 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGopala K. Anumanchipalli
Towards Streaming Speech-to-Avatar Synthesis
Oct 25, 2023
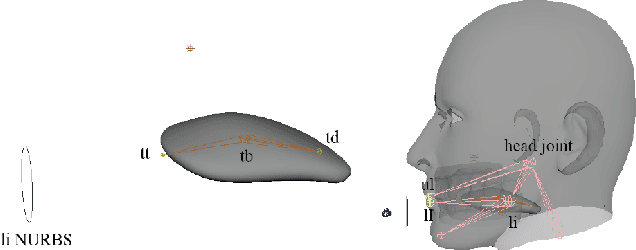
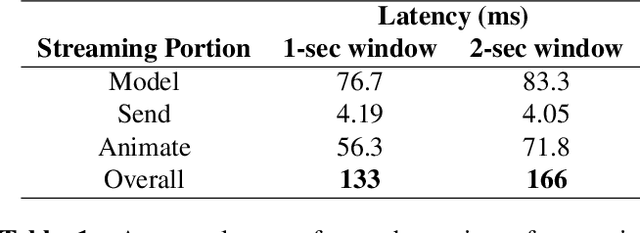
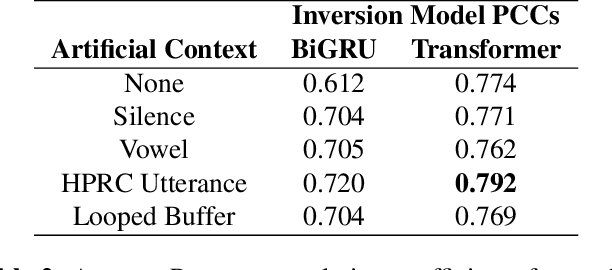

Streaming speech-to-avatar synthesis creates real-time animations for a virtual character from audio data. Accurate avatar representations of speech are important for the visualization of sound in linguistics, phonetics, and phonology, visual feedback to assist second language acquisition, and virtual embodiment for paralyzed patients. Previous works have highlighted the capability of deep articulatory inversion to perform high-quality avatar animation using electromagnetic articulography (EMA) features. However, these models focus on offline avatar synthesis with recordings rather than real-time audio, which is necessary for live avatar visualization or embodiment. To address this issue, we propose a method using articulatory inversion for streaming high quality facial and inner-mouth avatar animation from real-time audio. Our approach achieves 130ms average streaming latency for every 0.1 seconds of audio with a 0.792 correlation with ground truth articulations. Finally, we show generated mouth and tongue animations to demonstrate the efficacy of our methodology.
SD-HuBERT: Self-Distillation Induces Syllabic Organization in HuBERT
Oct 16, 2023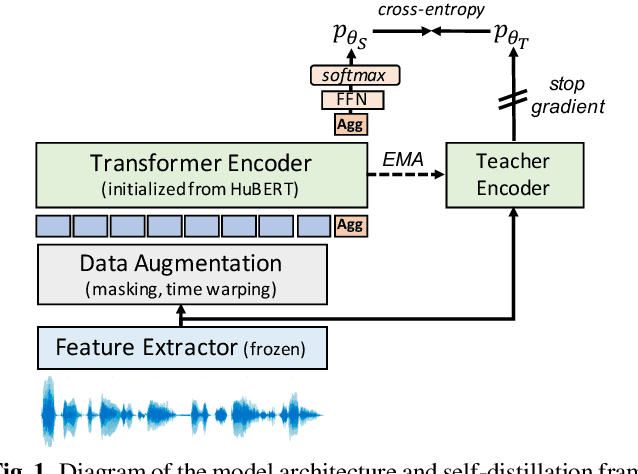

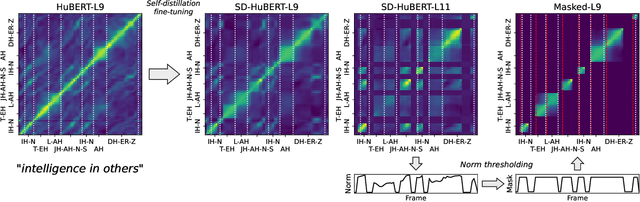
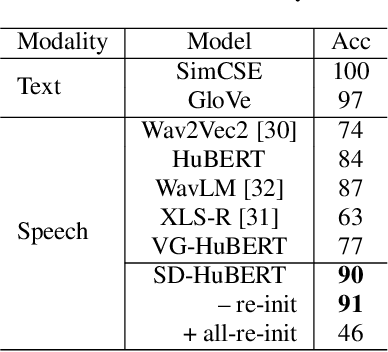
Data-driven unit discovery in self-supervised learning (SSL) of speech has embarked on a new era of spoken language processing. Yet, the discovered units often remain in phonetic space, limiting the utility of SSL representations. Here, we demonstrate that a syllabic organization emerges in learning sentence-level representation of speech. In particular, we adopt "self-distillation" objective to fine-tune the pretrained HuBERT with an aggregator token that summarizes the entire sentence. Without any supervision, the resulting model draws definite boundaries in speech, and the representations across frames show salient syllabic structures. We demonstrate that this emergent structure largely corresponds to the ground truth syllables. Furthermore, we propose a new benchmark task, Spoken Speech ABX, for evaluating sentence-level representation of speech. When compared to previous models, our model outperforms in both unsupervised syllable discovery and learning sentence-level representation. Together, we demonstrate that the self-distillation of HuBERT gives rise to syllabic organization without relying on external labels or modalities, and potentially provides novel data-driven units for spoken language modeling.
Self-Supervised Models of Speech Infer Universal Articulatory Kinematics
Oct 16, 2023Self-Supervised Learning (SSL) based models of speech have shown remarkable performance on a range of downstream tasks. These state-of-the-art models have remained blackboxes, but many recent studies have begun "probing" models like HuBERT, to correlate their internal representations to different aspects of speech. In this paper, we show "inference of articulatory kinematics" as fundamental property of SSL models, i.e., the ability of these models to transform acoustics into the causal articulatory dynamics underlying the speech signal. We also show that this abstraction is largely overlapping across the language of the data used to train the model, with preference to the language with similar phonological system. Furthermore, we show that with simple affine transformations, Acoustic-to-Articulatory inversion (AAI) is transferrable across speakers, even across genders, languages, and dialects, showing the generalizability of this property. Together, these results shed new light on the internals of SSL models that are critical to their superior performance, and open up new avenues into language-agnostic universal models for speech engineering, that are interpretable and grounded in speech science.
CiwaGAN: Articulatory information exchange
Sep 14, 2023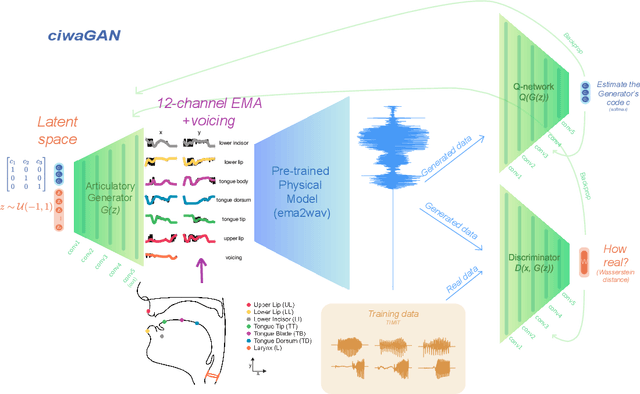

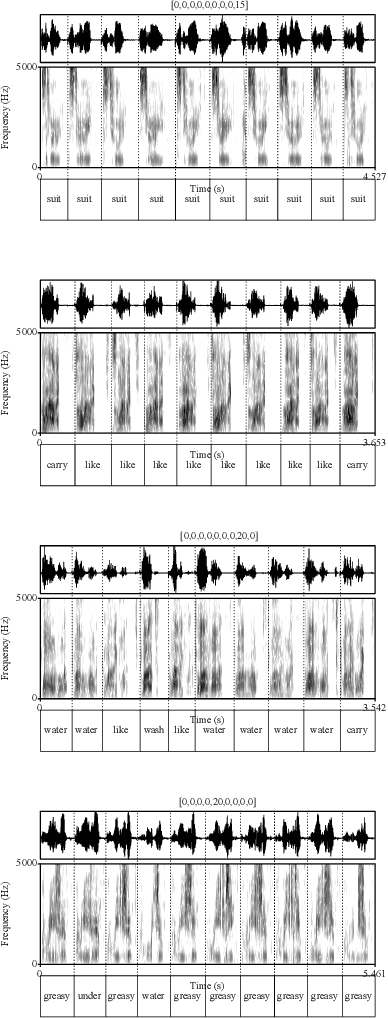
Humans encode information into sounds by controlling articulators and decode information from sounds using the auditory apparatus. This paper introduces CiwaGAN, a model of human spoken language acquisition that combines unsupervised articulatory modeling with an unsupervised model of information exchange through the auditory modality. While prior research includes unsupervised articulatory modeling and information exchange separately, our model is the first to combine the two components. The paper also proposes an improved articulatory model with more interpretable internal representations. The proposed CiwaGAN model is the most realistic approximation of human spoken language acquisition using deep learning. As such, it is useful for cognitively plausible simulations of the human speech act.
Neural Latent Aligner: Cross-trial Alignment for Learning Representations of Complex, Naturalistic Neural Data
Aug 12, 2023Understanding the neural implementation of complex human behaviors is one of the major goals in neuroscience. To this end, it is crucial to find a true representation of the neural data, which is challenging due to the high complexity of behaviors and the low signal-to-ratio (SNR) of the signals. Here, we propose a novel unsupervised learning framework, Neural Latent Aligner (NLA), to find well-constrained, behaviorally relevant neural representations of complex behaviors. The key idea is to align representations across repeated trials to learn cross-trial consistent information. Furthermore, we propose a novel, fully differentiable time warping model (TWM) to resolve the temporal misalignment of trials. When applied to intracranial electrocorticography (ECoG) of natural speaking, our model learns better representations for decoding behaviors than the baseline models, especially in lower dimensional space. The TWM is empirically validated by measuring behavioral coherence between aligned trials. The proposed framework learns more cross-trial consistent representations than the baselines, and when visualized, the manifold reveals shared neural trajectories across trials.
* Accepted at ICML 2023
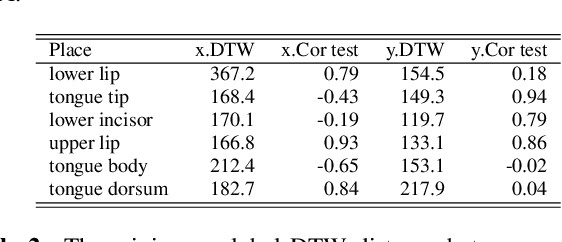
Deep Speech Synthesis from MRI-Based Articulatory Representations
Jul 05, 2023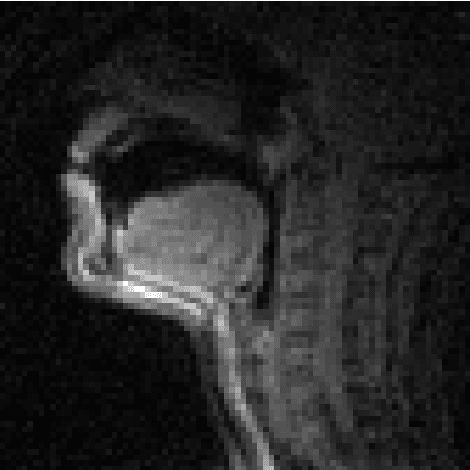
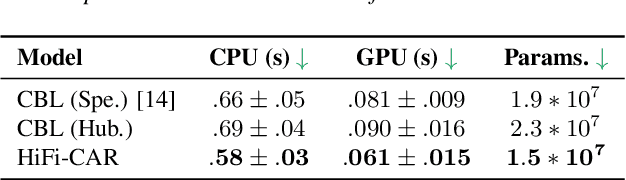
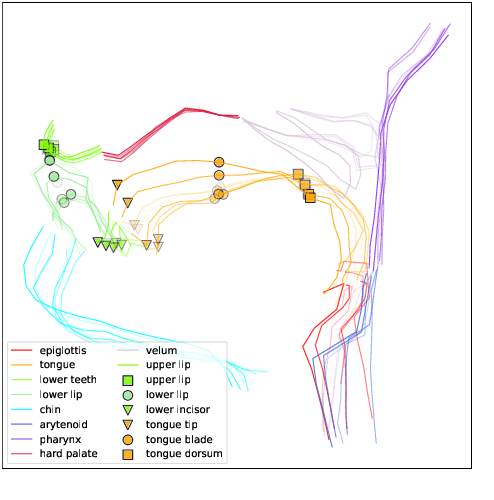
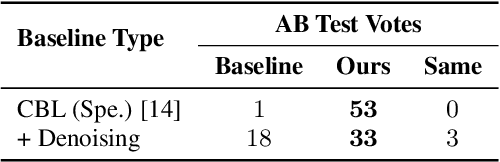
In this paper, we study articulatory synthesis, a speech synthesis method using human vocal tract information that offers a way to develop efficient, generalizable and interpretable synthesizers. While recent advances have enabled intelligible articulatory synthesis using electromagnetic articulography (EMA), these methods lack critical articulatory information like excitation and nasality, limiting generalization capabilities. To bridge this gap, we propose an alternative MRI-based feature set that covers a much more extensive articulatory space than EMA. We also introduce normalization and denoising procedures to enhance the generalizability of deep learning methods trained on MRI data. Moreover, we propose an MRI-to-speech model that improves both computational efficiency and speech fidelity. Finally, through a series of ablations, we show that the proposed MRI representation is more comprehensive than EMA and identify the most suitable MRI feature subset for articulatory synthesis.
Speaker-Independent Acoustic-to-Articulatory Speech Inversion
Feb 14, 2023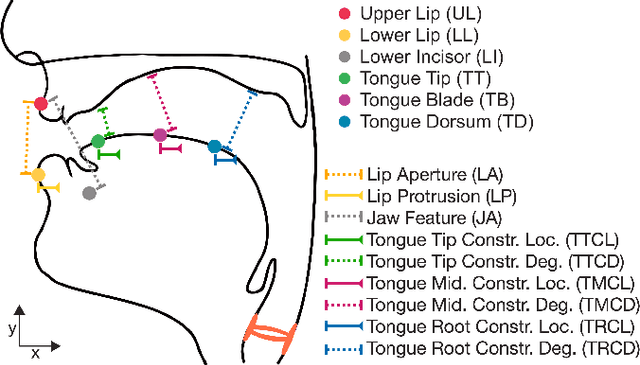
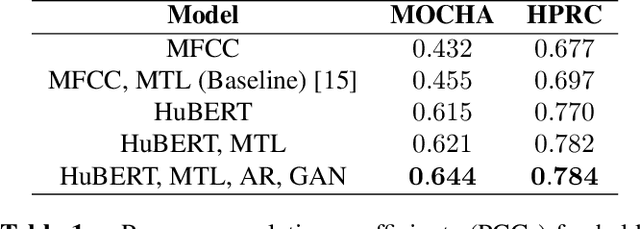
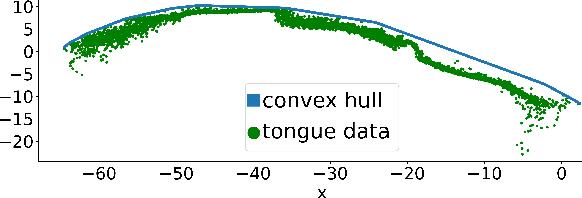

To build speech processing methods that can handle speech as naturally as humans, researchers have explored multiple ways of building an invertible mapping from speech to an interpretable space. The articulatory space is a promising inversion target, since this space captures the mechanics of speech production. To this end, we build an acoustic-to-articulatory inversion (AAI) model that leverages autoregression, adversarial training, and self supervision to generalize to unseen speakers. Our approach obtains 0.784 correlation on an electromagnetic articulography (EMA) dataset, improving the state-of-the-art by 12.5%. Additionally, we show the interpretability of these representations through directly comparing the behavior of estimated representations with speech production behavior. Finally, we propose a resynthesis-based AAI evaluation metric that does not rely on articulatory labels, demonstrating its efficacy with an 18-speaker dataset.
Articulatory Representation Learning Via Joint Factor Analysis and Neural Matrix Factorization
Oct 29, 2022


Articulatory representation learning is the fundamental research in modeling neural speech production system. Our previous work has established a deep paradigm to decompose the articulatory kinematics data into gestures, which explicitly model the phonological and linguistic structure encoded with human speech production mechanism, and corresponding gestural scores. We continue with this line of work by raising two concerns: (1) The articulators are entangled together in the original algorithm such that some of the articulators do not leverage effective moving patterns, which limits the interpretability of both gestures and gestural scores; (2) The EMA data is sparsely sampled from articulators, which limits the intelligibility of learned representations. In this work, we propose a novel articulatory representation decomposition algorithm that takes the advantage of guided factor analysis to derive the articulatory-specific factors and factor scores. A neural convolutive matrix factorization algorithm is then employed on the factor scores to derive the new gestures and gestural scores. We experiment with the rtMRI corpus that captures the fine-grained vocal tract contours. Both subjective and objective evaluation results suggest that the newly proposed system delivers the articulatory representations that are intelligible, generalizable, efficient and interpretable.
A Fast and Accurate Pitch Estimation Algorithm Based on the Pseudo Wigner-Ville Distribution
Oct 27, 2022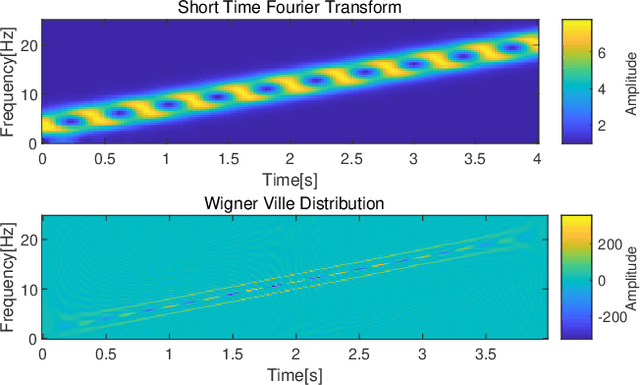

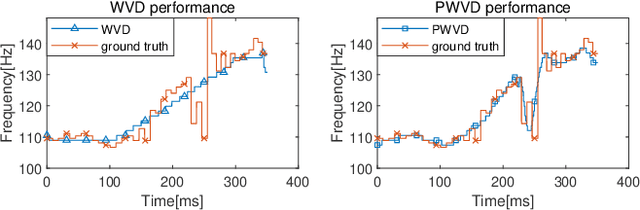
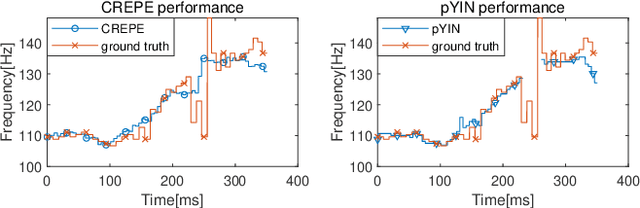
Estimation of fundamental frequency (F0) in voiced segments of speech signals, also known as pitch tracking, plays a crucial role in pitch synchronous speech analysis, speech synthesis, and speech manipulation. In this paper, we capitalize on the high time and frequency resolution of the pseudo Wigner-Ville distribution (PWVD) and propose a new PWVD-based pitch estimation method. We devise an efficient algorithm to compute PWVD faster and use cepstrum-based pre-filtering to avoid cross-term interference. Evaluating our approach on a database with speech and electroglottograph (EGG) recordings yields a state-of-the-art mean absolute error (MAE) of around 4Hz. Our approach is also effective at voiced/unvoiced classification and handling sudden frequency changes.
Deep Speech Synthesis from Articulatory Representations
Sep 13, 2022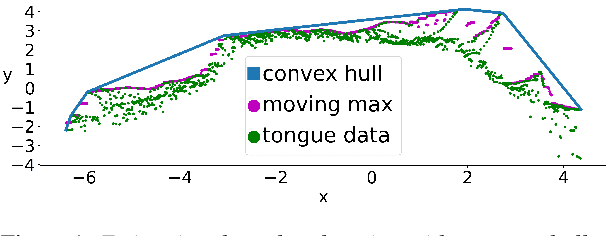

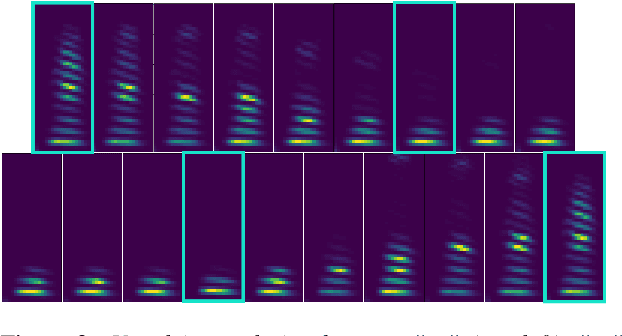
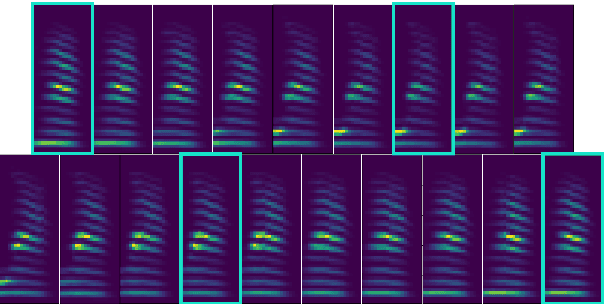
In the articulatory synthesis task, speech is synthesized from input features containing information about the physical behavior of the human vocal tract. This task provides a promising direction for speech synthesis research, as the articulatory space is compact, smooth, and interpretable. Current works have highlighted the potential for deep learning models to perform articulatory synthesis. However, it remains unclear whether these models can achieve the efficiency and fidelity of the human speech production system. To help bridge this gap, we propose a time-domain articulatory synthesis methodology and demonstrate its efficacy with both electromagnetic articulography (EMA) and synthetic articulatory feature inputs. Our model is computationally efficient and achieves a transcription word error rate (WER) of 18.5% for the EMA-to-speech task, yielding an improvement of 11.6% compared to prior work. Through interpolation experiments, we also highlight the generalizability and interpretability of our approach.