 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuodong Du
Prototype-guided Cross-modal Completion and Alignment for Incomplete Text-based Person Re-identification
Oct 03, 2023
Traditional text-based person re-identification (ReID) techniques heavily rely on fully matched multi-modal data, which is an ideal scenario. However, due to inevitable data missing and corruption during the collection and processing of cross-modal data, the incomplete data issue is usually met in real-world applications. Therefore, we consider a more practical task termed the incomplete text-based ReID task, where person images and text descriptions are not completely matched and contain partially missing modality data. To this end, we propose a novel Prototype-guided Cross-modal Completion and Alignment (PCCA) framework to handle the aforementioned issues for incomplete text-based ReID. Specifically, we cannot directly retrieve person images based on a text query on missing modality data. Therefore, we propose the cross-modal nearest neighbor construction strategy for missing data by computing the cross-modal similarity between existing images and texts, which provides key guidance for the completion of missing modal features. Furthermore, to efficiently complete the missing modal features, we construct the relation graphs with the aforementioned cross-modal nearest neighbor sets of missing modal data and the corresponding prototypes, which can further enhance the generated missing modal features. Additionally, for tighter fine-grained alignment between images and texts, we raise a prototype-aware cross-modal alignment loss that can effectively reduce the modality heterogeneity gap for better fine-grained alignment in common space. Extensive experimental results on several benchmarks with different missing ratios amply demonstrate that our method can consistently outperform state-of-the-art text-image ReID approaches.
* Sorry, some collaborators do not agree to publish it on Arxiv, so please withdraw this paper
Leveraging Multi-stream Information Fusion for Trajectory Prediction in Low-illumination Scenarios: A Multi-channel Graph Convolutional Approach
Nov 18, 2022Trajectory prediction is a fundamental problem and challenge for autonomous vehicles. Early works mainly focused on designing complicated architectures for deep-learning-based prediction models in normal-illumination environments, which fail in dealing with low-light conditions. This paper proposes a novel approach for trajectory prediction in low-illumination scenarios by leveraging multi-stream information fusion, which flexibly integrates image, optical flow, and object trajectory information. The image channel employs Convolutional Neural Network (CNN) and Long Short-term Memory (LSTM) networks to extract temporal information from the camera. The optical flow channel is applied to capture the pattern of relative motion between adjacent camera frames and modelled by Spatial-Temporal Graph Convolutional Network (ST-GCN). The trajectory channel is used to recognize high-level interactions between vehicles. Finally, information from all the three channels is effectively fused in the prediction module to generate future trajectories of surrounding vehicles in low-illumination conditions. The proposed multi-channel graph convolutional approach is validated on HEV-I and newly generated Dark-HEV-I, egocentric vision datasets that primarily focus on urban intersection scenarios. The results demonstrate that our method outperforms the baselines, in standard and low-illumination scenarios. Additionally, our approach is generic and applicable to scenarios with different types of perception data. The source code of the proposed approach is available at https://github.com/TommyGong08/MSIF}{https://github.com/TommyGong08/MSIF.
Graph Reinforcement Learning Application to Co-operative Decision-Making in Mixed Autonomy Traffic: Framework, Survey, and Challenges
Nov 06, 2022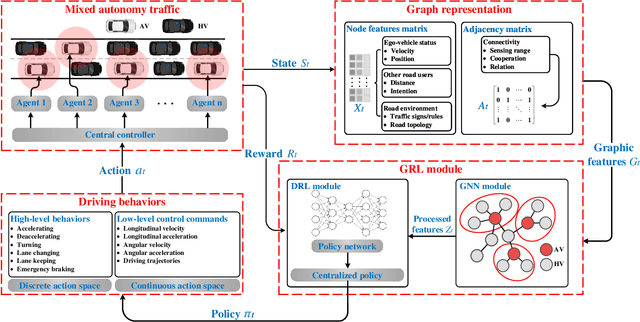
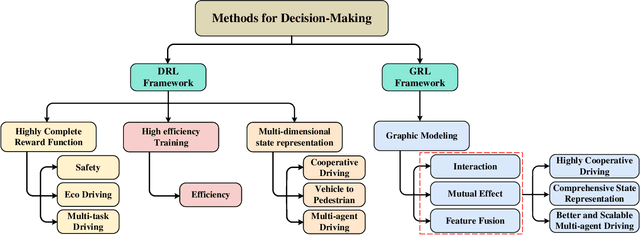
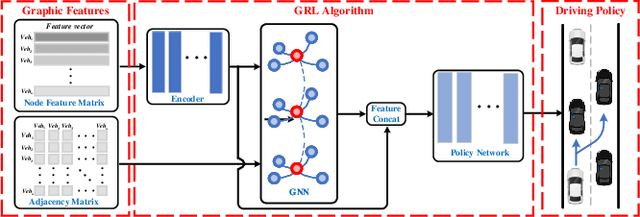

Proper functioning of connected and automated vehicles (CAVs) is crucial for the safety and efficiency of future intelligent transport systems. Meanwhile, transitioning to fully autonomous driving requires a long period of mixed autonomy traffic, including both CAVs and human-driven vehicles. Thus, collaboration decision-making for CAVs is essential to generate appropriate driving behaviors to enhance the safety and efficiency of mixed autonomy traffic. In recent years, deep reinforcement learning (DRL) has been widely used in solving decision-making problems. However, the existing DRL-based methods have been mainly focused on solving the decision-making of a single CAV. Using the existing DRL-based methods in mixed autonomy traffic cannot accurately represent the mutual effects of vehicles and model dynamic traffic environments. To address these shortcomings, this article proposes a graph reinforcement learning (GRL) approach for multi-agent decision-making of CAVs in mixed autonomy traffic. First, a generic and modular GRL framework is designed. Then, a systematic review of DRL and GRL methods is presented, focusing on the problems addressed in recent research. Moreover, a comparative study on different GRL methods is further proposed based on the designed framework to verify the effectiveness of GRL methods. Results show that the GRL methods can well optimize the performance of multi-agent decision-making for CAVs in mixed autonomy traffic compared to the DRL methods. Finally, challenges and future research directions are summarized. This study can provide a valuable research reference for solving the multi-agent decision-making problems of CAVs in mixed autonomy traffic and can promote the implementation of GRL-based methods into intelligent transportation systems. The source code of our work can be found at https://github.com/Jacklinkk/Graph_CAVs.
Learning Generalizable and Identity-Discriminative Representations for Face Anti-Spoofing
Jan 17, 2019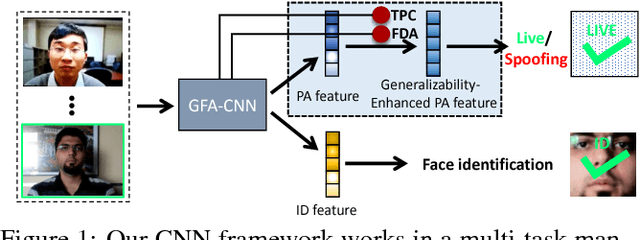
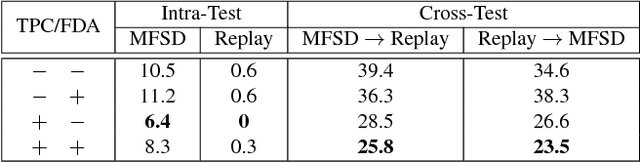
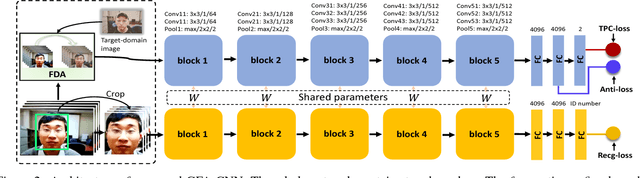

Face anti-spoofing (a.k.a presentation attack detection) has drawn growing attention due to the high-security demand in face authentication systems. Existing CNN-based approaches usually well recognize the spoofing faces when training and testing spoofing samples display similar patterns, but their performance would drop drastically on testing spoofing faces of unseen scenes. In this paper, we try to boost the generalizability and applicability of these methods by designing a CNN model with two major novelties. First, we propose a simple yet effective Total Pairwise Confusion (TPC) loss for CNN training, which enhances the generalizability of the learned Presentation Attack (PA) representations. Secondly, we incorporate a Fast Domain Adaptation (FDA) component into the CNN model to alleviate negative effects brought by domain changes. Besides, our proposed model, which is named Generalizable Face Authentication CNN (GFA-CNN), works in a multi-task manner, performing face anti-spoofing and face recognition simultaneously. Experimental results show that GFA-CNN outperforms previous face anti-spoofing approaches and also well preserves the identity information of input face images.
Enhancement of land-use change modeling using convolutional neural networks and convolutional denoising autoencoders
Mar 03, 2018



The neighborhood effect is a key driving factor for the land-use change (LUC) process. This study applies convolutional neural networks (CNN) to capture neighborhood characteristics from satellite images and to enhance the performance of LUC modeling. We develop a hybrid CNN model (conv-net) to predict the LU transition probability by combining satellite images and geographical features. A spatial weight layer is designed to incorporate the distance-decay characteristics of neighborhood effect into conv-net. As an alternative model, we also develop a hybrid convolutional denoising autoencoder and multi-layer perceptron model (CDAE-net), which specifically learns latent representations from satellite images and denoises the image data. Finally, a DINAMICA-based cellular automata (CA) model simulates the LU pattern. The results show that the convolutional-based models improve the modeling performances compared with a model that accepts only the geographical features. Overall, conv-net outperforms CDAE-net in terms of LUC predictive performance. Nonetheless, CDAE-net performs better when the data are noisy.