 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHamed Alemohammad
Seeing Through the Clouds: Cloud Gap Imputation with Prithvi Foundation Model
Apr 30, 2024
Filling cloudy pixels in multispectral satellite imagery is essential for accurate data analysis and downstream applications, especially for tasks which require time series data. To address this issue, we compare the performance of a foundational Vision Transformer (ViT) model with a baseline Conditional Generative Adversarial Network (CGAN) model for missing value imputation in time series of multispectral satellite imagery. We randomly mask time series of satellite images using real-world cloud masks and train each model to reconstruct the missing pixels. The ViT model is fine-tuned from a pretrained model, while the CGAN is trained from scratch. Using quantitative evaluation metrics such as structural similarity index and mean absolute error as well as qualitative visual analysis, we assess imputation accuracy and contextual preservation.
Foundation Models for Generalist Geospatial Artificial Intelligence
Nov 08, 2023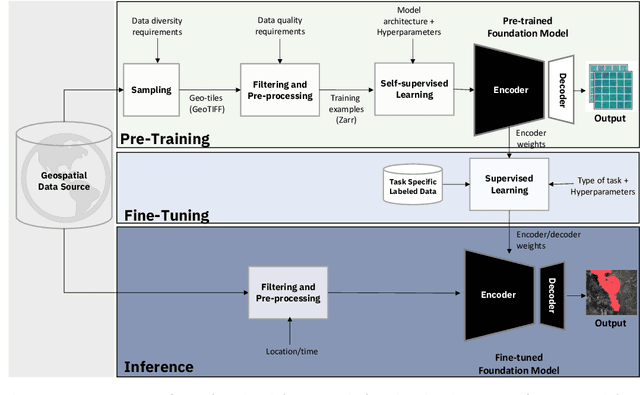

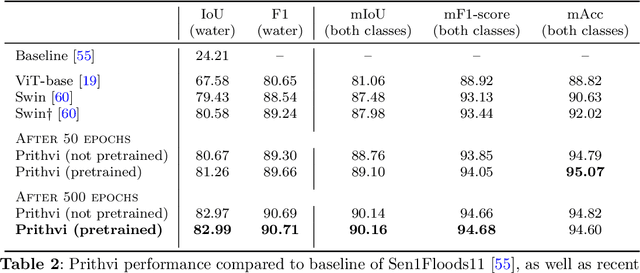
Significant progress in the development of highly adaptable and reusable Artificial Intelligence (AI) models is expected to have a significant impact on Earth science and remote sensing. Foundation models are pre-trained on large unlabeled datasets through self-supervision, and then fine-tuned for various downstream tasks with small labeled datasets. This paper introduces a first-of-a-kind framework for the efficient pre-training and fine-tuning of foundational models on extensive geospatial data. We have utilized this framework to create Prithvi, a transformer-based geospatial foundational model pre-trained on more than 1TB of multispectral satellite imagery from the Harmonized Landsat-Sentinel 2 (HLS) dataset. Our study demonstrates the efficacy of our framework in successfully fine-tuning Prithvi to a range of Earth observation tasks that have not been tackled by previous work on foundation models involving multi-temporal cloud gap imputation, flood mapping, wildfire scar segmentation, and multi-temporal crop segmentation. Our experiments show that the pre-trained model accelerates the fine-tuning process compared to leveraging randomly initialized weights. In addition, pre-trained Prithvi compares well against the state-of-the-art, e.g., outperforming a conditional GAN model in multi-temporal cloud imputation by up to 5pp (or 5.7%) in the structural similarity index. Finally, due to the limited availability of labeled data in the field of Earth observation, we gradually reduce the quantity of available labeled data for refining the model to evaluate data efficiency and demonstrate that data can be decreased significantly without affecting the model's accuracy. The pre-trained 100 million parameter model and corresponding fine-tuning workflows have been released publicly as open source contributions to the global Earth sciences community through Hugging Face.
GEO-Bench: Toward Foundation Models for Earth Monitoring
Jun 06, 2023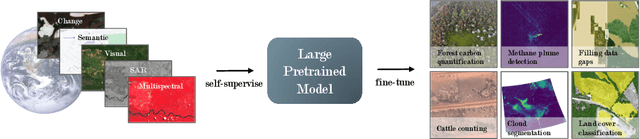
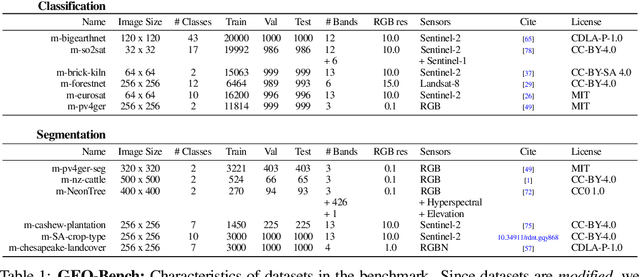

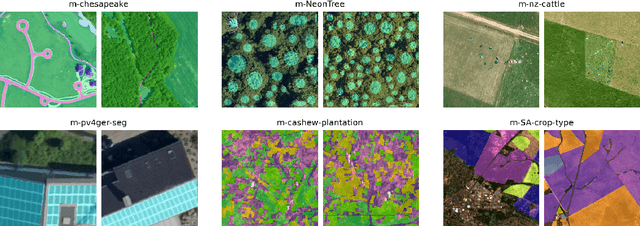
Recent progress in self-supervision has shown that pre-training large neural networks on vast amounts of unsupervised data can lead to substantial increases in generalization to downstream tasks. Such models, recently coined foundation models, have been transformational to the field of natural language processing. Variants have also been proposed for image data, but their applicability to remote sensing tasks is limited. To stimulate the development of foundation models for Earth monitoring, we propose a benchmark comprised of six classification and six segmentation tasks, which were carefully curated and adapted to be both relevant to the field and well-suited for model evaluation. We accompany this benchmark with a robust methodology for evaluating models and reporting aggregated results to enable a reliable assessment of progress. Finally, we report results for 20 baselines to gain information about the performance of existing models. We believe that this benchmark will be a driver of progress across a variety of Earth monitoring tasks.
Toward Foundation Models for Earth Monitoring: Proposal for a Climate Change Benchmark
Dec 01, 2021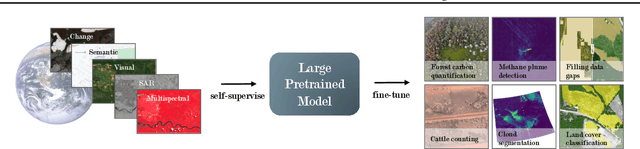
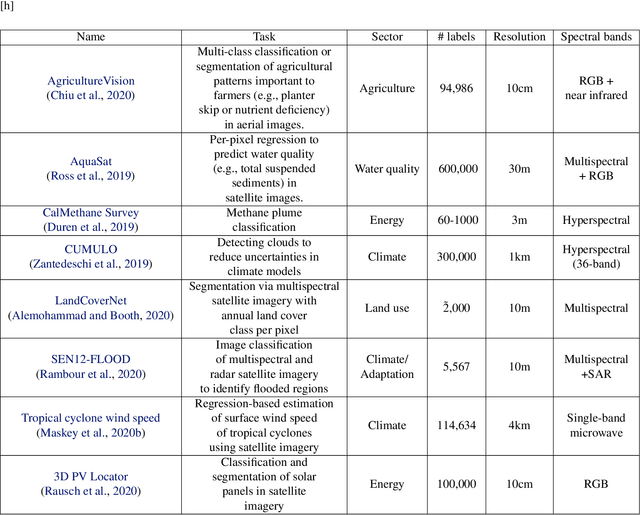
Recent progress in self-supervision shows that pre-training large neural networks on vast amounts of unsupervised data can lead to impressive increases in generalisation for downstream tasks. Such models, recently coined as foundation models, have been transformational to the field of natural language processing. While similar models have also been trained on large corpuses of images, they are not well suited for remote sensing data. To stimulate the development of foundation models for Earth monitoring, we propose to develop a new benchmark comprised of a variety of downstream tasks related to climate change. We believe that this can lead to substantial improvements in many existing applications and facilitate the development of new applications. This proposal is also a call for collaboration with the aim of developing a better evaluation process to mitigate potential downsides of foundation models for Earth monitoring.
LandCoverNet: A global benchmark land cover classification training dataset
Dec 05, 2020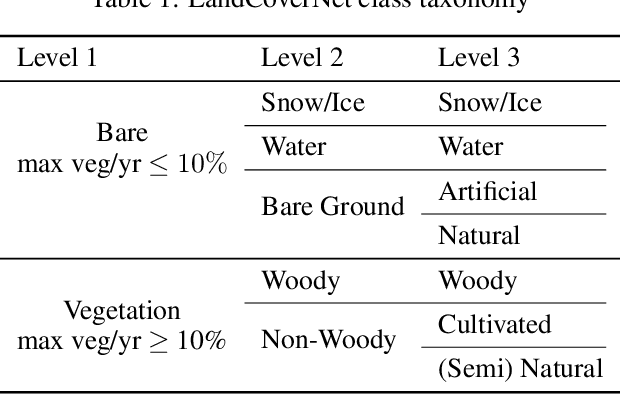
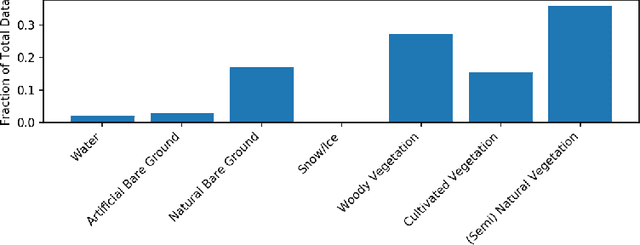
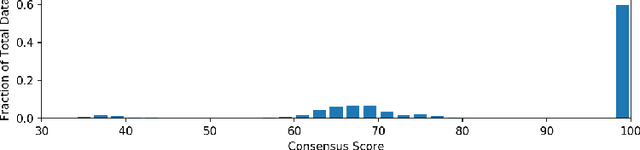
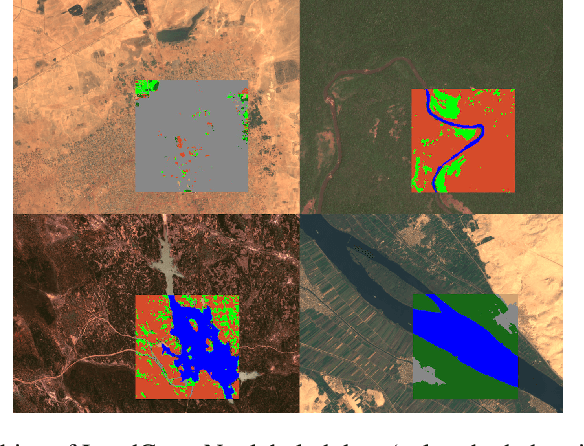
Regularly updated and accurate land cover maps are essential for monitoring 14 of the 17 Sustainable Development Goals. Multispectral satellite imagery provide high-quality and valuable information at global scale that can be used to develop land cover classification models. However, such a global application requires a geographically diverse training dataset. Here, we present LandCoverNet, a global training dataset for land cover classification based on Sentinel-2 observations at 10m spatial resolution. Land cover class labels are defined based on annual time-series of Sentinel-2, and verified by consensus among three human annotators.
Generating Synthetic Multispectral Satellite Imagery from Sentinel-2
Dec 05, 2020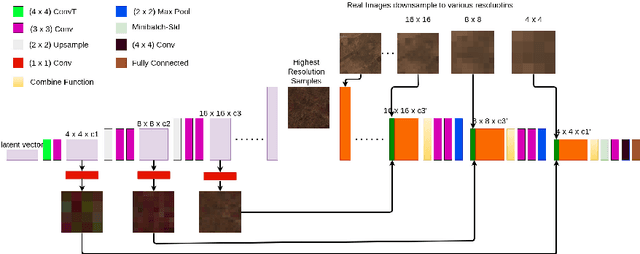
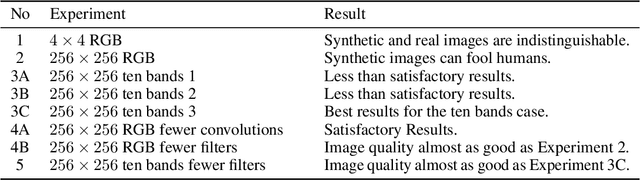

Multi-spectral satellite imagery provides valuable data at global scale for many environmental and socio-economic applications. Building supervised machine learning models based on these imagery, however, may require ground reference labels which are not available at global scale. Here, we propose a generative model to produce multi-resolution multi-spectral imagery based on Sentinel-2 data. The resulting synthetic images are indistinguishable from real ones by humans. This technique paves the road for future work to generate labeled synthetic imagery that can be used for data augmentation in data scarce regions and applications.
Semantic Segmentation of Medium-Resolution Satellite Imagery using Conditional Generative Adversarial Networks
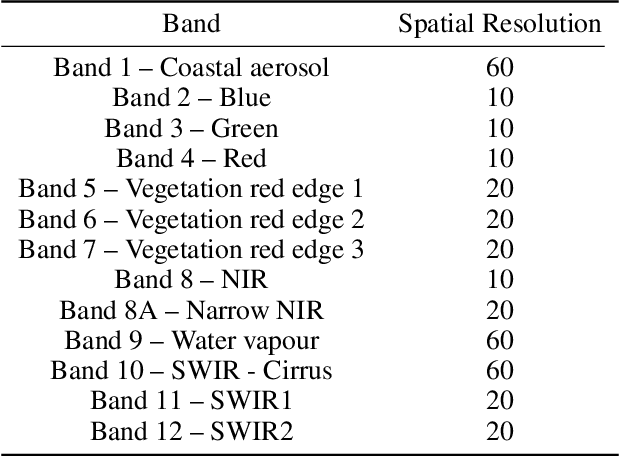
Dec 05, 2020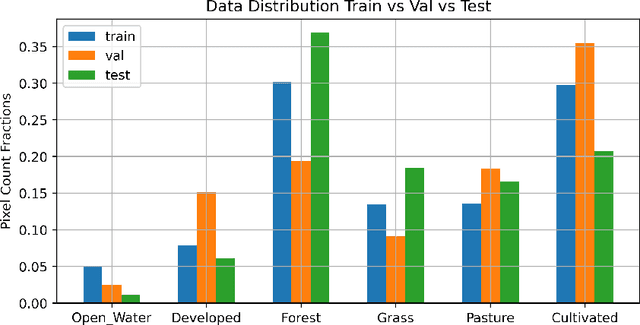
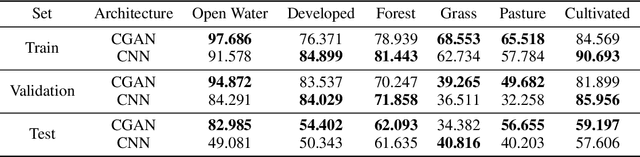


Semantic segmentation of satellite imagery is a common approach to identify patterns and detect changes around the planet. Most of the state-of-the-art semantic segmentation models are trained in a fully supervised way using Convolutional Neural Network (CNN). The generalization property of CNN is poor for satellite imagery because the data can be very diverse in terms of landscape types, image resolutions, and scarcity of labels for different geographies and seasons. Hence, the performance of CNN doesn't translate well to images from unseen regions or seasons. Inspired by Conditional Generative Adversarial Networks (CGAN) based approach of image-to-image translation for high-resolution satellite imagery, we propose a CGAN framework for land cover classification using medium-resolution Sentinel-2 imagery. We find that the CGAN model outperforms the CNN model of similar complexity by a significant margin on an unseen imbalanced test dataset.
Proceedings of the ICLR Workshop on Computer Vision for Agriculture (CV4A) 2020
May 17, 2020This is the proceedings of the Computer Vision for Agriculture (CV4A) Workshop that was held in conjunction with the International Conference on Learning Representations (ICLR) 2020. The Computer Vision for Agriculture (CV4A) 2020 workshop was scheduled to be held in Addis Ababa, Ethiopia, on April 26th, 2020. It was held virtually that same day due to the COVID-19 pandemic. The workshop was held in conjunction with the International Conference on Learning Representations (ICLR) 2020.
Generating a Training Dataset for Land Cover Classification to Advance Global Development
Nov 14, 2018
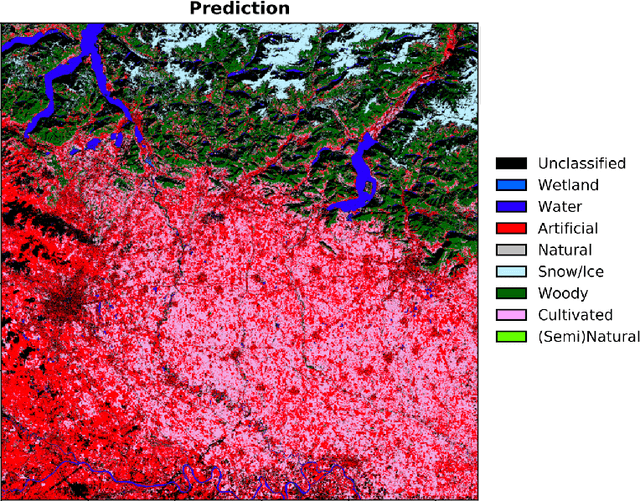
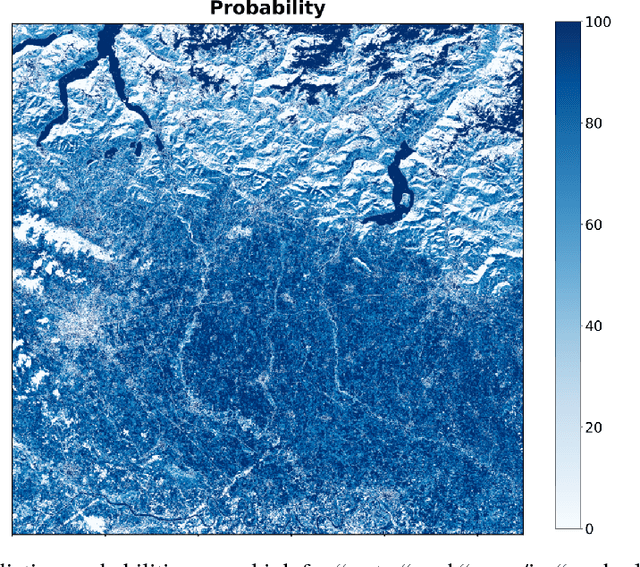
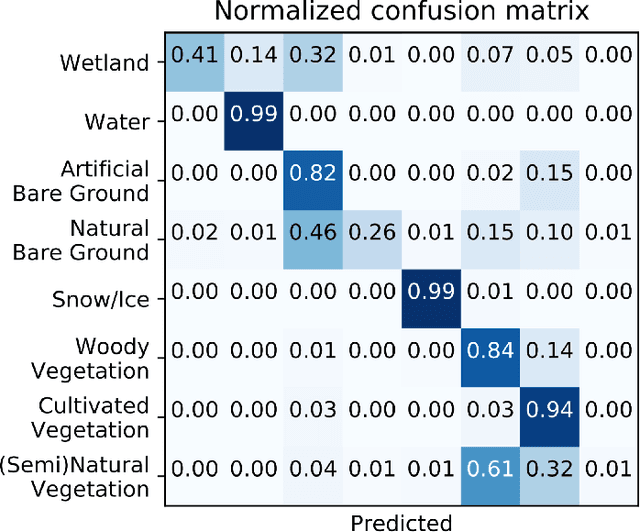
Semantic segmentation of land cover classes is fundamental for agricultural and economic development work, from sustainable forestry to urban planning, yet existing training datasets have significant limitations. To generate an open and comprehensive training library of high resolution Earth imagery and high quality land cover classifications, public Sentinel-2 data at 10 m spatial resolution was matched with accurate GlobeLand30 labels from 2010, which were filtered by agreement with an intermediary Sentinel-2 classification at 20 m produced during atmospheric correction. Scene-level classifications were predicted by Random Forests trained on valid reflectance data and the filtered labels, and achieved over 80% model accuracy for a variety of locations. Further work is required to aggregate individual scene classifications for annual labels and to test the approach in more locations, before crowdsourcing human validation. The goal is to create a sustained community-wide effort to generate image labels not only for land cover, but also very specific images for major agriculture crops across the world and other thematic categories of interest to the global development community.