 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHaizhou Shi
Efficient Tuning and Inference for Large Language Models on Textual Graphs
Jan 28, 2024
Rich textual and topological information of textual graphs need to be modeled in real-world applications such as webpages, e-commerce, and academic articles. Practitioners have been long following the path of adopting a shallow text encoder and a subsequent graph neural network (GNN) to solve this problem. In light of recent advancements in large language models (LLMs), it is apparent that integrating LLMs for enhanced textual encoding can substantially improve the performance of textual graphs. Nevertheless, the efficiency of these methods poses a significant challenge. In this paper, we propose ENGINE, a parameter- and memory-efficient fine-tuning method for textual graphs with an LLM encoder. The key insight is to combine the LLMs and GNNs through a tunable side structure, which significantly reduces the training complexity without impairing the joint model's capacity. Extensive experiments on textual graphs demonstrate our method's effectiveness by achieving the best model performance, meanwhile having the lowest training cost compared to previous methods. Moreover, we introduce two variants with caching and dynamic early exit to further enhance training and inference speed. Specifically, caching accelerates ENGINE's training by 12x, and dynamic early exit achieves up to 5x faster inference with a negligible performance drop (at maximum 1.17% relevant drop across 7 datasets).
A Unified Approach to Domain Incremental Learning with Memory: Theory and Algorithm
Oct 18, 2023Domain incremental learning aims to adapt to a sequence of domains with access to only a small subset of data (i.e., memory) from previous domains. Various methods have been proposed for this problem, but it is still unclear how they are related and when practitioners should choose one method over another. In response, we propose a unified framework, dubbed Unified Domain Incremental Learning (UDIL), for domain incremental learning with memory. Our UDIL **unifies** various existing methods, and our theoretical analysis shows that UDIL always achieves a tighter generalization error bound compared to these methods. The key insight is that different existing methods correspond to our bound with different **fixed** coefficients; based on insights from this unification, our UDIL allows **adaptive** coefficients during training, thereby always achieving the tightest bound. Empirical results show that our UDIL outperforms the state-of-the-art domain incremental learning methods on both synthetic and real-world datasets. Code will be available at https://github.com/Wang-ML-Lab/unified-continual-learning.
GraphControl: Adding Conditional Control to Universal Graph Pre-trained Models for Graph Domain Transfer Learning
Oct 12, 2023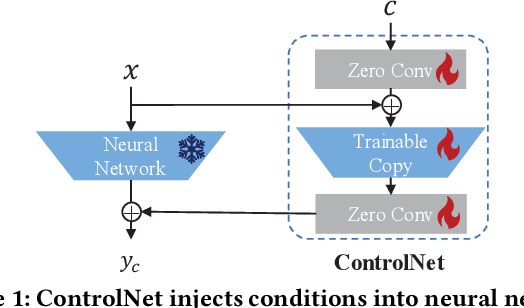
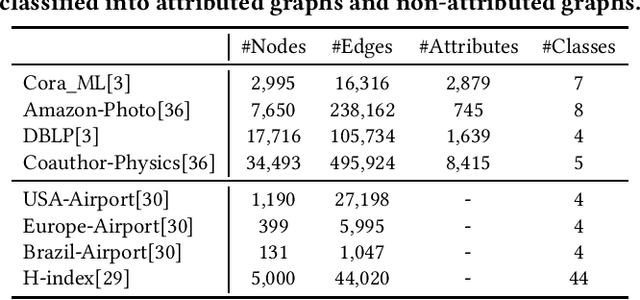
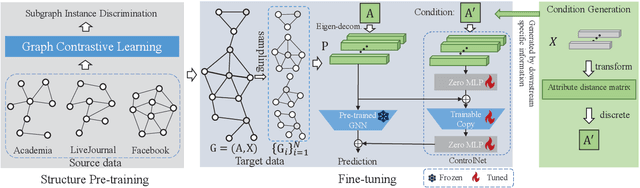
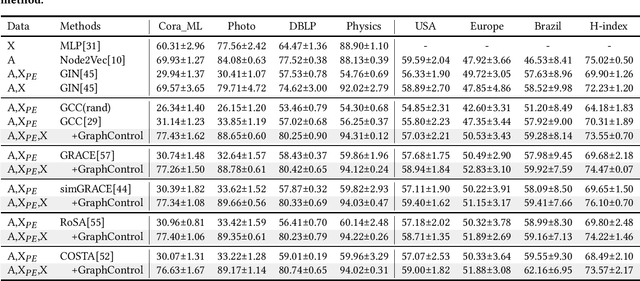
Graph-structured data is ubiquitous in the world which models complex relationships between objects, enabling various Web applications. Daily influxes of unlabeled graph data on the Web offer immense potential for these applications. Graph self-supervised algorithms have achieved significant success in acquiring generic knowledge from abundant unlabeled graph data. These pre-trained models can be applied to various downstream Web applications, saving training time and improving downstream (target) performance. However, different graphs, even across seemingly similar domains, can differ significantly in terms of attribute semantics, posing difficulties, if not infeasibility, for transferring the pre-trained models to downstream tasks. Concretely speaking, for example, the additional task-specific node information in downstream tasks (specificity) is usually deliberately omitted so that the pre-trained representation (transferability) can be leveraged. The trade-off as such is termed as "transferability-specificity dilemma" in this work. To address this challenge, we introduce an innovative deployment module coined as GraphControl, motivated by ControlNet, to realize better graph domain transfer learning. Specifically, by leveraging universal structural pre-trained models and GraphControl, we align the input space across various graphs and incorporate unique characteristics of target data as conditional inputs. These conditions will be progressively integrated into the model during fine-tuning or prompt tuning through ControlNet, facilitating personalized deployment. Extensive experiments show that our method significantly enhances the adaptability of pre-trained models on target attributed datasets, achieving 1.4-3x performance gain. Furthermore, it outperforms training-from-scratch methods on target data with a comparable margin and exhibits faster convergence.
MARIO: Model Agnostic Recipe for Improving OOD Generalization of Graph Contrastive Learning
Aug 02, 2023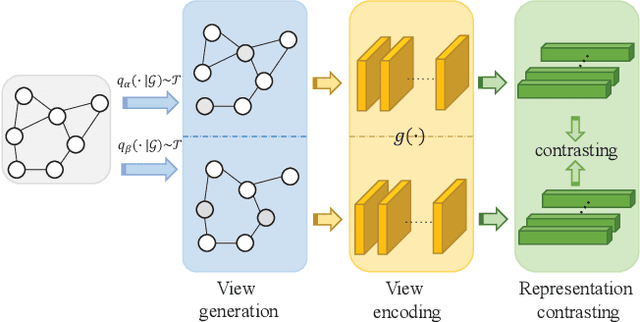

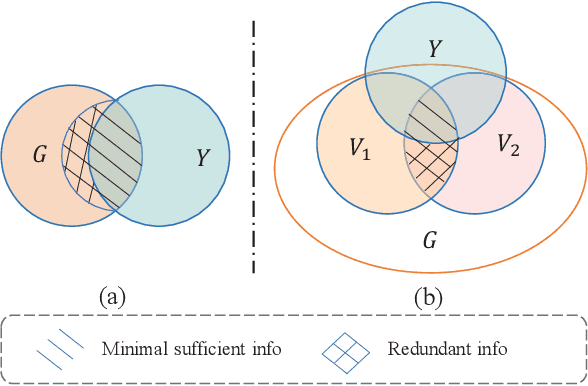
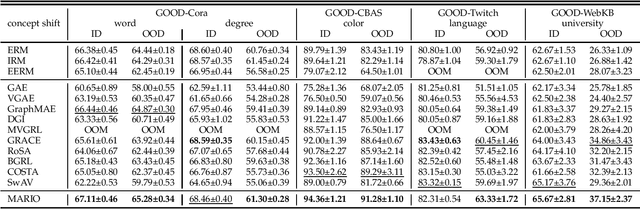
In this work, we investigate the problem of out-of-distribution (OOD) generalization for unsupervised learning methods on graph data. This scenario is particularly challenging because graph neural networks (GNNs) have been shown to be sensitive to distributional shifts, even when labels are available. To address this challenge, we propose a \underline{M}odel-\underline{A}gnostic \underline{R}ecipe for \underline{I}mproving \underline{O}OD generalizability of unsupervised graph contrastive learning methods, which we refer to as MARIO. MARIO introduces two principles aimed at developing distributional-shift-robust graph contrastive methods to overcome the limitations of existing frameworks: (i) Information Bottleneck (IB) principle for achieving generalizable representations and (ii) Invariant principle that incorporates adversarial data augmentation to obtain invariant representations. To the best of our knowledge, this is the first work that investigates the OOD generalization problem of graph contrastive learning, with a specific focus on node-level tasks. Through extensive experiments, we demonstrate that our method achieves state-of-the-art performance on the OOD test set, while maintaining comparable performance on the in-distribution test set when compared to existing approaches. The source code for our method can be found at: https://github.com/ZhuYun97/MARIO
Structure-Aware Group Discrimination with Adaptive-View Graph Encoder: A Fast Graph Contrastive Learning Framework
Mar 09, 2023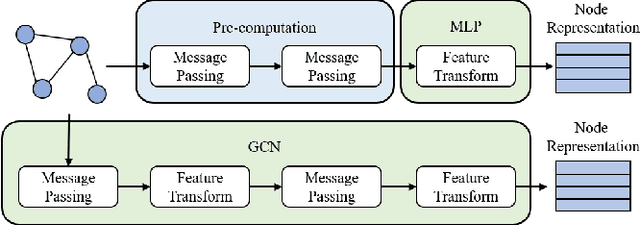
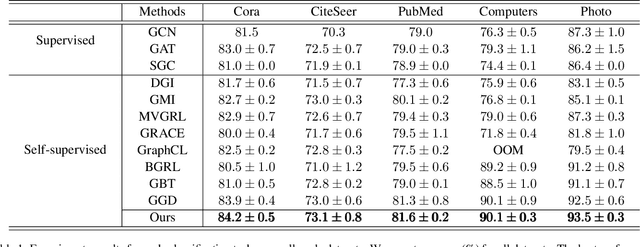
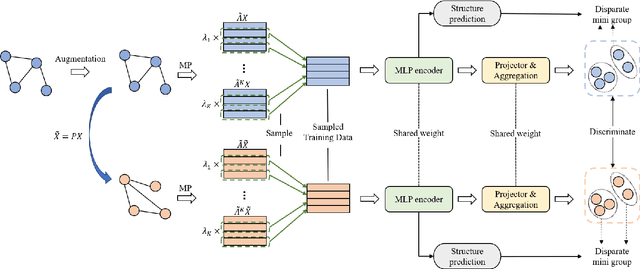
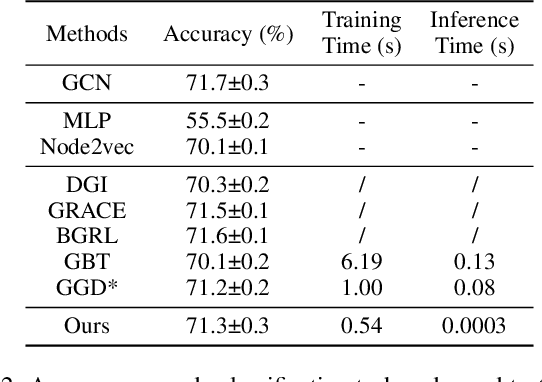
Albeit having gained significant progress lately, large-scale graph representation learning remains expensive to train and deploy for two main reasons: (i) the repetitive computation of multi-hop message passing and non-linearity in graph neural networks (GNNs); (ii) the computational cost of complex pairwise contrastive learning loss. Two main contributions are made in this paper targeting this twofold challenge: we first propose an adaptive-view graph neural encoder (AVGE) with a limited number of message passing to accelerate the forward pass computation, and then we propose a structure-aware group discrimination (SAGD) loss in our framework which avoids inefficient pairwise loss computing in most common GCL and improves the performance of the simple group discrimination. By the framework proposed, we manage to bring down the training and inference cost on various large-scale datasets by a significant margin (250x faster inference time) without loss of the downstream-task performance.
Relational Graph Learning for Grounded Video Description Generation
Dec 02, 2021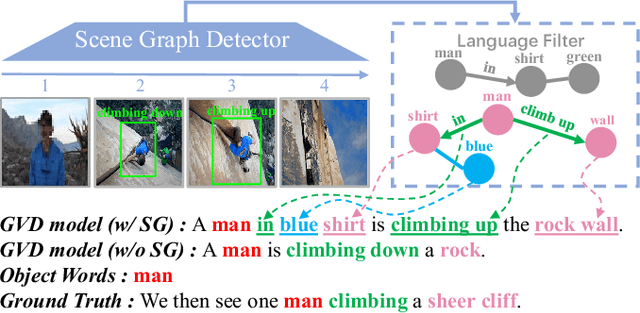
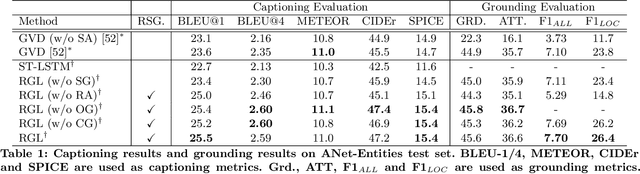
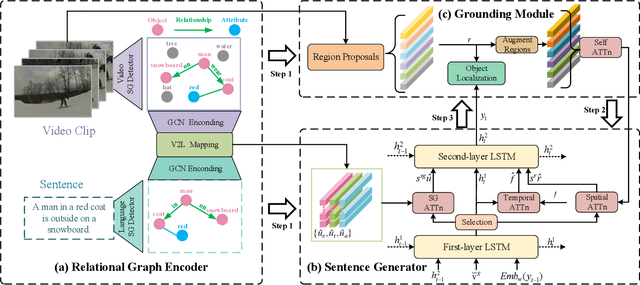

Grounded video description (GVD) encourages captioning models to attend to appropriate video regions (e.g., objects) dynamically and generate a description. Such a setting can help explain the decisions of captioning models and prevents the model from hallucinating object words in its description. However, such design mainly focuses on object word generation and thus may ignore fine-grained information and suffer from missing visual concepts. Moreover, relational words (e.g., "jump left or right") are usual spatio-temporal inference results, i.e., these words cannot be grounded on certain spatial regions. To tackle the above limitations, we design a novel relational graph learning framework for GVD, in which a language-refined scene graph representation is designed to explore fine-grained visual concepts. Furthermore, the refined graph can be regarded as relational inductive knowledge to assist captioning models in selecting the relevant information it needs to generate correct words. We validate the effectiveness of our model through automatic metrics and human evaluation, and the results indicate that our approach can generate more fine-grained and accurate description, and it solves the problem of object hallucination to some extent.
Federated Self-Supervised Contrastive Learning via Ensemble Similarity Distillation
Sep 29, 2021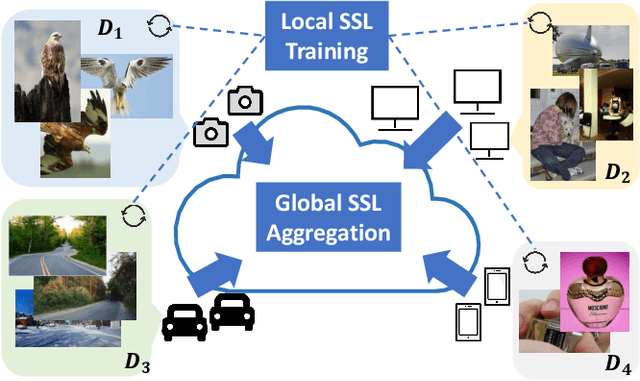
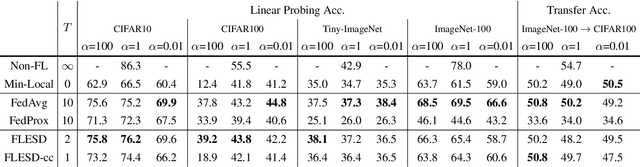
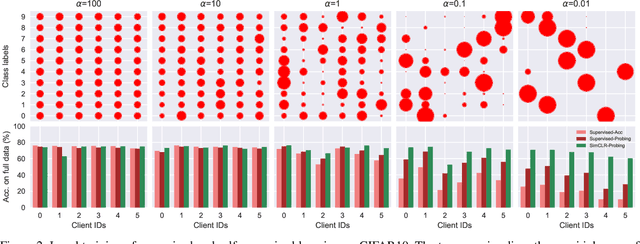
This paper investigates the feasibility of learning good representation space with unlabeled client data in the federated scenario. Existing works trivially inherit the supervised federated learning methods, which does not apply to the model heterogeneity and has the potential risk of privacy exposure. To tackle the problems above, we first identify that self-supervised contrastive local training is more robust against the non-i.i.d.-ness than the traditional supervised learning paradigm. Then we propose a novel federated self-supervised contrastive learning framework FLESD that supports architecture-agnostic local training and communication-efficient global aggregation. At each round of communication, the server first gathers a fraction of the clients' inferred similarity matrices on a public dataset. Then FLESD ensembles the similarity matrices and trains the global model via similarity distillation. We verify the effectiveness of our proposed framework by a series of empirical experiments and show that FLESD has three main advantages over the existing methods: it handles the model heterogeneity, is less prone to privacy leak, and is more communication-efficient. We will release the code of this paper in the future.
On the Efficacy of Small Self-Supervised Contrastive Models without Distillation Signals
Jul 30, 2021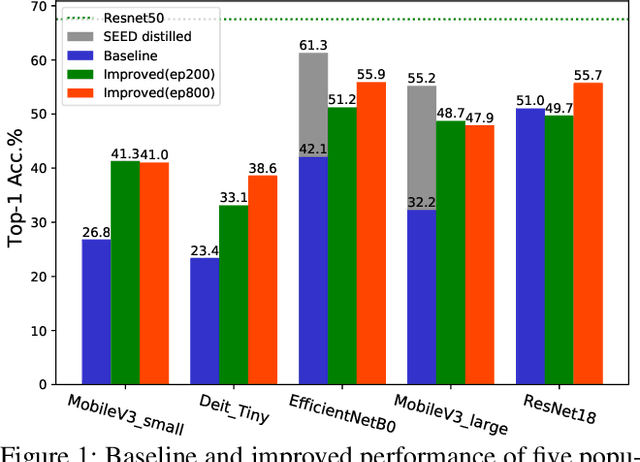
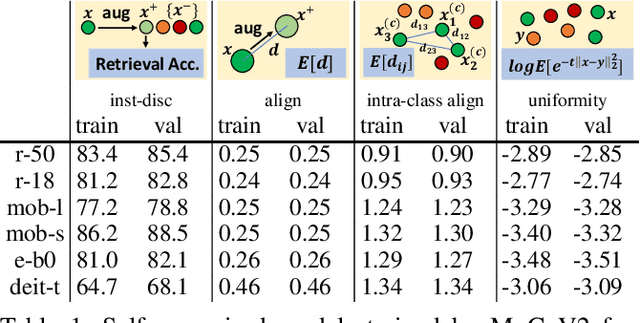
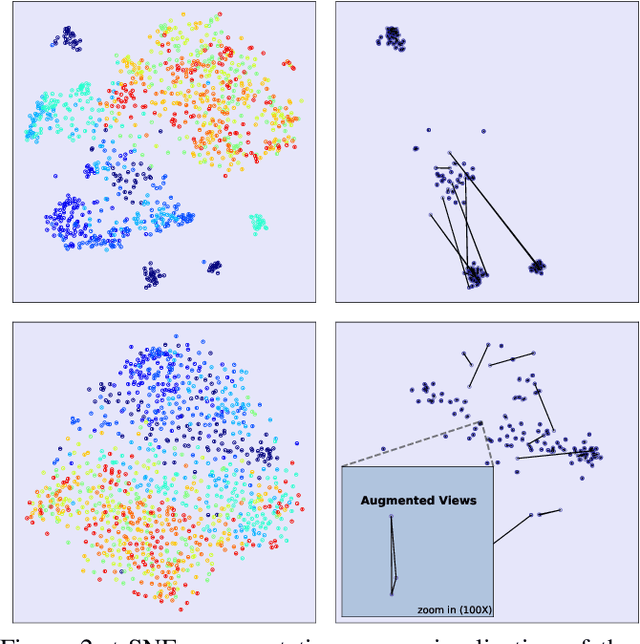
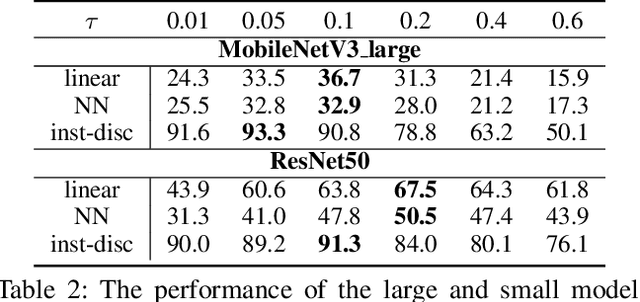
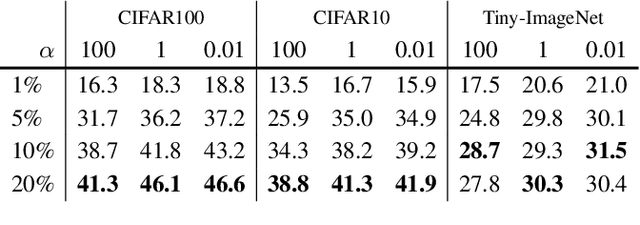
It is a consensus that small models perform quite poorly under the paradigm of self-supervised contrastive learning. Existing methods usually adopt a large off-the-shelf model to transfer knowledge to the small one via knowledge distillation. Despite their effectiveness, distillation-based methods may not be suitable for some resource-restricted scenarios due to the huge computational expenses of deploying a large model. In this paper, we study the issue of training self-supervised small models without distillation signals. We first evaluate the representation spaces of the small models and make two non-negligible observations: (i) small models can complete the pretext task without overfitting despite its limited capacity; (ii) small models universally suffer the problem of over-clustering. Then we verify multiple assumptions that are considered to alleviate the over-clustering phenomenon. Finally, we combine the validated techniques and improve the baseline of five small architectures with considerable margins, which indicates that training small self-supervised contrastive models is feasible even without distillation signals.
Alleviate Representation Overlapping in Class Incremental Learning by Contrastive Class Concentration
Jul 30, 2021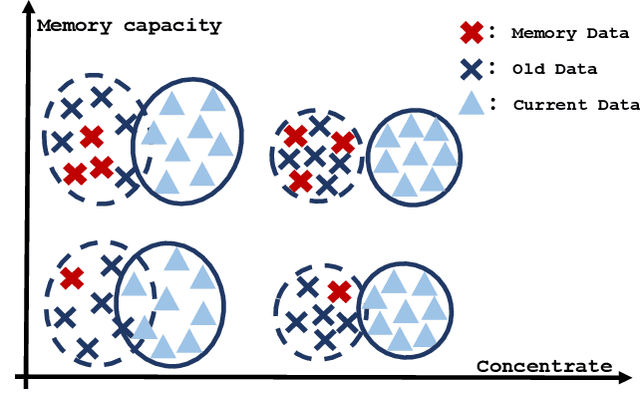
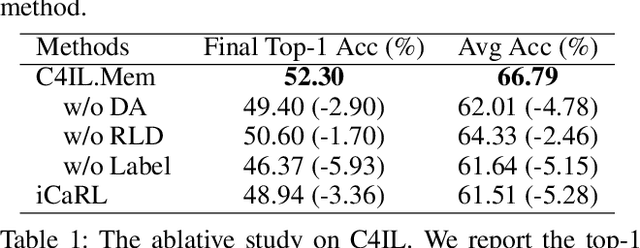
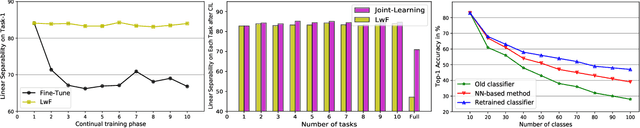
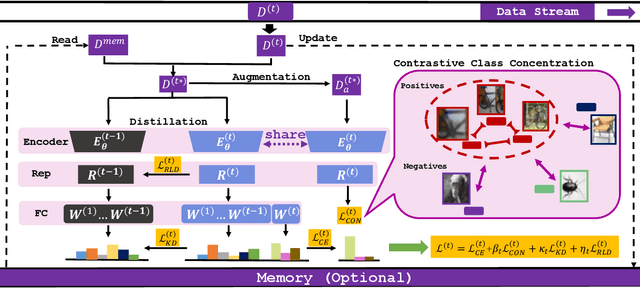
The challenge of the Class Incremental Learning~(CIL) lies in difficulty for a learner to discern the old classes' data from the new as no previous classes' data is preserved. In this paper, we reveal three causes for catastrophic forgetting at the representational level, namely, representation forgetting, representation overlapping, and classifier deviation. Based on the observation above, we propose a new CIL framework, Contrastive Class Concentration for CIL (C4IL) to alleviate the phenomenon of representation overlapping that works in both memory-based and memory-free methods. Our framework leverages the class concentration effect of contrastive representation learning, therefore yielding a representation distribution with better intra-class compatibility and inter-class separability. Quantitative experiments showcase the effectiveness of our framework: it outperforms the baseline methods by 5% in terms of the average and top-1 accuracy in 10-phase and 20-phase CIL. Qualitative results also demonstrate that our method generates a more compact representation distribution that alleviates the overlapping problem.
CIL: Contrastive Instance Learning Framework for Distantly Supervised Relation Extraction
Jun 21, 2021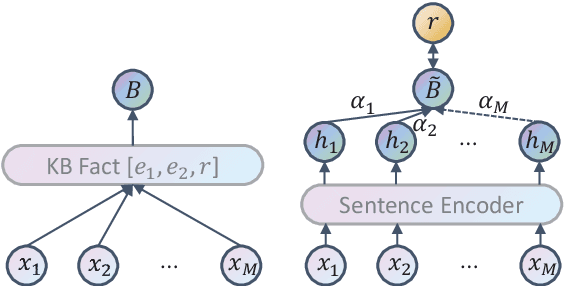
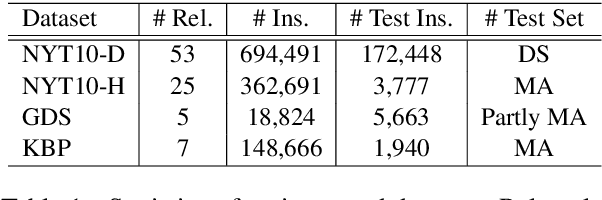
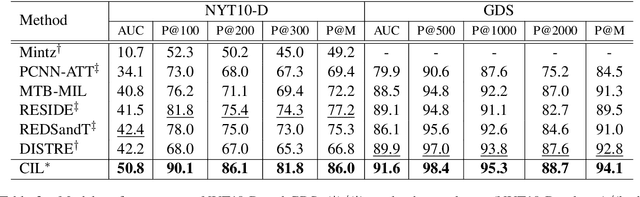
The journey of reducing noise from distant supervision (DS) generated training data has been started since the DS was first introduced into the relation extraction (RE) task. For the past decade, researchers apply the multi-instance learning (MIL) framework to find the most reliable feature from a bag of sentences. Although the pattern of MIL bags can greatly reduce DS noise, it fails to represent many other useful sentence features in the datasets. In many cases, these sentence features can only be acquired by extra sentence-level human annotation with heavy costs. Therefore, the performance of distantly supervised RE models is bounded. In this paper, we go beyond typical MIL framework and propose a novel contrastive instance learning (CIL) framework. Specifically, we regard the initial MIL as the relational triple encoder and constraint positive pairs against negative pairs for each instance. Experiments demonstrate the effectiveness of our proposed framework, with significant improvements over the previous methods on NYT10, GDS and KBP.