 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuanyu Lin
Inverse Learning with Extremely Sparse Feedback for Recommendation
Nov 20, 2023
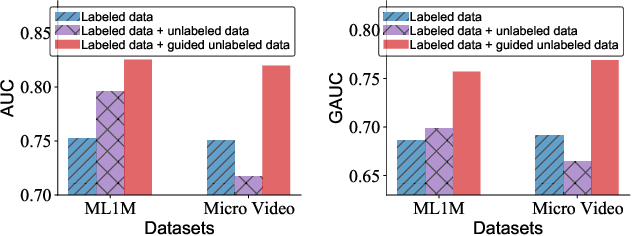
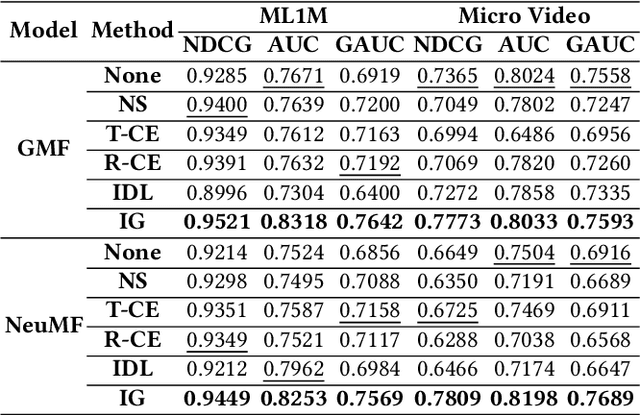
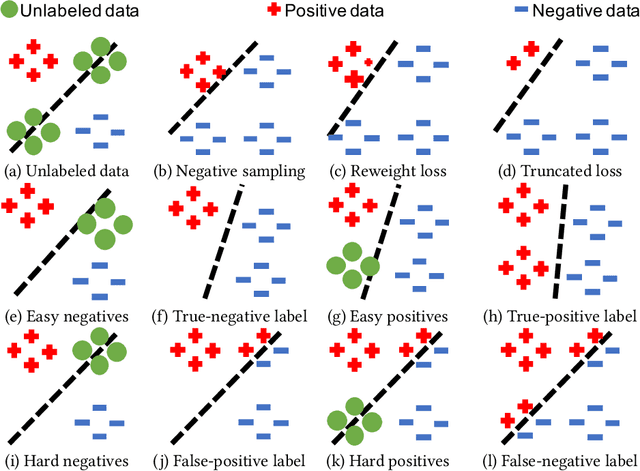
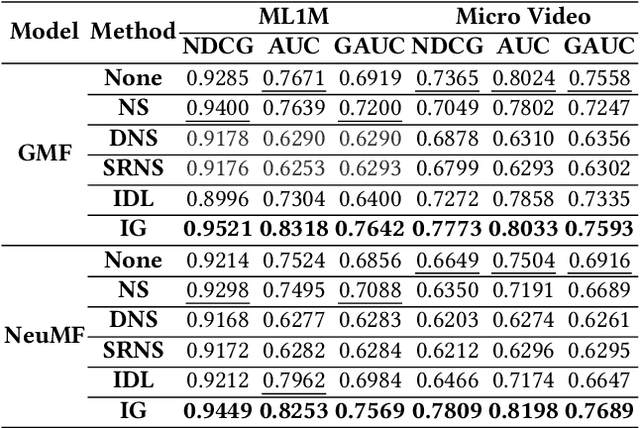
Modern personalized recommendation services often rely on user feedback, either explicit or implicit, to improve the quality of services. Explicit feedback refers to behaviors like ratings, while implicit feedback refers to behaviors like user clicks. However, in the scenario of full-screen video viewing experiences like Tiktok and Reels, the click action is absent, resulting in unclear feedback from users, hence introducing noises in modeling training. Existing approaches on de-noising recommendation mainly focus on positive instances while ignoring the noise in a large amount of sampled negative feedback. In this paper, we propose a meta-learning method to annotate the unlabeled data from loss and gradient perspectives, which considers the noises in both positive and negative instances. Specifically, we first propose an Inverse Dual Loss (IDL) to boost the true label learning and prevent the false label learning. Then we further propose an Inverse Gradient (IG) method to explore the correct updating gradient and adjust the updating based on meta-learning. Finally, we conduct extensive experiments on both benchmark and industrial datasets where our proposed method can significantly improve AUC by 9.25% against state-of-the-art methods. Further analysis verifies the proposed inverse learning framework is model-agnostic and can improve a variety of recommendation backbones. The source code, along with the best hyper-parameter settings, is available at this link: https://github.com/Guanyu-Lin/InverseLearning.
Mixed Attention Network for Cross-domain Sequential Recommendation
Nov 14, 2023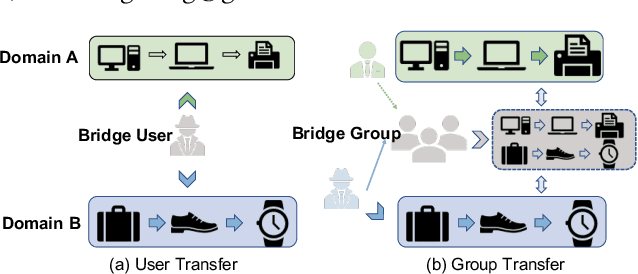
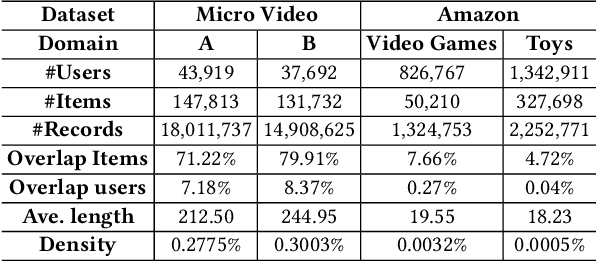
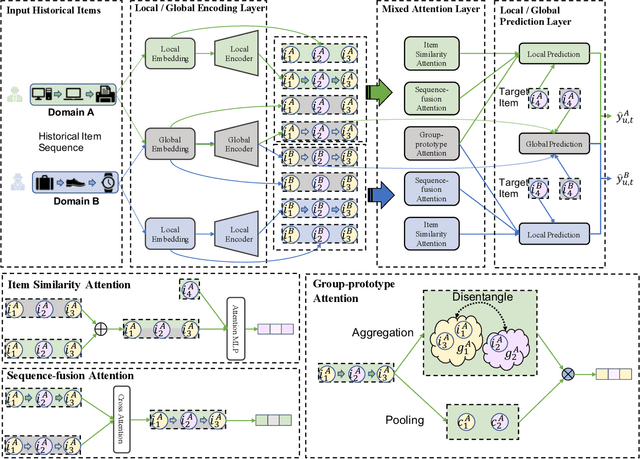
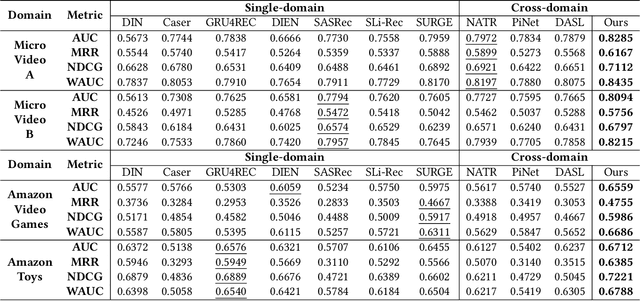
In modern recommender systems, sequential recommendation leverages chronological user behaviors to make effective next-item suggestions, which suffers from data sparsity issues, especially for new users. One promising line of work is the cross-domain recommendation, which trains models with data across multiple domains to improve the performance in data-scarce domains. Recent proposed cross-domain sequential recommendation models such as PiNet and DASL have a common drawback relying heavily on overlapped users in different domains, which limits their usage in practical recommender systems. In this paper, we propose a Mixed Attention Network (MAN) with local and global attention modules to extract the domain-specific and cross-domain information. Firstly, we propose a local/global encoding layer to capture the domain-specific/cross-domain sequential pattern. Then we propose a mixed attention layer with item similarity attention, sequence-fusion attention, and group-prototype attention to capture the local/global item similarity, fuse the local/global item sequence, and extract the user groups across different domains, respectively. Finally, we propose a local/global prediction layer to further evolve and combine the domain-specific and cross-domain interests. Experimental results on two real-world datasets (each with two domains) demonstrate the superiority of our proposed model. Further study also illustrates that our proposed method and components are model-agnostic and effective, respectively. The code and data are available at https://github.com/Guanyu-Lin/MAN.
GenImage: A Million-Scale Benchmark for Detecting AI-Generated Image
Jun 24, 2023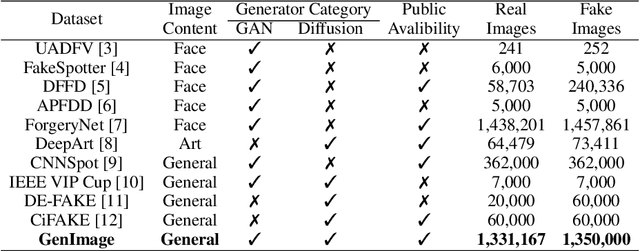

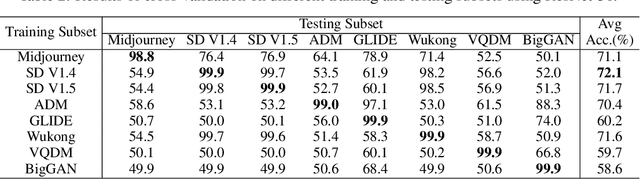
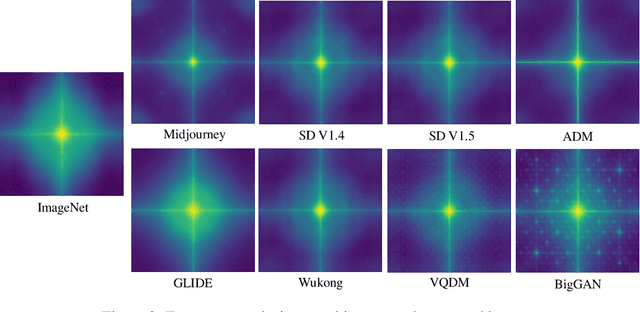
The extraordinary ability of generative models to generate photographic images has intensified concerns about the spread of disinformation, thereby leading to the demand for detectors capable of distinguishing between AI-generated fake images and real images. However, the lack of large datasets containing images from the most advanced image generators poses an obstacle to the development of such detectors. In this paper, we introduce the GenImage dataset, which has the following advantages: 1) Plenty of Images, including over one million pairs of AI-generated fake images and collected real images. 2) Rich Image Content, encompassing a broad range of image classes. 3) State-of-the-art Generators, synthesizing images with advanced diffusion models and GANs. The aforementioned advantages allow the detectors trained on GenImage to undergo a thorough evaluation and demonstrate strong applicability to diverse images. We conduct a comprehensive analysis of the dataset and propose two tasks for evaluating the detection method in resembling real-world scenarios. The cross-generator image classification task measures the performance of a detector trained on one generator when tested on the others. The degraded image classification task assesses the capability of the detectors in handling degraded images such as low-resolution, blurred, and compressed images. With the GenImage dataset, researchers can effectively expedite the development and evaluation of superior AI-generated image detectors in comparison to prevailing methodologies.
Dual-interest Factorization-heads Attention for Sequential Recommendation
Feb 10, 2023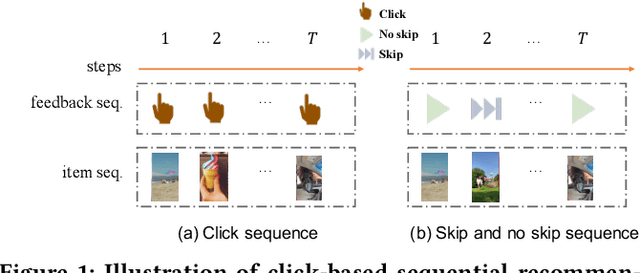
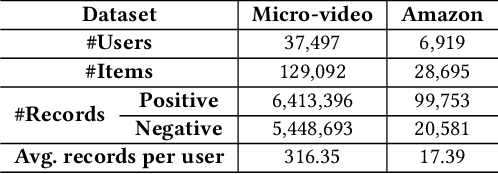
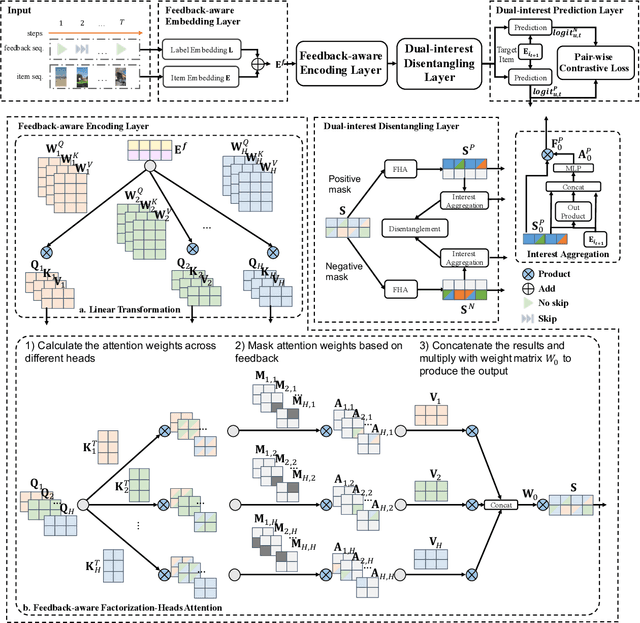
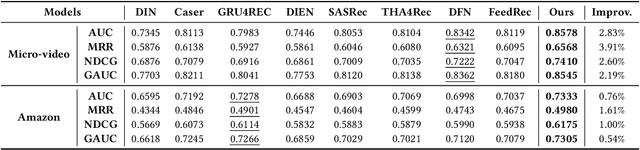
Accurate user interest modeling is vital for recommendation scenarios. One of the effective solutions is the sequential recommendation that relies on click behaviors, but this is not elegant in the video feed recommendation where users are passive in receiving the streaming contents and return skip or no-skip behaviors. Here skip and no-skip behaviors can be treated as negative and positive feedback, respectively. With the mixture of positive and negative feedback, it is challenging to capture the transition pattern of behavioral sequence. To do so, FeedRec has exploited a shared vanilla Transformer, which may be inelegant because head interaction of multi-heads attention does not consider different types of feedback. In this paper, we propose Dual-interest Factorization-heads Attention for Sequential Recommendation (short for DFAR) consisting of feedback-aware encoding layer, dual-interest disentangling layer and prediction layer. In the feedback-aware encoding layer, we first suppose each head of multi-heads attention can capture specific feedback relations. Then we further propose factorization-heads attention which can mask specific head interaction and inject feedback information so as to factorize the relation between different types of feedback. Additionally, we propose a dual-interest disentangling layer to decouple positive and negative interests before performing disentanglement on their representations. Finally, we evolve the positive and negative interests by corresponding towers whose outputs are contrastive by BPR loss. Experiments on two real-world datasets show the superiority of our proposed method against state-of-the-art baselines. Further ablation study and visualization also sustain its effectiveness. We release the source code here: https://github.com/tsinghua-fib-lab/WWW2023-DFAR.
Dual Contrastive Network for Sequential Recommendation with User and Item-Centric Perspectives
Sep 18, 2022



With the outbreak of today's streaming data, sequential recommendation is a promising solution to achieve time-aware personalized modeling. It aims to infer the next interacted item of given user based on history item sequence. Some recent works tend to improve the sequential recommendation via randomly masking on the history item so as to generate self-supervised signals. But such approach will indeed result in sparser item sequence and unreliable signals. Besides, the existing sequential recommendation is only user-centric, i.e., based on the historical items by chronological order to predict the probability of candidate items, which ignores whether the items from a provider can be successfully recommended. The such user-centric recommendation will make it impossible for the provider to expose their new items and result in popular bias. In this paper, we propose a novel Dual Contrastive Network (DCN) to generate ground-truth self-supervised signals for sequential recommendation by auxiliary user-sequence from item-centric perspective. Specifically, we propose dual representation contrastive learning to refine the representation learning by minimizing the euclidean distance between the representations of given user/item and history items/users of them. Before the second contrastive learning module, we perform next user prediction to to capture the trends of items preferred by certain types of users and provide personalized exploration opportunities for item providers. Finally, we further propose dual interest contrastive learning to self-supervise the dynamic interest from next item/user prediction and static interest of matching probability. Experiments on four benchmark datasets verify the effectiveness of our proposed method. Further ablation study also illustrates the boosting effect of the proposed components upon different sequential models.