 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHan Zhong
DPO Meets PPO: Reinforced Token Optimization for RLHF
Apr 29, 2024
In the classical Reinforcement Learning from Human Feedback (RLHF) framework, Proximal Policy Optimization (PPO) is employed to learn from sparse, sentence-level rewards -- a challenging scenario in traditional deep reinforcement learning. Despite the great successes of PPO in the alignment of state-of-the-art closed-source large language models (LLMs), its open-source implementation is still largely sub-optimal, as widely reported by numerous research studies. To address these issues, we introduce a framework that models RLHF problems as a Markov decision process (MDP), enabling the capture of fine-grained token-wise information. Furthermore, we provide theoretical insights that demonstrate the superiority of our MDP framework over the previous sentence-level bandit formulation. Under this framework, we introduce an algorithm, dubbed as Reinforced Token Optimization (\texttt{RTO}), which learns the token-wise reward function from preference data and performs policy optimization based on this learned token-wise reward signal. Theoretically, \texttt{RTO} is proven to have the capability of finding the near-optimal policy sample-efficiently. For its practical implementation, \texttt{RTO} innovatively integrates Direct Preference Optimization (DPO) and PPO. DPO, originally derived from sparse sentence rewards, surprisingly provides us with a token-wise characterization of response quality, which is seamlessly incorporated into our subsequent PPO training stage. Extensive real-world alignment experiments verify the effectiveness of the proposed approach.
Sample-efficient Learning of Infinite-horizon Average-reward MDPs with General Function Approximation
Apr 19, 2024We study infinite-horizon average-reward Markov decision processes (AMDPs) in the context of general function approximation. Specifically, we propose a novel algorithmic framework named Local-fitted Optimization with OPtimism (LOOP), which incorporates both model-based and value-based incarnations. In particular, LOOP features a novel construction of confidence sets and a low-switching policy updating scheme, which are tailored to the average-reward and function approximation setting. Moreover, for AMDPs, we propose a novel complexity measure -- average-reward generalized eluder coefficient (AGEC) -- which captures the challenge of exploration in AMDPs with general function approximation. Such a complexity measure encompasses almost all previously known tractable AMDP models, such as linear AMDPs and linear mixture AMDPs, and also includes newly identified cases such as kernel AMDPs and AMDPs with Bellman eluder dimensions. Using AGEC, we prove that LOOP achieves a sublinear $\tilde{\mathcal{O}}(\mathrm{poly}(d, \mathrm{sp}(V^*)) \sqrt{T\beta} )$ regret, where $d$ and $\beta$ correspond to AGEC and log-covering number of the hypothesis class respectively, $\mathrm{sp}(V^*)$ is the span of the optimal state bias function, $T$ denotes the number of steps, and $\tilde{\mathcal{O}} (\cdot) $ omits logarithmic factors. When specialized to concrete AMDP models, our regret bounds are comparable to those established by the existing algorithms designed specifically for these special cases. To the best of our knowledge, this paper presents the first comprehensive theoretical framework capable of handling nearly all AMDPs.
Distributionally Robust Reinforcement Learning with Interactive Data Collection: Fundamental Hardness and Near-Optimal Algorithm
Apr 04, 2024The sim-to-real gap, which represents the disparity between training and testing environments, poses a significant challenge in reinforcement learning (RL). A promising approach to addressing this challenge is distributionally robust RL, often framed as a robust Markov decision process (RMDP). In this framework, the objective is to find a robust policy that achieves good performance under the worst-case scenario among all environments within a pre-specified uncertainty set centered around the training environment. Unlike previous work, which relies on a generative model or a pre-collected offline dataset enjoying good coverage of the deployment environment, we tackle robust RL via interactive data collection, where the learner interacts with the training environment only and refines the policy through trial and error. In this robust RL paradigm, two main challenges emerge: managing distributional robustness while striking a balance between exploration and exploitation during data collection. Initially, we establish that sample-efficient learning without additional assumptions is unattainable owing to the curse of support shift; i.e., the potential disjointedness of the distributional supports between the training and testing environments. To circumvent such a hardness result, we introduce the vanishing minimal value assumption to RMDPs with a total-variation (TV) distance robust set, postulating that the minimal value of the optimal robust value function is zero. We prove that such an assumption effectively eliminates the support shift issue for RMDPs with a TV distance robust set, and present an algorithm with a provable sample complexity guarantee. Our work makes the initial step to uncovering the inherent difficulty of robust RL via interactive data collection and sufficient conditions for designing a sample-efficient algorithm accompanied by sharp sample complexity analysis.
Rewards-in-Context: Multi-objective Alignment of Foundation Models with Dynamic Preference Adjustment
Feb 25, 2024We consider the problem of multi-objective alignment of foundation models with human preferences, which is a critical step towards helpful and harmless AI systems. However, it is generally costly and unstable to fine-tune large foundation models using reinforcement learning (RL), and the multi-dimensionality, heterogeneity, and conflicting nature of human preferences further complicate the alignment process. In this paper, we introduce Rewards-in-Context (RiC), which conditions the response of a foundation model on multiple rewards in its prompt context and applies supervised fine-tuning for alignment. The salient features of RiC are simplicity and adaptivity, as it only requires supervised fine-tuning of a single foundation model and supports dynamic adjustment for user preferences during inference time. Inspired by the analytical solution of an abstracted convex optimization problem, our dynamic inference-time adjustment method approaches the Pareto-optimal solution for multiple objectives. Empirical evidence demonstrates the efficacy of our method in aligning both Large Language Models (LLMs) and diffusion models to accommodate diverse rewards with only around 10% GPU hours compared with multi-objective RL baseline.
Rethinking Model-based, Policy-based, and Value-based Reinforcement Learning via the Lens of Representation Complexity
Dec 28, 2023Reinforcement Learning (RL) encompasses diverse paradigms, including model-based RL, policy-based RL, and value-based RL, each tailored to approximate the model, optimal policy, and optimal value function, respectively. This work investigates the potential hierarchy of representation complexity -- the complexity of functions to be represented -- among these RL paradigms. We first demonstrate that, for a broad class of Markov decision processes (MDPs), the model can be represented by constant-depth circuits with polynomial size or Multi-Layer Perceptrons (MLPs) with constant layers and polynomial hidden dimension. However, the representation of the optimal policy and optimal value proves to be $\mathsf{NP}$-complete and unattainable by constant-layer MLPs with polynomial size. This demonstrates a significant representation complexity gap between model-based RL and model-free RL, which includes policy-based RL and value-based RL. To further explore the representation complexity hierarchy between policy-based RL and value-based RL, we introduce another general class of MDPs where both the model and optimal policy can be represented by constant-depth circuits with polynomial size or constant-layer MLPs with polynomial size. In contrast, representing the optimal value is $\mathsf{P}$-complete and intractable via a constant-layer MLP with polynomial hidden dimension. This accentuates the intricate representation complexity associated with value-based RL compared to policy-based RL. In summary, we unveil a potential representation complexity hierarchy within RL -- representing the model emerges as the easiest task, followed by the optimal policy, while representing the optimal value function presents the most intricate challenge.
Gibbs Sampling from Human Feedback: A Provable KL- constrained Framework for RLHF
Dec 18, 2023This paper studies the theoretical framework of the alignment process of generative models with Reinforcement Learning from Human Feedback (RLHF). We consider a standard mathematical formulation, the reverse-KL regularized contextual bandit for RLHF. Despite its widespread practical application, a rigorous theoretical analysis of this formulation remains open. We investigate its theoretical properties both in offline and online settings and propose efficient algorithms with finite-sample theoretical guarantees. Our work bridges the gap between theory and practice by linking our theoretical insights with existing practical alignment algorithms such as Direct Preference Optimization (DPO) and Rejection Sampling Optimization (RSO). Furthermore, these findings and connections also offer both theoretical and practical communities new tools and insights for future algorithmic design of alignment algorithms.
Horizon-Free and Instance-Dependent Regret Bounds for Reinforcement Learning with General Function Approximation
Dec 07, 2023To tackle long planning horizon problems in reinforcement learning with general function approximation, we propose the first algorithm, termed as UCRL-WVTR, that achieves both \emph{horizon-free} and \emph{instance-dependent}, since it eliminates the polynomial dependency on the planning horizon. The derived regret bound is deemed \emph{sharp}, as it matches the minimax lower bound when specialized to linear mixture MDPs up to logarithmic factors. Furthermore, UCRL-WVTR is \emph{computationally efficient} with access to a regression oracle. The achievement of such a horizon-free, instance-dependent, and sharp regret bound hinges upon (i) novel algorithm designs: weighted value-targeted regression and a high-order moment estimator in the context of general function approximation; and (ii) fine-grained analyses: a novel concentration bound of weighted non-linear least squares and a refined analysis which leads to the tight instance-dependent bound. We also conduct comprehensive experiments to corroborate our theoretical findings.
Posterior Sampling for Competitive RL: Function Approximation and Partial Observation
Oct 30, 2023This paper investigates posterior sampling algorithms for competitive reinforcement learning (RL) in the context of general function approximations. Focusing on zero-sum Markov games (MGs) under two critical settings, namely self-play and adversarial learning, we first propose the self-play and adversarial generalized eluder coefficient (GEC) as complexity measures for function approximation, capturing the exploration-exploitation trade-off in MGs. Based on self-play GEC, we propose a model-based self-play posterior sampling method to control both players to learn Nash equilibrium, which can successfully handle the partial observability of states. Furthermore, we identify a set of partially observable MG models fitting MG learning with the adversarial policies of the opponent. Incorporating the adversarial GEC, we propose a model-based posterior sampling method for learning adversarial MG with potential partial observability. We further provide low regret bounds for proposed algorithms that can scale sublinearly with the proposed GEC and the number of episodes $T$. To the best of our knowledge, we for the first time develop generic model-based posterior sampling algorithms for competitive RL that can be applied to a majority of tractable zero-sum MG classes in both fully observable and partially observable MGs with self-play and adversarial learning.
Towards Robust Offline Reinforcement Learning under Diverse Data Corruption
Oct 19, 2023Offline reinforcement learning (RL) presents a promising approach for learning reinforced policies from offline datasets without the need for costly or unsafe interactions with the environment. However, datasets collected by humans in real-world environments are often noisy and may even be maliciously corrupted, which can significantly degrade the performance of offline RL. In this work, we first investigate the performance of current offline RL algorithms under comprehensive data corruption, including states, actions, rewards, and dynamics. Our extensive experiments reveal that implicit Q-learning (IQL) demonstrates remarkable resilience to data corruption among various offline RL algorithms. Furthermore, we conduct both empirical and theoretical analyses to understand IQL's robust performance, identifying its supervised policy learning scheme as the key factor. Despite its relative robustness, IQL still suffers from heavy-tail targets of Q functions under dynamics corruption. To tackle this challenge, we draw inspiration from robust statistics to employ the Huber loss to handle the heavy-tailedness and utilize quantile estimators to balance penalization for corrupted data and learning stability. By incorporating these simple yet effective modifications into IQL, we propose a more robust offline RL approach named Robust IQL (RIQL). Extensive experiments demonstrate that RIQL exhibits highly robust performance when subjected to diverse data corruption scenarios.
Tackling Heavy-Tailed Rewards in Reinforcement Learning with Function Approximation: Minimax Optimal and Instance-Dependent Regret Bounds
Jun 12, 2023
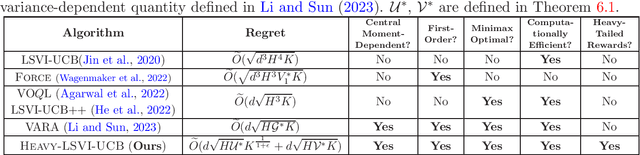
While numerous works have focused on devising efficient algorithms for reinforcement learning (RL) with uniformly bounded rewards, it remains an open question whether sample or time-efficient algorithms for RL with large state-action space exist when the rewards are \emph{heavy-tailed}, i.e., with only finite $(1+\epsilon)$-th moments for some $\epsilon\in(0,1]$. In this work, we address the challenge of such rewards in RL with linear function approximation. We first design an algorithm, \textsc{Heavy-OFUL}, for heavy-tailed linear bandits, achieving an \emph{instance-dependent} $T$-round regret of $\tilde{O}\big(d T^{\frac{1-\epsilon}{2(1+\epsilon)}} \sqrt{\sum_{t=1}^T \nu_t^2} + d T^{\frac{1-\epsilon}{2(1+\epsilon)}}\big)$, the \emph{first} of this kind. Here, $d$ is the feature dimension, and $\nu_t^{1+\epsilon}$ is the $(1+\epsilon)$-th central moment of the reward at the $t$-th round. We further show the above bound is minimax optimal when applied to the worst-case instances in stochastic and deterministic linear bandits. We then extend this algorithm to the RL settings with linear function approximation. Our algorithm, termed as \textsc{Heavy-LSVI-UCB}, achieves the \emph{first} computationally efficient \emph{instance-dependent} $K$-episode regret of $\tilde{O}(d \sqrt{H \mathcal{U}^*} K^\frac{1}{1+\epsilon} + d \sqrt{H \mathcal{V}^* K})$. Here, $H$ is length of the episode, and $\mathcal{U}^*, \mathcal{V}^*$ are instance-dependent quantities scaling with the central moment of reward and value functions, respectively. We also provide a matching minimax lower bound $\Omega(d H K^{\frac{1}{1+\epsilon}} + d \sqrt{H^3 K})$ to demonstrate the optimality of our algorithm in the worst case. Our result is achieved via a novel robust self-normalized concentration inequality that may be of independent interest in handling heavy-tailed noise in general online regression problems.