 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXiao Tan
Decoupled Pseudo-labeling for Semi-Supervised Monocular 3D Object Detection
Mar 26, 2024
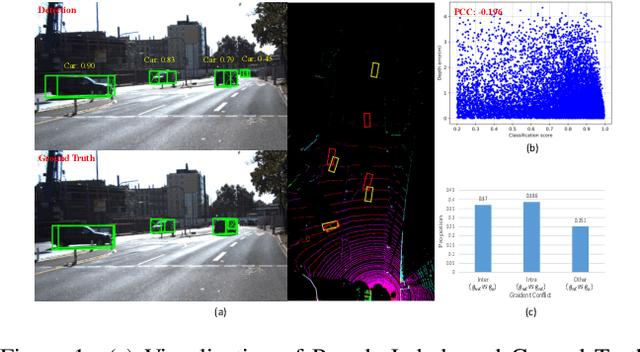
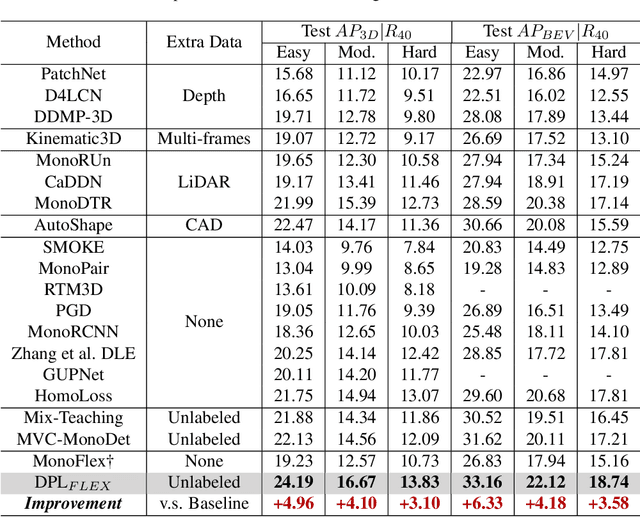
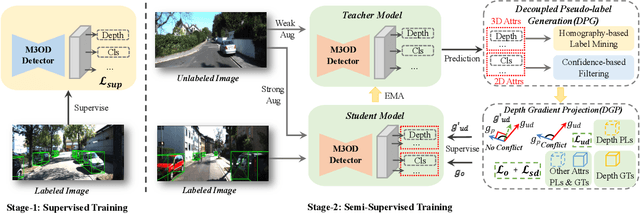

We delve into pseudo-labeling for semi-supervised monocular 3D object detection (SSM3OD) and discover two primary issues: a misalignment between the prediction quality of 3D and 2D attributes and the tendency of depth supervision derived from pseudo-labels to be noisy, leading to significant optimization conflicts with other reliable forms of supervision. We introduce a novel decoupled pseudo-labeling (DPL) approach for SSM3OD. Our approach features a Decoupled Pseudo-label Generation (DPG) module, designed to efficiently generate pseudo-labels by separately processing 2D and 3D attributes. This module incorporates a unique homography-based method for identifying dependable pseudo-labels in BEV space, specifically for 3D attributes. Additionally, we present a DepthGradient Projection (DGP) module to mitigate optimization conflicts caused by noisy depth supervision of pseudo-labels, effectively decoupling the depth gradient and removing conflicting gradients. This dual decoupling strategy-at both the pseudo-label generation and gradient levels-significantly improves the utilization of pseudo-labels in SSM3OD. Our comprehensive experiments on the KITTI benchmark demonstrate the superiority of our method over existing approaches.
Gradient-based Sampling for Class Imbalanced Semi-supervised Object Detection
Mar 22, 2024Current semi-supervised object detection (SSOD) algorithms typically assume class balanced datasets (PASCAL VOC etc.) or slightly class imbalanced datasets (MS-COCO, etc). This assumption can be easily violated since real world datasets can be extremely class imbalanced in nature, thus making the performance of semi-supervised object detectors far from satisfactory. Besides, the research for this problem in SSOD is severely under-explored. To bridge this research gap, we comprehensively study the class imbalance problem for SSOD under more challenging scenarios, thus forming the first experimental setting for class imbalanced SSOD (CI-SSOD). Moreover, we propose a simple yet effective gradient-based sampling framework that tackles the class imbalance problem from the perspective of two types of confirmation biases. To tackle confirmation bias towards majority classes, the gradient-based reweighting and gradient-based thresholding modules leverage the gradients from each class to fully balance the influence of the majority and minority classes. To tackle the confirmation bias from incorrect pseudo labels of minority classes, the class-rebalancing sampling module resamples unlabeled data following the guidance of the gradient-based reweighting module. Experiments on three proposed sub-tasks, namely MS-COCO, MS-COCO to Object365 and LVIS, suggest that our method outperforms current class imbalanced object detectors by clear margins, serving as a baseline for future research in CI-SSOD. Code will be available at https://github.com/nightkeepers/CI-SSOD.
Forward Flow for Novel View Synthesis of Dynamic Scenes
Sep 29, 2023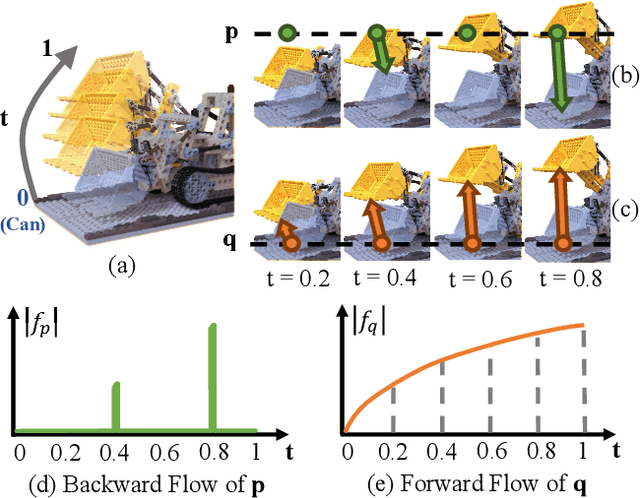
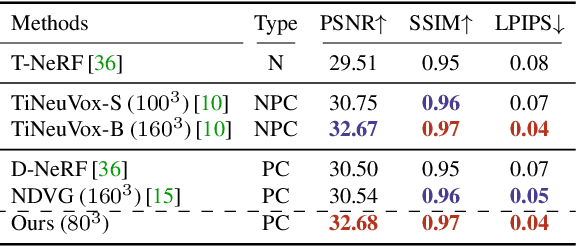
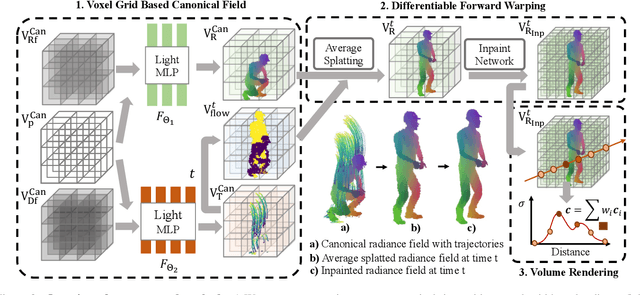
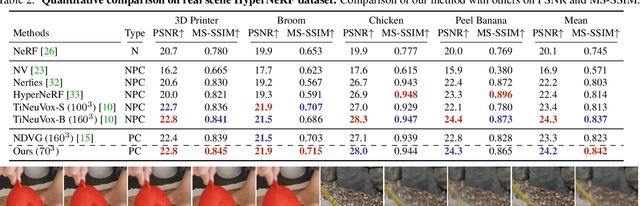
This paper proposes a neural radiance field (NeRF) approach for novel view synthesis of dynamic scenes using forward warping. Existing methods often adopt a static NeRF to represent the canonical space, and render dynamic images at other time steps by mapping the sampled 3D points back to the canonical space with the learned backward flow field. However, this backward flow field is non-smooth and discontinuous, which is difficult to be fitted by commonly used smooth motion models. To address this problem, we propose to estimate the forward flow field and directly warp the canonical radiance field to other time steps. Such forward flow field is smooth and continuous within the object region, which benefits the motion model learning. To achieve this goal, we represent the canonical radiance field with voxel grids to enable efficient forward warping, and propose a differentiable warping process, including an average splatting operation and an inpaint network, to resolve the many-to-one and one-to-many mapping issues. Thorough experiments show that our method outperforms existing methods in both novel view rendering and motion modeling, demonstrating the effectiveness of our forward flow motion modeling. Project page: https://npucvr.github.io/ForwardFlowDNeRF
* Accepted by ICCV2023 as oral. Project page: https://npucvr.github.io/ForwardFlowDNeRF
Continuous-time control synthesis under nested signal temporal logic specifications
Sep 17, 2023Signal temporal logic (STL) has gained popularity in robotics for expressing complex specifications that may involve timing requirements or deadlines. While the control synthesis for STL specifications without nested temporal operators has been studied in the literature, the case of nested temporal operators is substantially more challenging and requires new theoretical advancements. In this work, we propose an efficient continuous-time control synthesis framework for nonlinear systems under nested STL specifications. The framework is based on the notions of signal temporal logic tree (sTLT) and control barrier function (CBF). In particular, we detail the construction of an sTLT from a given STL formula and a continuous-time dynamical system, the sTLT semantics (i.e., satisfaction condition), and the equivalence or under-approximation relation between sTLT and STL. Leveraging the fact that the satisfaction condition of an sTLT is essentially keeping the state within certain sets during certain time intervals, it provides explicit guidelines for the CBF design. The resulting controller is obtained through the utilization of an online CBF-based program coupled with an event-triggered scheme for online updating the activation time interval of each CBF, with which the correctness of the system behavior can be established by construction. We demonstrate the efficacy of the proposed method for single-integrator and unicycle models under nested STL formulas.
Semi-supervised Cycle-GAN for face photo-sketch translation in the wild
Jul 18, 2023The performance of face photo-sketch translation has improved a lot thanks to deep neural networks. GAN based methods trained on paired images can produce high-quality results under laboratory settings. Such paired datasets are, however, often very small and lack diversity. Meanwhile, Cycle-GANs trained with unpaired photo-sketch datasets suffer from the \emph{steganography} phenomenon, which makes them not effective to face photos in the wild. In this paper, we introduce a semi-supervised approach with a noise-injection strategy, named Semi-Cycle-GAN (SCG), to tackle these problems. For the first problem, we propose a {\em pseudo sketch feature} representation for each input photo composed from a small reference set of photo-sketch pairs, and use the resulting {\em pseudo pairs} to supervise a photo-to-sketch generator $G_{p2s}$. The outputs of $G_{p2s}$ can in turn help to train a sketch-to-photo generator $G_{s2p}$ in a self-supervised manner. This allows us to train $G_{p2s}$ and $G_{s2p}$ using a small reference set of photo-sketch pairs together with a large face photo dataset (without ground-truth sketches). For the second problem, we show that the simple noise-injection strategy works well to alleviate the \emph{steganography} effect in SCG and helps to produce more reasonable sketch-to-photo results with less overfitting than fully supervised approaches. Experiments show that SCG achieves competitive performance on public benchmarks and superior results on photos in the wild.
Semi-DETR: Semi-Supervised Object Detection with Detection Transformers
Jul 16, 2023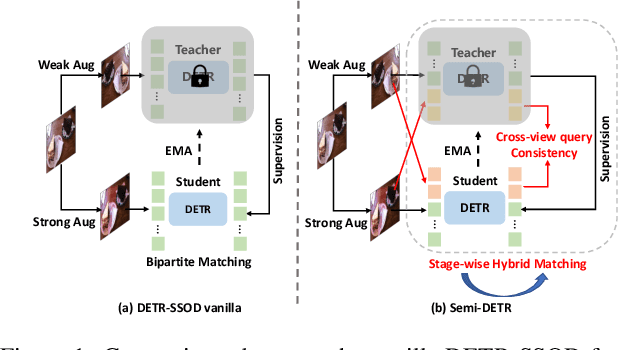
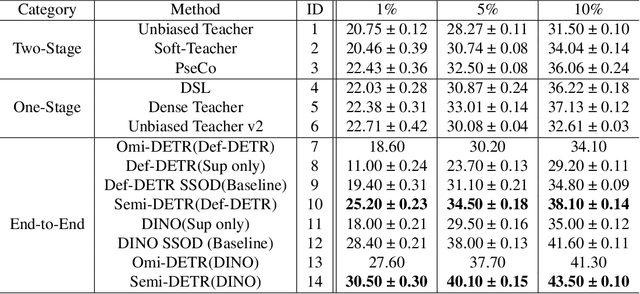
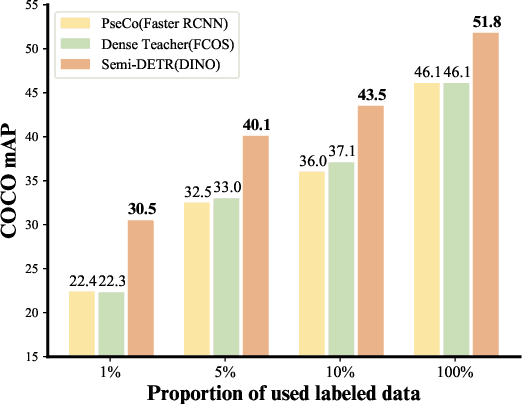
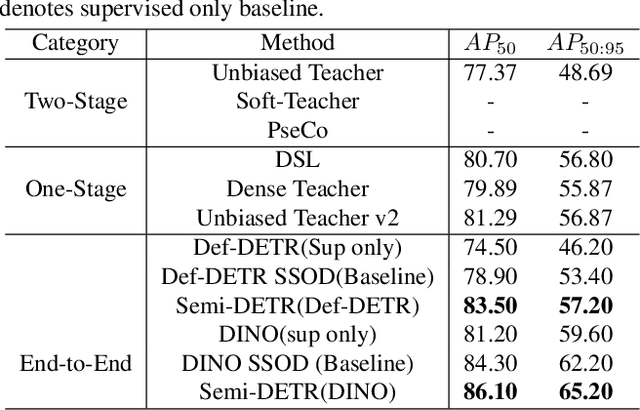
We analyze the DETR-based framework on semi-supervised object detection (SSOD) and observe that (1) the one-to-one assignment strategy generates incorrect matching when the pseudo ground-truth bounding box is inaccurate, leading to training inefficiency; (2) DETR-based detectors lack deterministic correspondence between the input query and its prediction output, which hinders the applicability of the consistency-based regularization widely used in current SSOD methods. We present Semi-DETR, the first transformer-based end-to-end semi-supervised object detector, to tackle these problems. Specifically, we propose a Stage-wise Hybrid Matching strategy that combines the one-to-many assignment and one-to-one assignment strategies to improve the training efficiency of the first stage and thus provide high-quality pseudo labels for the training of the second stage. Besides, we introduce a Crossview Query Consistency method to learn the semantic feature invariance of object queries from different views while avoiding the need to find deterministic query correspondence. Furthermore, we propose a Cost-based Pseudo Label Mining module to dynamically mine more pseudo boxes based on the matching cost of pseudo ground truth bounding boxes for consistency training. Extensive experiments on all SSOD settings of both COCO and Pascal VOC benchmark datasets show that our Semi-DETR method outperforms all state-of-the-art methods by clear margins. The PaddlePaddle version code1 is at https://github.com/PaddlePaddle/PaddleDetection/tree/develop/configs/semi_det/semi_detr.
CityTrack: Improving City-Scale Multi-Camera Multi-Target Tracking by Location-Aware Tracking and Box-Grained Matching
Jul 06, 2023


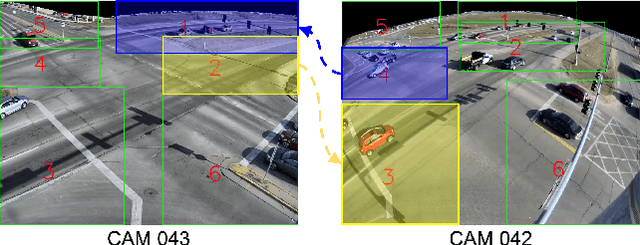
Multi-Camera Multi-Target Tracking (MCMT) is a computer vision technique that involves tracking multiple targets simultaneously across multiple cameras. MCMT in urban traffic visual analysis faces great challenges due to the complex and dynamic nature of urban traffic scenes, where multiple cameras with different views and perspectives are often used to cover a large city-scale area. Targets in urban traffic scenes often undergo occlusion, illumination changes, and perspective changes, making it difficult to associate targets across different cameras accurately. To overcome these challenges, we propose a novel systematic MCMT framework, called CityTrack. Specifically, we present a Location-Aware SCMT tracker which integrates various advanced techniques to improve its effectiveness in the MCMT task and propose a novel Box-Grained Matching (BGM) method for the ICA module to solve the aforementioned problems. We evaluated our approach on the public test set of the CityFlowV2 dataset and achieved an IDF1 of 84.91%, ranking 1st in the 2022 AI CITY CHALLENGE. Our experimental results demonstrate the effectiveness of our approach in overcoming the challenges posed by urban traffic scenes.
Multi-Modal 3D Object Detection by Box Matching
May 12, 2023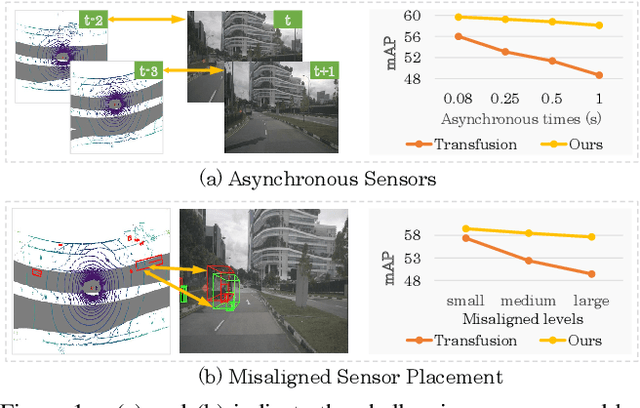



Multi-modal 3D object detection has received growing attention as the information from different sensors like LiDAR and cameras are complementary. Most fusion methods for 3D detection rely on an accurate alignment and calibration between 3D point clouds and RGB images. However, such an assumption is not reliable in a real-world self-driving system, as the alignment between different modalities is easily affected by asynchronous sensors and disturbed sensor placement. We propose a novel {F}usion network by {B}ox {M}atching (FBMNet) for multi-modal 3D detection, which provides an alternative way for cross-modal feature alignment by learning the correspondence at the bounding box level to free up the dependency of calibration during inference. With the learned assignments between 3D and 2D object proposals, the fusion for detection can be effectively performed by combing their ROI features. Extensive experiments on the nuScenes dataset demonstrate that our method is much more stable in dealing with challenging cases such as asynchronous sensors, misaligned sensor placement, and degenerated camera images than existing fusion methods. We hope that our FBMNet could provide an available solution to dealing with these challenging cases for safety in real autonomous driving scenarios. Codes will be publicly available at https://github.com/happinesslz/FBMNet.
ByteTrackV2: 2D and 3D Multi-Object Tracking by Associating Every Detection Box
Mar 27, 2023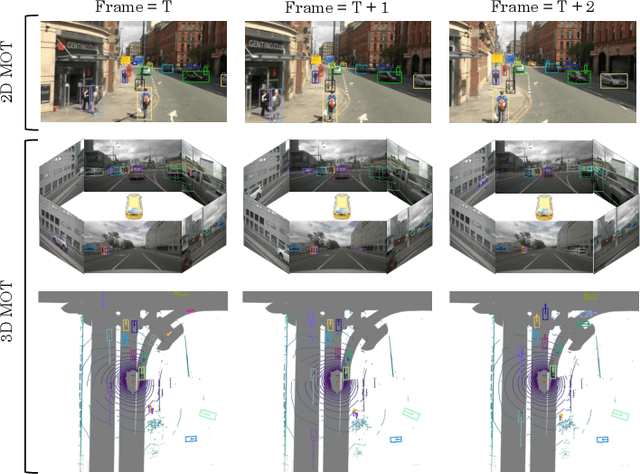
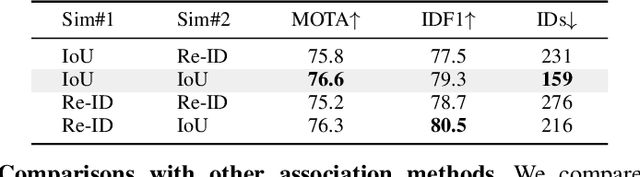
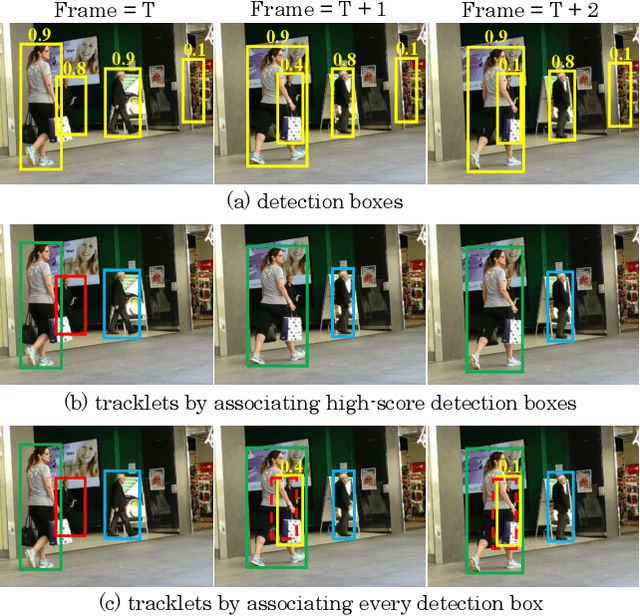
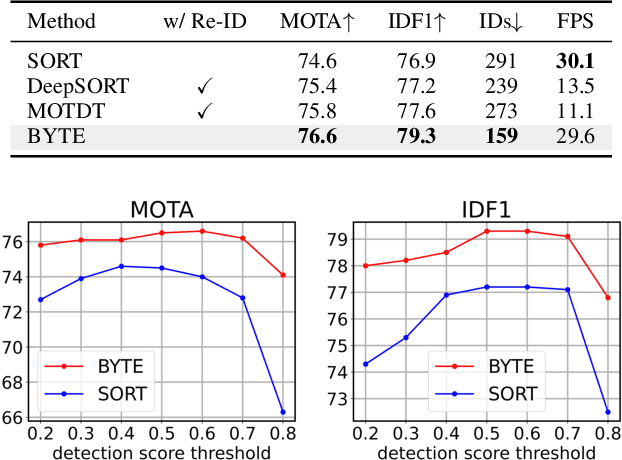
Multi-object tracking (MOT) aims at estimating bounding boxes and identities of objects across video frames. Detection boxes serve as the basis of both 2D and 3D MOT. The inevitable changing of detection scores leads to object missing after tracking. We propose a hierarchical data association strategy to mine the true objects in low-score detection boxes, which alleviates the problems of object missing and fragmented trajectories. The simple and generic data association strategy shows effectiveness under both 2D and 3D settings. In 3D scenarios, it is much easier for the tracker to predict object velocities in the world coordinate. We propose a complementary motion prediction strategy that incorporates the detected velocities with a Kalman filter to address the problem of abrupt motion and short-term disappearing. ByteTrackV2 leads the nuScenes 3D MOT leaderboard in both camera (56.4% AMOTA) and LiDAR (70.1% AMOTA) modalities. Furthermore, it is nonparametric and can be integrated with various detectors, making it appealing in real applications. The source code is released at https://github.com/ifzhang/ByteTrack-V2.
Ambiguity-Resistant Semi-Supervised Learning for Dense Object Detection
Mar 27, 2023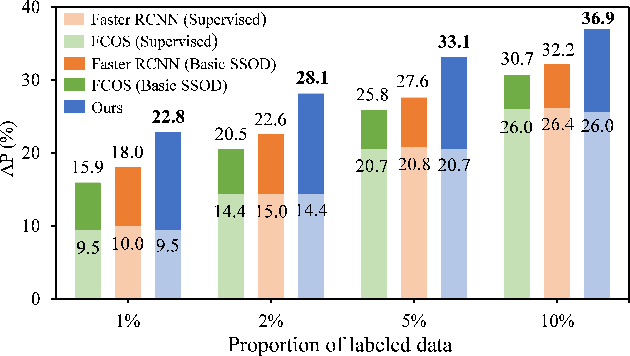
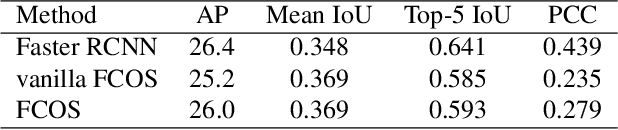
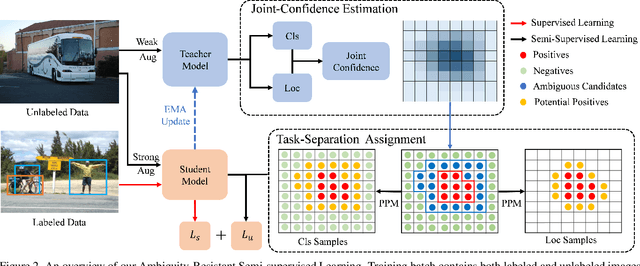
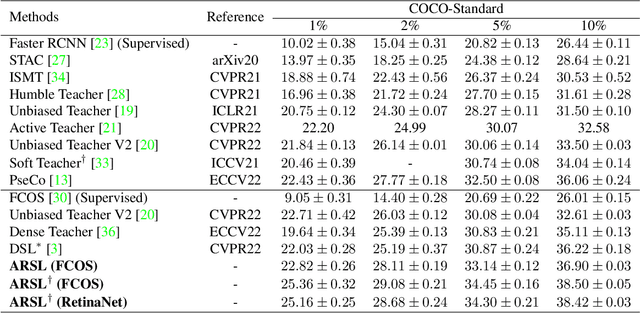
With basic Semi-Supervised Object Detection (SSOD) techniques, one-stage detectors generally obtain limited promotions compared with two-stage clusters. We experimentally find that the root lies in two kinds of ambiguities: (1) Selection ambiguity that selected pseudo labels are less accurate, since classification scores cannot properly represent the localization quality. (2) Assignment ambiguity that samples are matched with improper labels in pseudo-label assignment, as the strategy is misguided by missed objects and inaccurate pseudo boxes. To tackle these problems, we propose a Ambiguity-Resistant Semi-supervised Learning (ARSL) for one-stage detectors. Specifically, to alleviate the selection ambiguity, Joint-Confidence Estimation (JCE) is proposed to jointly quantifies the classification and localization quality of pseudo labels. As for the assignment ambiguity, Task-Separation Assignment (TSA) is introduced to assign labels based on pixel-level predictions rather than unreliable pseudo boxes. It employs a "divide-and-conquer" strategy and separately exploits positives for the classification and localization task, which is more robust to the assignment ambiguity. Comprehensive experiments demonstrate that ARSL effectively mitigates the ambiguities and achieves state-of-the-art SSOD performance on MS COCO and PASCAL VOC. Codes can be found at https://github.com/PaddlePaddle/PaddleDetection.