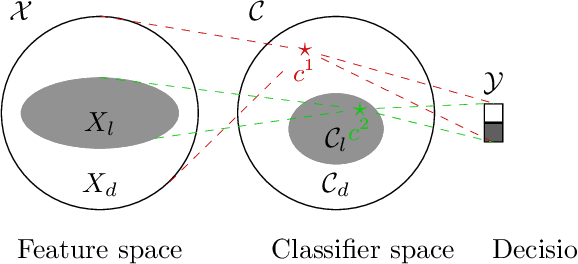
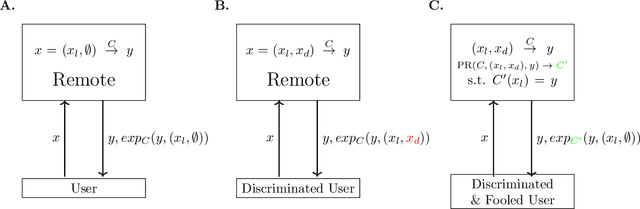
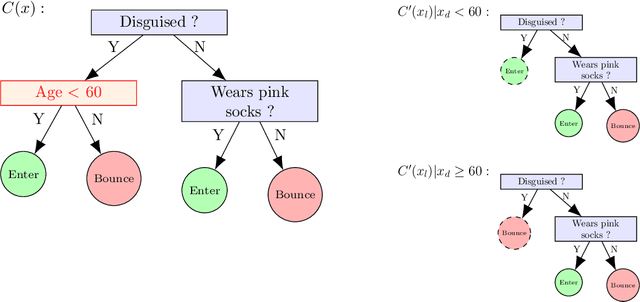
The concept of explainability is envisioned to satisfy society's demands for transparency on machine learning decisions. The concept is simple: like humans, algorithms should explain the rationale behind their decisions so that their fairness can be assessed. While this approach is promising in a local context (e.g. to explain a model during debugging at training time), we argue that this reasoning cannot simply be transposed in a remote context, where a trained model by a service provider is only accessible through its API. This is problematic as it constitutes precisely the target use-case requiring transparency from a societal perspective. Through an analogy with a club bouncer (which may provide untruthful explanations upon customer reject), we show that providing explanations cannot prevent a remote service from lying about the true reasons leading to its decisions. More precisely, we prove the impossibility of remote explainability for single explanations, by constructing an attack on explanations that hides discriminatory features to the querying user. We provide an example implementation of this attack. We then show that the probability that an observer spots the attack, using several explanations for attempting to find incoherences, is low in practical settings. This undermines the very concept of remote explainability in general.
A generic trust framework for large-scale open systems using machine learning
Mar 01, 2011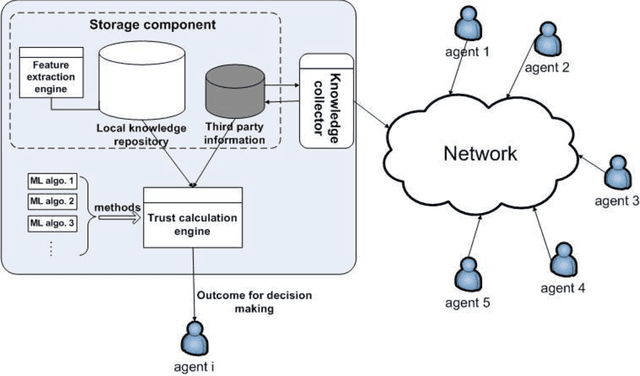
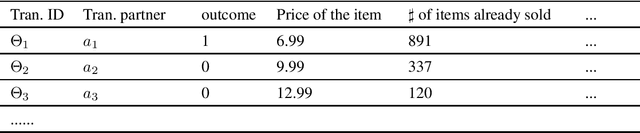
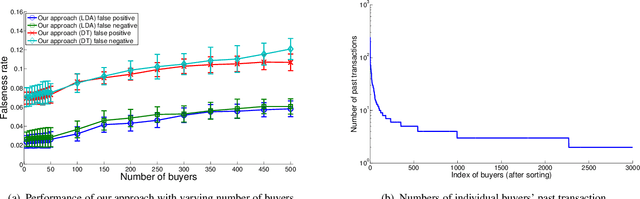
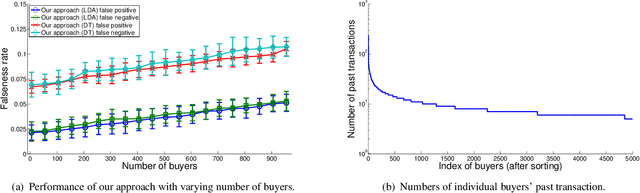
In many large scale distributed systems and on the web, agents need to interact with other unknown agents to carry out some tasks or transactions. The ability to reason about and assess the potential risks in carrying out such transactions is essential for providing a safe and reliable environment. A traditional approach to reason about the trustworthiness of a transaction is to determine the trustworthiness of the specific agent involved, derived from the history of its behavior. As a departure from such traditional trust models, we propose a generic, machine learning approach based trust framework where an agent uses its own previous transactions (with other agents) to build a knowledge base, and utilize this to assess the trustworthiness of a transaction based on associated features, which are capable of distinguishing successful transactions from unsuccessful ones. These features are harnessed using appropriate machine learning algorithms to extract relationships between the potential transaction and previous transactions. The trace driven experiments using real auction dataset show that this approach provides good accuracy and is highly efficient compared to other trust mechanisms, especially when historical information of the specific agent is rare, incomplete or inaccurate.