 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBohan Yu
Towards Streaming Speech-to-Avatar Synthesis
Oct 25, 2023
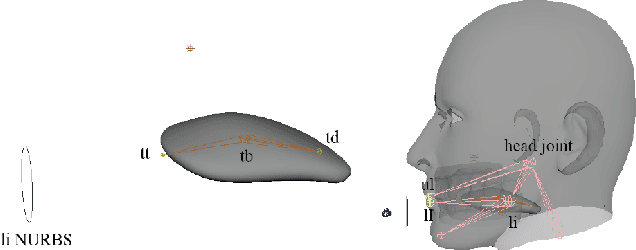
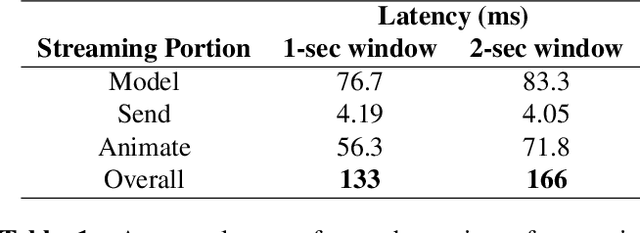
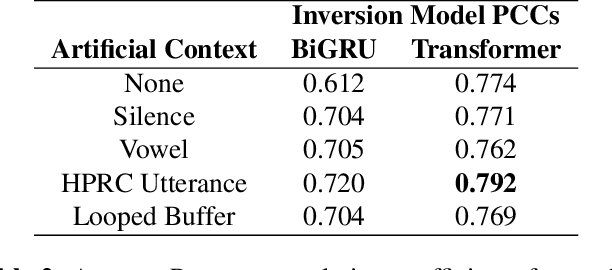

Streaming speech-to-avatar synthesis creates real-time animations for a virtual character from audio data. Accurate avatar representations of speech are important for the visualization of sound in linguistics, phonetics, and phonology, visual feedback to assist second language acquisition, and virtual embodiment for paralyzed patients. Previous works have highlighted the capability of deep articulatory inversion to perform high-quality avatar animation using electromagnetic articulography (EMA) features. However, these models focus on offline avatar synthesis with recordings rather than real-time audio, which is necessary for live avatar visualization or embodiment. To address this issue, we propose a method using articulatory inversion for streaming high quality facial and inner-mouth avatar animation from real-time audio. Our approach achieves 130ms average streaming latency for every 0.1 seconds of audio with a 0.792 correlation with ground truth articulations. Finally, we show generated mouth and tongue animations to demonstrate the efficacy of our methodology.
Towards an Interpretable Representation of Speaker Identity via Perceptual Voice Qualities
Oct 04, 2023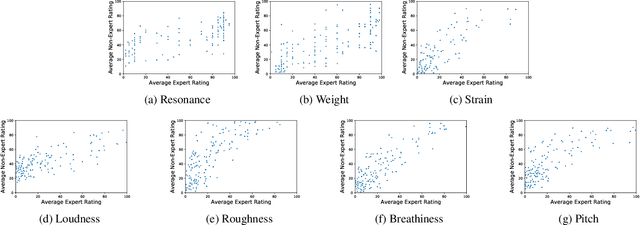

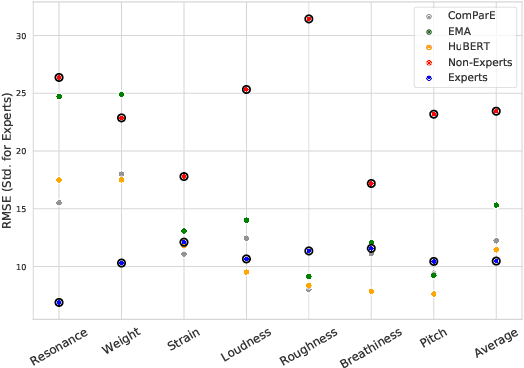
Unlike other data modalities such as text and vision, speech does not lend itself to easy interpretation. While lay people can understand how to describe an image or sentence via perception, non-expert descriptions of speech often end at high-level demographic information, such as gender or age. In this paper, we propose a possible interpretable representation of speaker identity based on perceptual voice qualities (PQs). By adding gendered PQs to the pathology-focused Consensus Auditory-Perceptual Evaluation of Voice (CAPE-V) protocol, our PQ-based approach provides a perceptual latent space of the character of adult voices that is an intermediary of abstraction between high-level demographics and low-level acoustic, physical, or learned representations. Contrary to prior belief, we demonstrate that these PQs are hearable by ensembles of non-experts, and further demonstrate that the information encoded in a PQ-based representation is predictable by various speech representations.
Delving into the Devils of Bird's-eye-view Perception: A Review, Evaluation and Recipe
Sep 12, 2022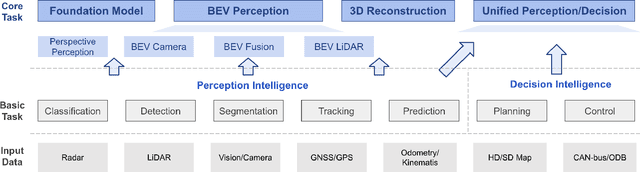
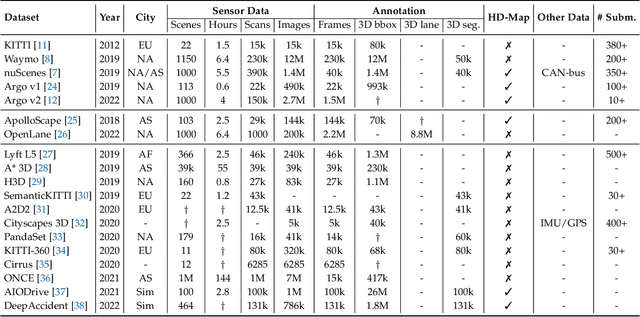
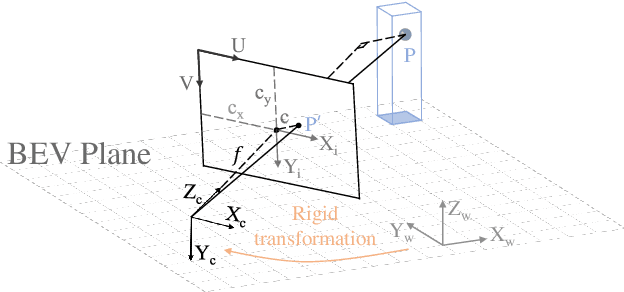
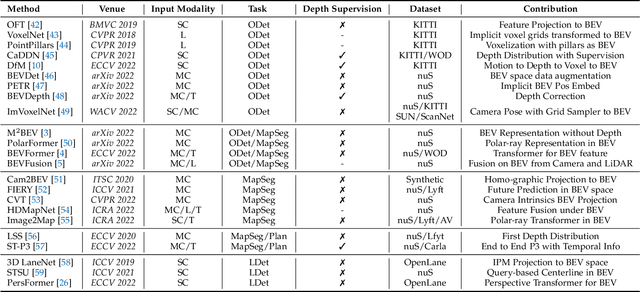
Learning powerful representations in bird's-eye-view (BEV) for perception tasks is trending and drawing extensive attention both from industry and academia. Conventional approaches for most autonomous driving algorithms perform detection, segmentation, tracking, etc., in a front or perspective view. As sensor configurations get more complex, integrating multi-source information from different sensors and representing features in a unified view come of vital importance. BEV perception inherits several advantages, as representing surrounding scenes in BEV is intuitive and fusion-friendly; and representing objects in BEV is most desirable for subsequent modules as in planning and/or control. The core problems for BEV perception lie in (a) how to reconstruct the lost 3D information via view transformation from perspective view to BEV; (b) how to acquire ground truth annotations in BEV grid; (c) how to formulate the pipeline to incorporate features from different sources and views; and (d) how to adapt and generalize algorithms as sensor configurations vary across different scenarios. In this survey, we review the most recent work on BEV perception and provide an in-depth analysis of different solutions. Moreover, several systematic designs of BEV approach from the industry are depicted as well. Furthermore, we introduce a full suite of practical guidebook to improve the performance of BEV perception tasks, including camera, LiDAR and fusion inputs. At last, we point out the future research directions in this area. We hope this report would shed some light on the community and encourage more research effort on BEV perception. We keep an active repository to collect the most recent work and provide a toolbox for bag of tricks at https://github.com/OpenPerceptionX/BEVPerception-Survey-Recipe.
Doctor Imitator: A Graph-based Bone Age Assessment Framework Using Hand Radiographs
Feb 10, 2021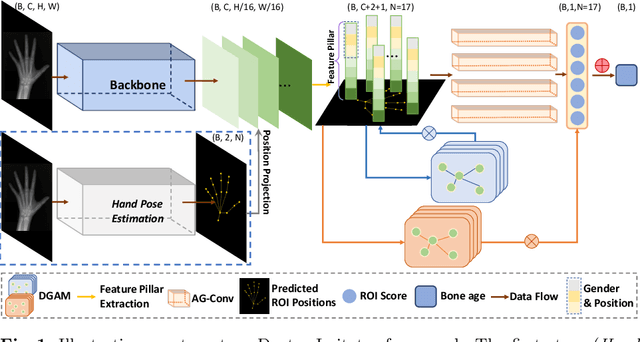


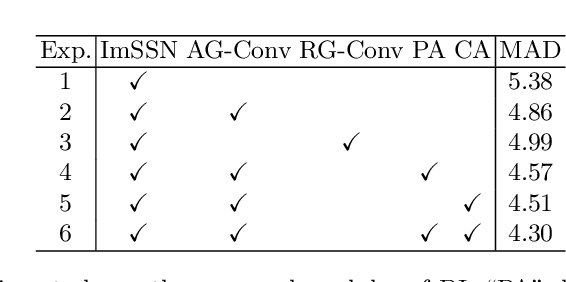
Bone age assessment is challenging in clinical practice due to the complicated bone age assessment process. Current automatic bone age assessment methods were designed with rare consideration of the diagnostic logistics and thus may yield certain uninterpretable hidden states and outputs. Consequently, doctors can find it hard to cooperate with such models harmoniously because it is difficult to check the correctness of the model predictions. In this work, we propose a new graph-based deep learning framework for bone age assessment with hand radiographs, called Doctor Imitator (DI). The architecture of DI is designed to learn the diagnostic logistics of doctors using the scoring methods (e.g., the Tanner-Whitehouse method) for bone age assessment. Specifically, the convolutions of DI capture the local features of the anatomical regions of interest (ROIs) on hand radiographs and predict the ROI scores by our proposed Anatomy-based Group Convolution, summing up for bone age prediction. Besides, we develop a novel Dual Graph-based Attention module to compute patient-specific attention for ROI features and context attention for ROI scores. As far as we know, DI is the first automatic bone age assessment framework following the scoring methods without fully supervised hand radiographs. Experiments on hand radiographs with only bone age supervision verify that DI can achieve excellent performance with sparse parameters and provide more interpretability.