 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuanying Chen
SphereHead: Stable 3D Full-head Synthesis with Spherical Tri-plane Representation
Apr 08, 2024
While recent advances in 3D-aware Generative Adversarial Networks (GANs) have aided the development of near-frontal view human face synthesis, the challenge of comprehensively synthesizing a full 3D head viewable from all angles still persists. Although PanoHead proves the possibilities of using a large-scale dataset with images of both frontal and back views for full-head synthesis, it often causes artifacts for back views. Based on our in-depth analysis, we found the reasons are mainly twofold. First, from network architecture perspective, we found each plane in the utilized tri-plane/tri-grid representation space tends to confuse the features from both sides, causing "mirroring" artifacts (e.g., the glasses appear in the back). Second, from data supervision aspect, we found that existing discriminator training in 3D GANs mainly focuses on the quality of the rendered image itself, and does not care much about its plausibility with the perspective from which it was rendered. This makes it possible to generate "face" in non-frontal views, due to its easiness to fool the discriminator. In response, we propose SphereHead, a novel tri-plane representation in the spherical coordinate system that fits the human head's geometric characteristics and efficiently mitigates many of the generated artifacts. We further introduce a view-image consistency loss for the discriminator to emphasize the correspondence of the camera parameters and the images. The combination of these efforts results in visually superior outcomes with significantly fewer artifacts. Our code and dataset are publicly available at https://lhyfst.github.io/spherehead.
Aerial Lifting: Neural Urban Semantic and Building Instance Lifting from Aerial Imagery
Mar 18, 2024
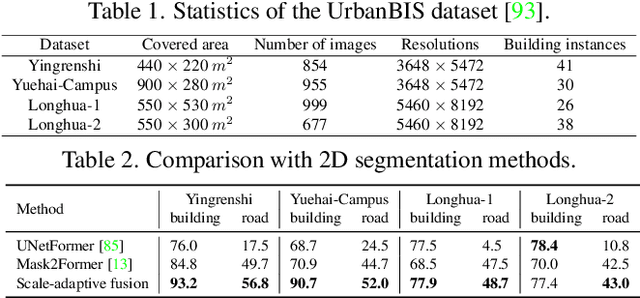
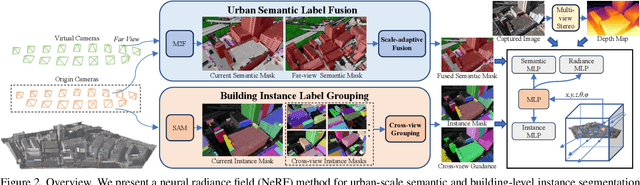

We present a neural radiance field method for urban-scale semantic and building-level instance segmentation from aerial images by lifting noisy 2D labels to 3D. This is a challenging problem due to two primary reasons. Firstly, objects in urban aerial images exhibit substantial variations in size, including buildings, cars, and roads, which pose a significant challenge for accurate 2D segmentation. Secondly, the 2D labels generated by existing segmentation methods suffer from the multi-view inconsistency problem, especially in the case of aerial images, where each image captures only a small portion of the entire scene. To overcome these limitations, we first introduce a scale-adaptive semantic label fusion strategy that enhances the segmentation of objects of varying sizes by combining labels predicted from different altitudes, harnessing the novel-view synthesis capabilities of NeRF. We then introduce a novel cross-view instance label grouping strategy based on the 3D scene representation to mitigate the multi-view inconsistency problem in the 2D instance labels. Furthermore, we exploit multi-view reconstructed depth priors to improve the geometric quality of the reconstructed radiance field, resulting in enhanced segmentation results. Experiments on multiple real-world urban-scale datasets demonstrate that our approach outperforms existing methods, highlighting its effectiveness.
OMG: Occlusion-friendly Personalized Multi-concept Generation in Diffusion Models
Mar 16, 2024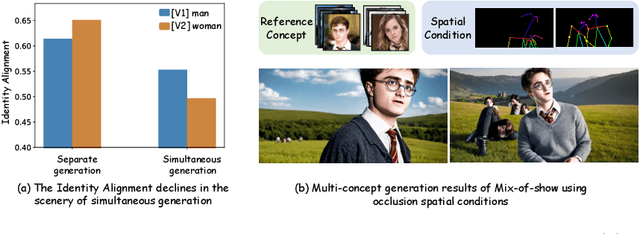
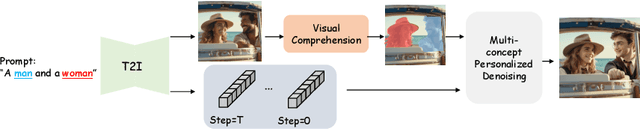
Personalization is an important topic in text-to-image generation, especially the challenging multi-concept personalization. Current multi-concept methods are struggling with identity preservation, occlusion, and the harmony between foreground and background. In this work, we propose OMG, an occlusion-friendly personalized generation framework designed to seamlessly integrate multiple concepts within a single image. We propose a novel two-stage sampling solution. The first stage takes charge of layout generation and visual comprehension information collection for handling occlusions. The second one utilizes the acquired visual comprehension information and the designed noise blending to integrate multiple concepts while considering occlusions. We also observe that the initiation denoising timestep for noise blending is the key to identity preservation and layout. Moreover, our method can be combined with various single-concept models, such as LoRA and InstantID without additional tuning. Especially, LoRA models on civitai.com can be exploited directly. Extensive experiments demonstrate that OMG exhibits superior performance in multi-concept personalization.
MOC-RVQ: Multilevel Codebook-assisted Digital Generative Semantic Communication
Jan 02, 2024Vector quantization-based image semantic communication systems have successfully boosted transmission efficiency, but face a challenge with conflicting requirements between codebook design and digital constellation modulation. Traditional codebooks need a wide index range, while modulation favors few discrete states. To address this, we propose a multilevel generative semantic communication system with a two-stage training framework. In the first stage, we train a high-quality codebook, using a multi-head octonary codebook (MOC) to compress the index range. We also integrate a residual vector quantization (RVQ) mechanism for effective multilevel communication. In the second stage, a noise reduction block (NRB) based on Swin Transformer is introduced, coupled with the multilevel codebook from the first stage, serving as a high-quality semantic knowledge base (SKB) for generative feature restoration. Experimental results highlight MOC-RVQ's superior performance over methods like BPG or JPEG, even without channel error correction coding.
RichDreamer: A Generalizable Normal-Depth Diffusion Model for Detail Richness in Text-to-3D
Nov 28, 2023Lifting 2D diffusion for 3D generation is a challenging problem due to the lack of geometric prior and the complex entanglement of materials and lighting in natural images. Existing methods have shown promise by first creating the geometry through score-distillation sampling (SDS) applied to rendered surface normals, followed by appearance modeling. However, relying on a 2D RGB diffusion model to optimize surface normals is suboptimal due to the distribution discrepancy between natural images and normals maps, leading to instability in optimization. In this paper, recognizing that the normal and depth information effectively describe scene geometry and be automatically estimated from images, we propose to learn a generalizable Normal-Depth diffusion model for 3D generation. We achieve this by training on the large-scale LAION dataset together with the generalizable image-to-depth and normal prior models. In an attempt to alleviate the mixed illumination effects in the generated materials, we introduce an albedo diffusion model to impose data-driven constraints on the albedo component. Our experiments show that when integrated into existing text-to-3D pipelines, our models significantly enhance the detail richness, achieving state-of-the-art results. Our project page is https://lingtengqiu.github.io/RichDreamer/.
Knowledge Base Enabled Semantic Communication: A Generative Perspective
Nov 21, 2023Semantic communication is widely touted as a key technology for propelling the sixth-generation (6G) wireless networks. However, providing effective semantic representation is quite challenging in practice. To address this issue, this article takes a crack at exploiting semantic knowledge base (KB) to usher in a new era of generative semantic communication. Via semantic KB, source messages can be characterized in low-dimensional subspaces without compromising their desired meaning, thus significantly enhancing the communication efficiency. The fundamental principle of semantic KB is first introduced, and a generative semantic communication architecture is developed by presenting three sub-KBs, namely source, task, and channel KBs. Then, the detailed construction approaches for each sub-KB are described, followed by their utilization in terms of semantic coding and transmission. A case study is also provided to showcase the superiority of generative semantic communication over conventional syntactic communication and classical semantic communication. In a nutshell, this article establishes a scientific foundation for the exciting uncharted frontier of generative semantic communication.
Forward Flow for Novel View Synthesis of Dynamic Scenes
Sep 29, 2023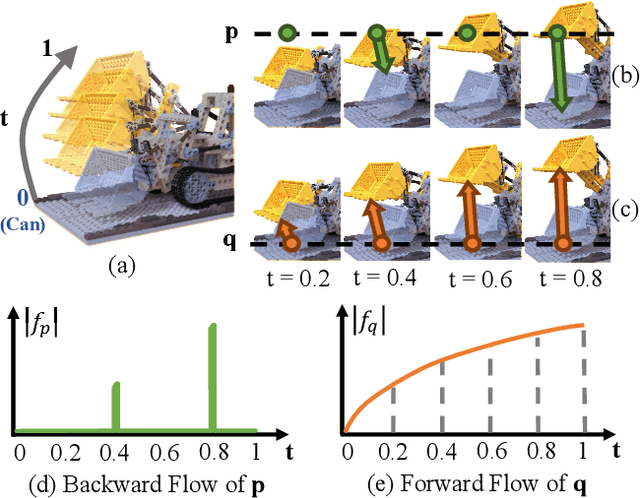
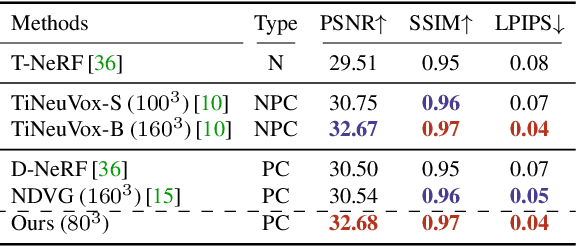
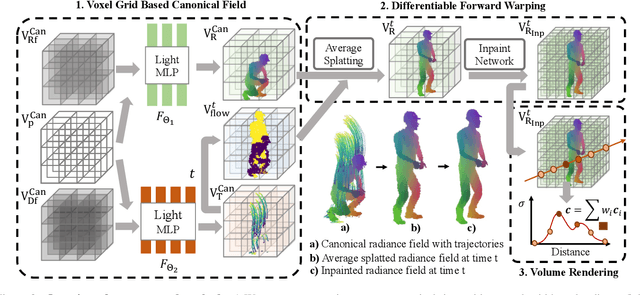
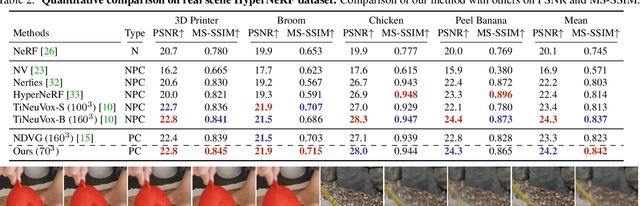
This paper proposes a neural radiance field (NeRF) approach for novel view synthesis of dynamic scenes using forward warping. Existing methods often adopt a static NeRF to represent the canonical space, and render dynamic images at other time steps by mapping the sampled 3D points back to the canonical space with the learned backward flow field. However, this backward flow field is non-smooth and discontinuous, which is difficult to be fitted by commonly used smooth motion models. To address this problem, we propose to estimate the forward flow field and directly warp the canonical radiance field to other time steps. Such forward flow field is smooth and continuous within the object region, which benefits the motion model learning. To achieve this goal, we represent the canonical radiance field with voxel grids to enable efficient forward warping, and propose a differentiable warping process, including an average splatting operation and an inpaint network, to resolve the many-to-one and one-to-many mapping issues. Thorough experiments show that our method outperforms existing methods in both novel view rendering and motion modeling, demonstrating the effectiveness of our forward flow motion modeling. Project page: https://npucvr.github.io/ForwardFlowDNeRF
* Accepted by ICCV2023 as oral. Project page: https://npucvr.github.io/ForwardFlowDNeRF
REC-MV: REconstructing 3D Dynamic Cloth from Monocular Videos
May 23, 2023


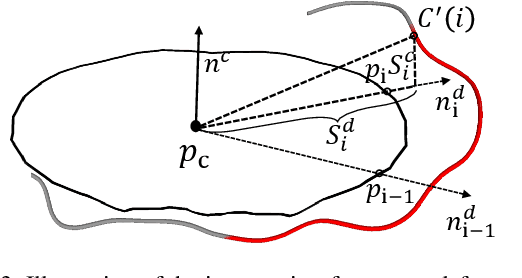
Reconstructing dynamic 3D garment surfaces with open boundaries from monocular videos is an important problem as it provides a practical and low-cost solution for clothes digitization. Recent neural rendering methods achieve high-quality dynamic clothed human reconstruction results from monocular video, but these methods cannot separate the garment surface from the body. Moreover, despite existing garment reconstruction methods based on feature curve representation demonstrating impressive results for garment reconstruction from a single image, they struggle to generate temporally consistent surfaces for the video input. To address the above limitations, in this paper, we formulate this task as an optimization problem of 3D garment feature curves and surface reconstruction from monocular video. We introduce a novel approach, called REC-MV, to jointly optimize the explicit feature curves and the implicit signed distance field (SDF) of the garments. Then the open garment meshes can be extracted via garment template registration in the canonical space. Experiments on multiple casually captured datasets show that our approach outperforms existing methods and can produce high-quality dynamic garment surfaces. The source code is available at https://github.com/GAP-LAB-CUHK-SZ/REC-MV.
MVImgNet: A Large-scale Dataset of Multi-view Images
Mar 10, 2023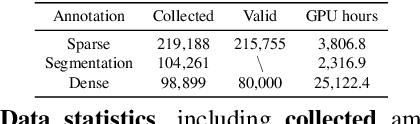
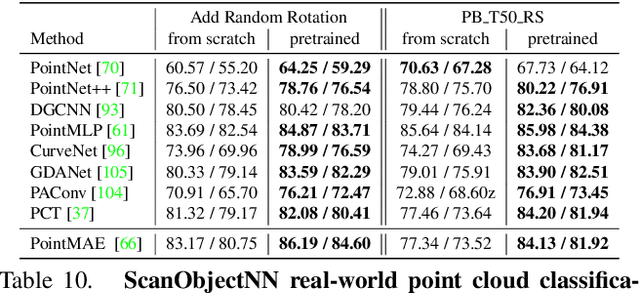
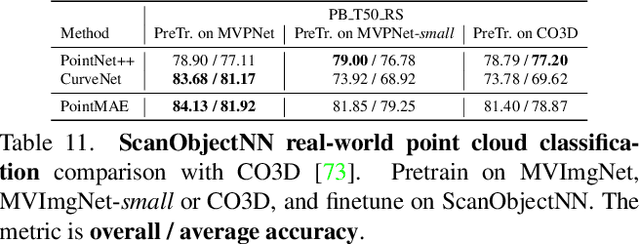

Being data-driven is one of the most iconic properties of deep learning algorithms. The birth of ImageNet drives a remarkable trend of "learning from large-scale data" in computer vision. Pretraining on ImageNet to obtain rich universal representations has been manifested to benefit various 2D visual tasks, and becomes a standard in 2D vision. However, due to the laborious collection of real-world 3D data, there is yet no generic dataset serving as a counterpart of ImageNet in 3D vision, thus how such a dataset can impact the 3D community is unraveled. To remedy this defect, we introduce MVImgNet, a large-scale dataset of multi-view images, which is highly convenient to gain by shooting videos of real-world objects in human daily life. It contains 6.5 million frames from 219,188 videos crossing objects from 238 classes, with rich annotations of object masks, camera parameters, and point clouds. The multi-view attribute endows our dataset with 3D-aware signals, making it a soft bridge between 2D and 3D vision. We conduct pilot studies for probing the potential of MVImgNet on a variety of 3D and 2D visual tasks, including radiance field reconstruction, multi-view stereo, and view-consistent image understanding, where MVImgNet demonstrates promising performance, remaining lots of possibilities for future explorations. Besides, via dense reconstruction on MVImgNet, a 3D object point cloud dataset is derived, called MVPNet, covering 87,200 samples from 150 categories, with the class label on each point cloud. Experiments show that MVPNet can benefit the real-world 3D object classification while posing new challenges to point cloud understanding. MVImgNet and MVPNet will be publicly available, hoping to inspire the broader vision community.
Efficient Large-scale Scene Representation with a Hybrid of High-resolution Grid and Plane Features
Mar 07, 2023



Existing neural radiance fields (NeRF) methods for large-scale scene modeling require days of training using multiple GPUs, hindering their applications in scenarios with limited computing resources. Despite fast optimization NeRF variants have been proposed based on the explicit dense or hash grid features, their effectivenesses are mainly demonstrated in object-scale scene representation. In this paper, we point out that the low feature resolution in explicit representation is the bottleneck for large-scale unbounded scene representation. To address this problem, we introduce a new and efficient hybrid feature representation for NeRF that fuses the 3D hash-grids and high-resolution 2D dense plane features. Compared with the dense-grid representation, the resolution of a dense 2D plane can be scaled up more efficiently. Based on this hybrid representation, we propose a fast optimization NeRF variant, called GP-NeRF, that achieves better rendering results while maintaining a compact model size. Extensive experiments on multiple large-scale unbounded scene datasets show that our model can converge in 1.5 hours using a single GPU while achieving results comparable to or even better than the existing method that requires about one day's training with 8 GPUs.