 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuangyao Chen
Adaptive Discovering and Merging for Incremental Novel Class Discovery
Mar 06, 2024
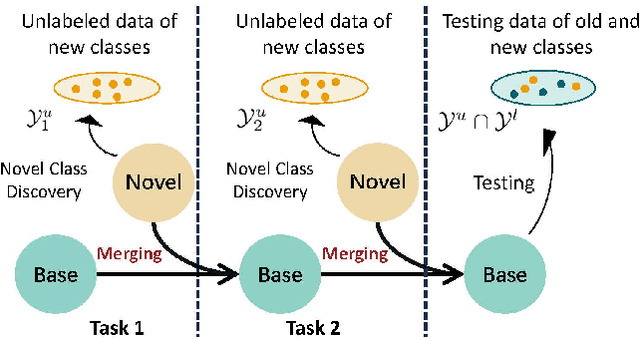
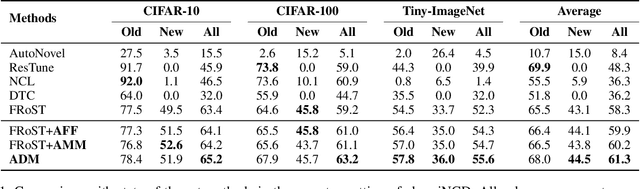
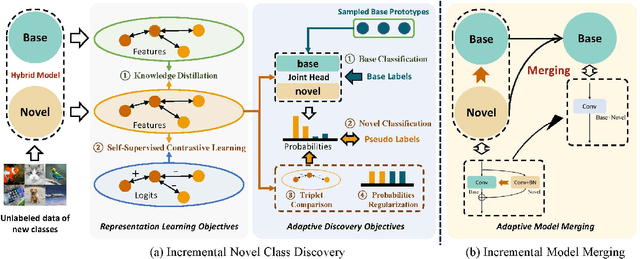
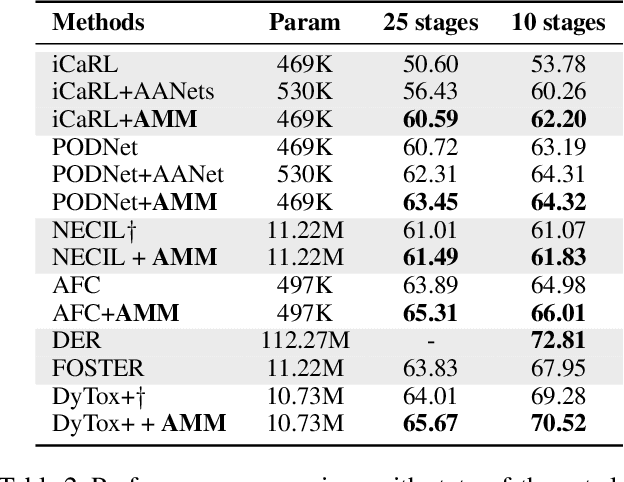
One important desideratum of lifelong learning aims to discover novel classes from unlabelled data in a continuous manner. The central challenge is twofold: discovering and learning novel classes while mitigating the issue of catastrophic forgetting of established knowledge. To this end, we introduce a new paradigm called Adaptive Discovering and Merging (ADM) to discover novel categories adaptively in the incremental stage and integrate novel knowledge into the model without affecting the original knowledge. To discover novel classes adaptively, we decouple representation learning and novel class discovery, and use Triple Comparison (TC) and Probability Regularization (PR) to constrain the probability discrepancy and diversity for adaptive category assignment. To merge the learned novel knowledge adaptively, we propose a hybrid structure with base and novel branches named Adaptive Model Merging (AMM), which reduces the interference of the novel branch on the old classes to preserve the previous knowledge, and merges the novel branch to the base model without performance loss and parameter growth. Extensive experiments on several datasets show that ADM significantly outperforms existing class-incremental Novel Class Discovery (class-iNCD) approaches. Moreover, our AMM also benefits the class-incremental Learning (class-IL) task by alleviating the catastrophic forgetting problem.
AutoAgents: A Framework for Automatic Agent Generation
Oct 15, 2023
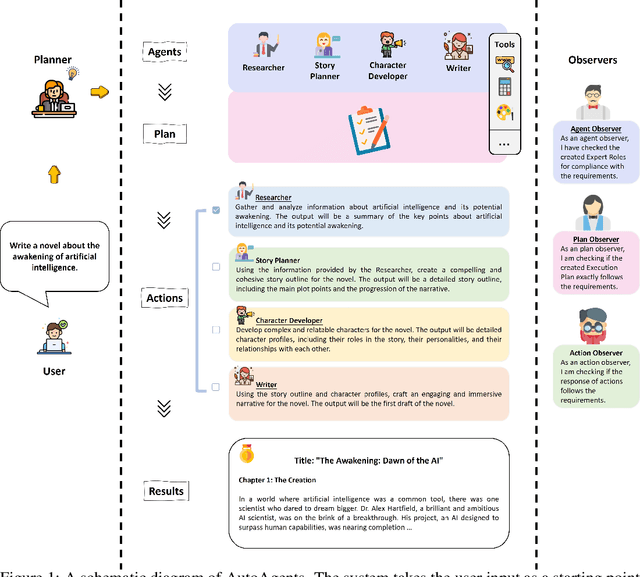
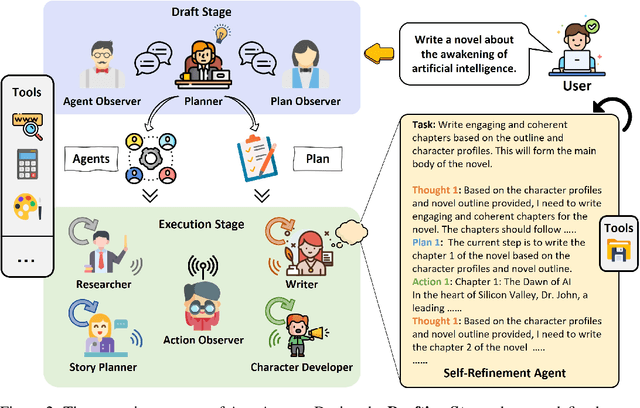

Large language models (LLMs) have enabled remarkable advances in automated task-solving with multi-agent systems. However, most existing LLM-based multi-agent approaches rely on predefined agents to handle simple tasks, limiting the adaptability of multi-agent collaboration to different scenarios. Therefore, we introduce AutoAgents, an innovative framework that adaptively generates and coordinates multiple specialized agents to build an AI team according to different tasks. Specifically, AutoAgents couples the relationship between tasks and roles by dynamically generating multiple required agents based on task content and planning solutions for the current task based on the generated expert agents. Multiple specialized agents collaborate with each other to efficiently accomplish tasks. Concurrently, an observer role is incorporated into the framework to reflect on the designated plans and agents' responses and improve upon them. Our experiments on various benchmarks demonstrate that AutoAgents generates more coherent and accurate solutions than the existing multi-agent methods. This underscores the significance of assigning different roles to different tasks and of team cooperation, offering new perspectives for tackling complex tasks. The repository of this project is available at https://github.com/Link-AGI/AutoAgents.
LLaSM: Large Language and Speech Model
Sep 16, 2023



Multi-modal large language models have garnered significant interest recently. Though, most of the works focus on vision-language multi-modal models providing strong capabilities in following vision-and-language instructions. However, we claim that speech is also an important modality through which humans interact with the world. Hence, it is crucial for a general-purpose assistant to be able to follow multi-modal speech-and-language instructions. In this work, we propose Large Language and Speech Model (LLaSM). LLaSM is an end-to-end trained large multi-modal speech-language model with cross-modal conversational abilities, capable of following speech-and-language instructions. Our early experiments show that LLaSM demonstrates a more convenient and natural way for humans to interact with artificial intelligence. Specifically, we also release a large Speech Instruction Following dataset LLaSM-Audio-Instructions. Code and demo are available at https://github.com/LinkSoul-AI/LLaSM and https://huggingface.co/spaces/LinkSoul/LLaSM. The LLaSM-Audio-Instructions dataset is available at https://huggingface.co/datasets/LinkSoul/LLaSM-Audio-Instructions.
Learning Sparse Neural Networks with Identity Layers
Jul 14, 2023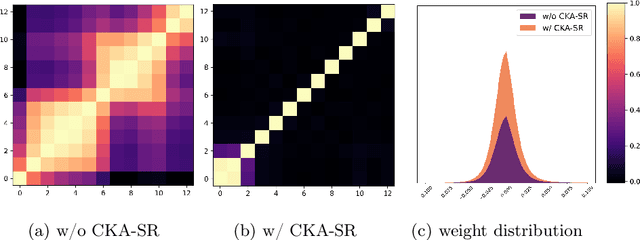
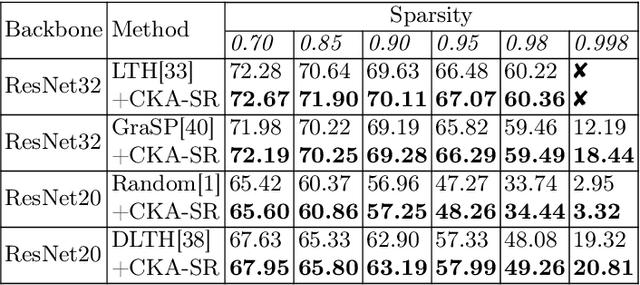
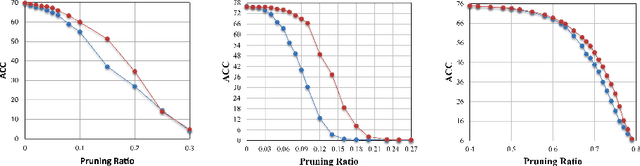

The sparsity of Deep Neural Networks is well investigated to maximize the performance and reduce the size of overparameterized networks as possible. Existing methods focus on pruning parameters in the training process by using thresholds and metrics. Meanwhile, feature similarity between different layers has not been discussed sufficiently before, which could be rigorously proved to be highly correlated to the network sparsity in this paper. Inspired by interlayer feature similarity in overparameterized models, we investigate the intrinsic link between network sparsity and interlayer feature similarity. Specifically, we prove that reducing interlayer feature similarity based on Centered Kernel Alignment (CKA) improves the sparsity of the network by using information bottleneck theory. Applying such theory, we propose a plug-and-play CKA-based Sparsity Regularization for sparse network training, dubbed CKA-SR, which utilizes CKA to reduce feature similarity between layers and increase network sparsity. In other words, layers of our sparse network tend to have their own identity compared to each other. Experimentally, we plug the proposed CKA-SR into the training process of sparse network training methods and find that CKA-SR consistently improves the performance of several State-Of-The-Art sparse training methods, especially at extremely high sparsity. Code is included in the supplementary materials.
Picking Up Quantization Steps for Compressed Image Classification
Apr 21, 2023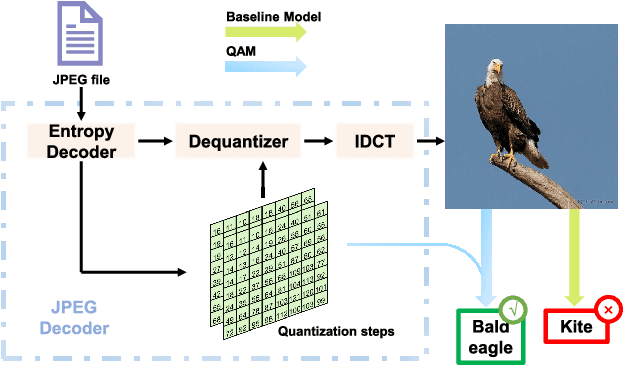
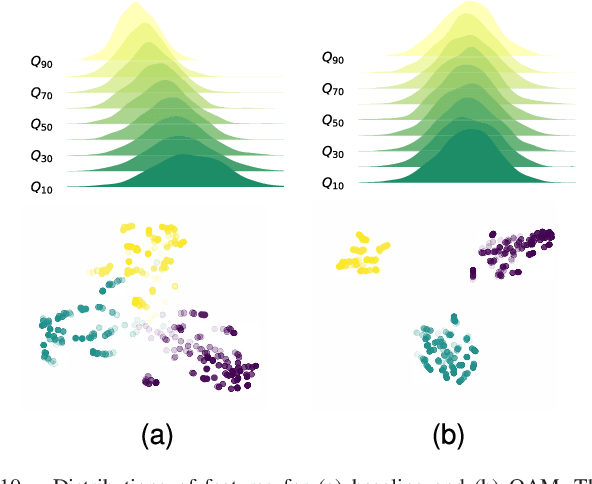

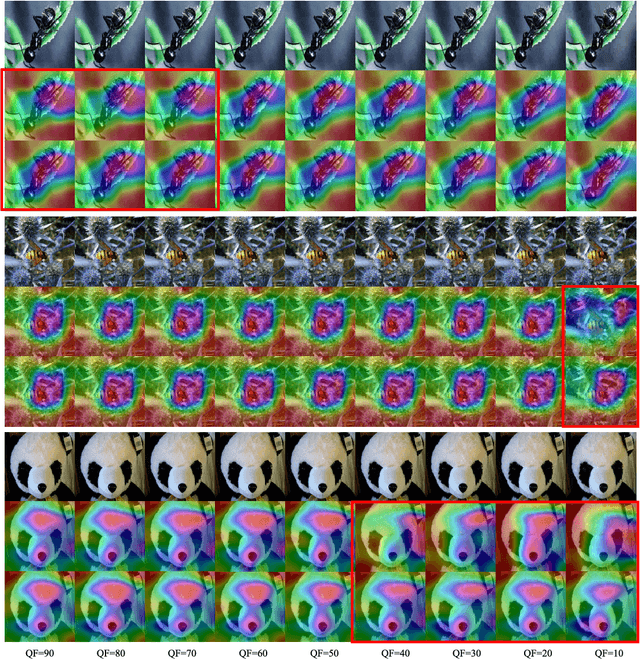
The sensitivity of deep neural networks to compressed images hinders their usage in many real applications, which means classification networks may fail just after taking a screenshot and saving it as a compressed file. In this paper, we argue that neglected disposable coding parameters stored in compressed files could be picked up to reduce the sensitivity of deep neural networks to compressed images. Specifically, we resort to using one of the representative parameters, quantization steps, to facilitate image classification. Firstly, based on quantization steps, we propose a novel quantization aware confidence (QAC), which is utilized as sample weights to reduce the influence of quantization on network training. Secondly, we utilize quantization steps to alleviate the variance of feature distributions, where a quantization aware batch normalization (QABN) is proposed to replace batch normalization of classification networks. Extensive experiments show that the proposed method significantly improves the performance of classification networks on CIFAR-10, CIFAR-100, and ImageNet. The code is released on https://github.com/LiMaPKU/QSAM.git
Large-scale Multi-Modal Pre-trained Models: A Comprehensive Survey
Feb 20, 2023
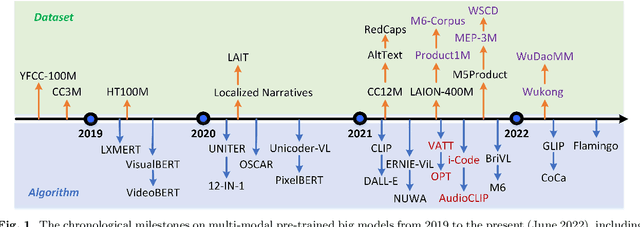


With the urgent demand for generalized deep models, many pre-trained big models are proposed, such as BERT, ViT, GPT, etc. Inspired by the success of these models in single domains (like computer vision and natural language processing), the multi-modal pre-trained big models have also drawn more and more attention in recent years. In this work, we give a comprehensive survey of these models and hope this paper could provide new insights and helps fresh researchers to track the most cutting-edge works. Specifically, we firstly introduce the background of multi-modal pre-training by reviewing the conventional deep learning, pre-training works in natural language process, computer vision, and speech. Then, we introduce the task definition, key challenges, and advantages of multi-modal pre-training models (MM-PTMs), and discuss the MM-PTMs with a focus on data, objectives, network architectures, and knowledge enhanced pre-training. After that, we introduce the downstream tasks used for the validation of large-scale MM-PTMs, including generative, classification, and regression tasks. We also give visualization and analysis of the model parameters and results on representative downstream tasks. Finally, we point out possible research directions for this topic that may benefit future works. In addition, we maintain a continuously updated paper list for large-scale pre-trained multi-modal big models: https://github.com/wangxiao5791509/MultiModal_BigModels_Survey
Training Full Spike Neural Networks via Auxiliary Accumulation Pathway
Jan 27, 2023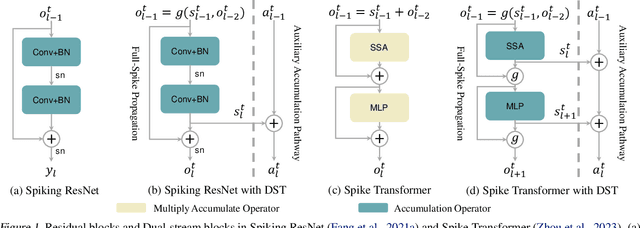

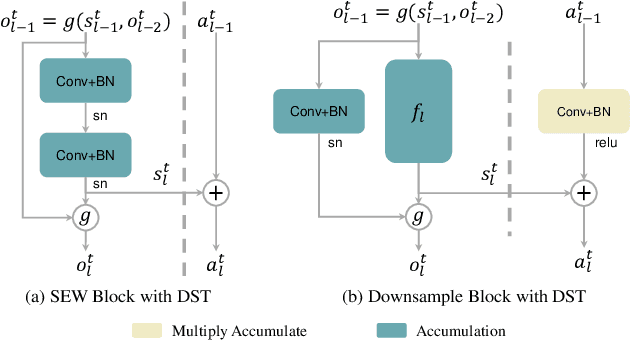
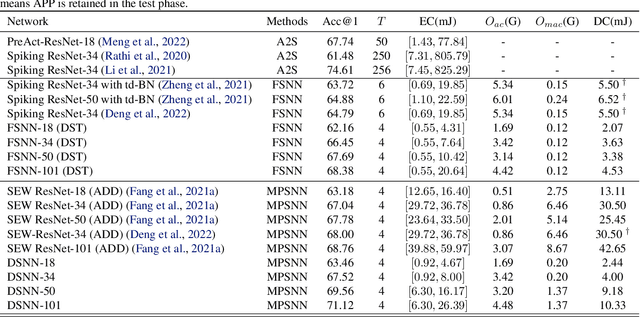
Due to the binary spike signals making converting the traditional high-power multiply-accumulation (MAC) into a low-power accumulation (AC) available, the brain-inspired Spiking Neural Networks (SNNs) are gaining more and more attention. However, the binary spike propagation of the Full-Spike Neural Networks (FSNN) with limited time steps is prone to significant information loss. To improve performance, several state-of-the-art SNN models trained from scratch inevitably bring many non-spike operations. The non-spike operations cause additional computational consumption and may not be deployed on some neuromorphic hardware where only spike operation is allowed. To train a large-scale FSNN with high performance, this paper proposes a novel Dual-Stream Training (DST) method which adds a detachable Auxiliary Accumulation Pathway (AAP) to the full spiking residual networks. The accumulation in AAP could compensate for the information loss during the forward and backward of full spike propagation, and facilitate the training of the FSNN. In the test phase, the AAP could be removed and only the FSNN remained. This not only keeps the lower energy consumption but also makes our model easy to deploy. Moreover, for some cases where the non-spike operations are available, the APP could also be retained in test inference and improve feature discrimination by introducing a little non-spike consumption. Extensive experiments on ImageNet, DVS Gesture, and CIFAR10-DVS datasets demonstrate the effectiveness of DST.
OpenOOD: Benchmarking Generalized Out-of-Distribution Detection
Oct 13, 2022
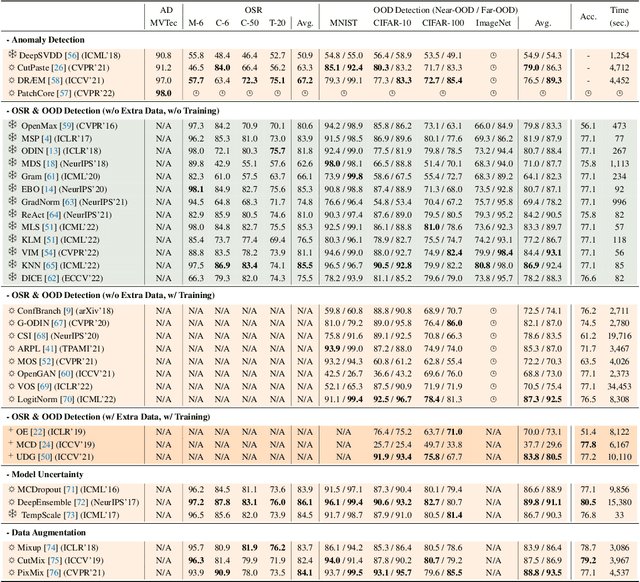
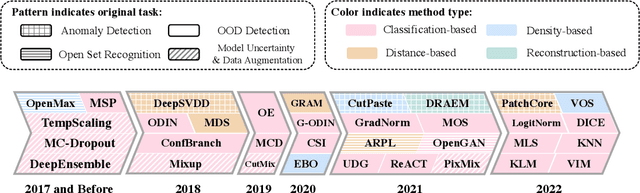
Out-of-distribution (OOD) detection is vital to safety-critical machine learning applications and has thus been extensively studied, with a plethora of methods developed in the literature. However, the field currently lacks a unified, strictly formulated, and comprehensive benchmark, which often results in unfair comparisons and inconclusive results. From the problem setting perspective, OOD detection is closely related to neighboring fields including anomaly detection (AD), open set recognition (OSR), and model uncertainty, since methods developed for one domain are often applicable to each other. To help the community to improve the evaluation and advance, we build a unified, well-structured codebase called OpenOOD, which implements over 30 methods developed in relevant fields and provides a comprehensive benchmark under the recently proposed generalized OOD detection framework. With a comprehensive comparison of these methods, we are gratified that the field has progressed significantly over the past few years, where both preprocessing methods and the orthogonal post-hoc methods show strong potential.
Amplitude-Phase Recombination: Rethinking Robustness of Convolutional Neural Networks in Frequency Domain
Aug 19, 2021



Recently, the generalization behavior of Convolutional Neural Networks (CNN) is gradually transparent through explanation techniques with the frequency components decomposition. However, the importance of the phase spectrum of the image for a robust vision system is still ignored. In this paper, we notice that the CNN tends to converge at the local optimum which is closely related to the high-frequency components of the training images, while the amplitude spectrum is easily disturbed such as noises or common corruptions. In contrast, more empirical studies found that humans rely on more phase components to achieve robust recognition. This observation leads to more explanations of the CNN's generalization behaviors in both robustness to common perturbations and out-of-distribution detection, and motivates a new perspective on data augmentation designed by re-combing the phase spectrum of the current image and the amplitude spectrum of the distracter image. That is, the generated samples force the CNN to pay more attention to the structured information from phase components and keep robust to the variation of the amplitude. Experiments on several image datasets indicate that the proposed method achieves state-of-the-art performances on multiple generalizations and calibration tasks, including adaptability for common corruptions and surface variations, out-of-distribution detection, and adversarial attack.
Adversarial Reciprocal Points Learning for Open Set Recognition
Mar 02, 2021



Open set recognition (OSR), aiming to simultaneously classify the seen classes and identify the unseen classes as 'unknown', is essential for reliable machine learning.The key challenge of OSR is how to reduce the empirical classification risk on the labeled known data and the open space risk on the potential unknown data simultaneously. To handle the challenge, we formulate the open space risk problem from the perspective of multi-class integration, and model the unexploited extra-class space with a novel concept Reciprocal Point. Follow this, a novel learning framework, termed Adversarial Reciprocal Point Learning (ARPL), is proposed to minimize the overlap of known distribution and unknown distributions without loss of known classification accuracy. Specifically, each reciprocal point is learned by the extra-class space with the corresponding known category, and the confrontation among multiple known categories are employed to reduce the empirical classification risk. Then, an adversarial margin constraint is proposed to reduce the open space risk by limiting the latent open space constructed by reciprocal points. To further estimate the unknown distribution from open space, an instantiated adversarial enhancement method is designed to generate diverse and confusing training samples, based on the adversarial mechanism between the reciprocal points and known classes. This can effectively enhance the model distinguishability to the unknown classes. Extensive experimental results on various benchmark datasets indicate that the proposed method is significantly superior to other existing approaches and achieves state-of-the-art performance.