 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJose Blanchet
Stability Evaluation via Distributional Perturbation Analysis
May 06, 2024
The performance of learning models often deteriorates when deployed in out-of-sample environments. To ensure reliable deployment, we propose a stability evaluation criterion based on distributional perturbations. Conceptually, our stability evaluation criterion is defined as the minimal perturbation required on our observed dataset to induce a prescribed deterioration in risk evaluation. In this paper, we utilize the optimal transport (OT) discrepancy with moment constraints on the \textit{(sample, density)} space to quantify this perturbation. Therefore, our stability evaluation criterion can address both \emph{data corruptions} and \emph{sub-population shifts} -- the two most common types of distribution shifts in real-world scenarios. To further realize practical benefits, we present a series of tractable convex formulations and computational methods tailored to different classes of loss functions. The key technical tool to achieve this is the strong duality theorem provided in this paper. Empirically, we validate the practical utility of our stability evaluation criterion across a host of real-world applications. These empirical studies showcase the criterion's ability not only to compare the stability of different learning models and features but also to provide valuable guidelines and strategies to further improve models.
Orthogonal Bootstrap: Efficient Simulation of Input Uncertainty
May 01, 2024Bootstrap is a popular methodology for simulating input uncertainty. However, it can be computationally expensive when the number of samples is large. We propose a new approach called \textbf{Orthogonal Bootstrap} that reduces the number of required Monte Carlo replications. We decomposes the target being simulated into two parts: the \textit{non-orthogonal part} which has a closed-form result known as Infinitesimal Jackknife and the \textit{orthogonal part} which is easier to be simulated. We theoretically and numerically show that Orthogonal Bootstrap significantly reduces the computational cost of Bootstrap while improving empirical accuracy and maintaining the same width of the constructed interval.
Distributionally Robust Reinforcement Learning with Interactive Data Collection: Fundamental Hardness and Near-Optimal Algorithm
Apr 04, 2024The sim-to-real gap, which represents the disparity between training and testing environments, poses a significant challenge in reinforcement learning (RL). A promising approach to addressing this challenge is distributionally robust RL, often framed as a robust Markov decision process (RMDP). In this framework, the objective is to find a robust policy that achieves good performance under the worst-case scenario among all environments within a pre-specified uncertainty set centered around the training environment. Unlike previous work, which relies on a generative model or a pre-collected offline dataset enjoying good coverage of the deployment environment, we tackle robust RL via interactive data collection, where the learner interacts with the training environment only and refines the policy through trial and error. In this robust RL paradigm, two main challenges emerge: managing distributional robustness while striking a balance between exploration and exploitation during data collection. Initially, we establish that sample-efficient learning without additional assumptions is unattainable owing to the curse of support shift; i.e., the potential disjointedness of the distributional supports between the training and testing environments. To circumvent such a hardness result, we introduce the vanishing minimal value assumption to RMDPs with a total-variation (TV) distance robust set, postulating that the minimal value of the optimal robust value function is zero. We prove that such an assumption effectively eliminates the support shift issue for RMDPs with a TV distance robust set, and present an algorithm with a provable sample complexity guarantee. Our work makes the initial step to uncovering the inherent difficulty of robust RL via interactive data collection and sufficient conditions for designing a sample-efficient algorithm accompanied by sharp sample complexity analysis.
Automatic Outlier Rectification via Optimal Transport
Mar 21, 2024

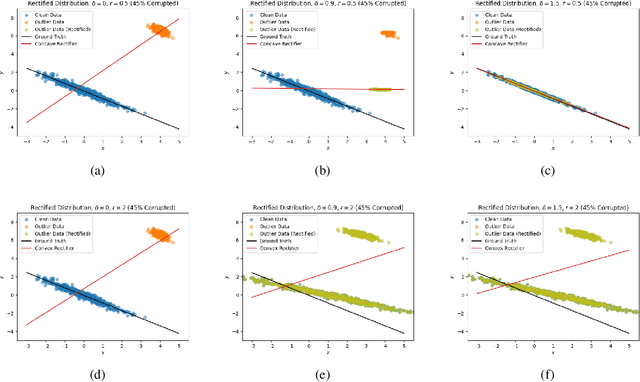
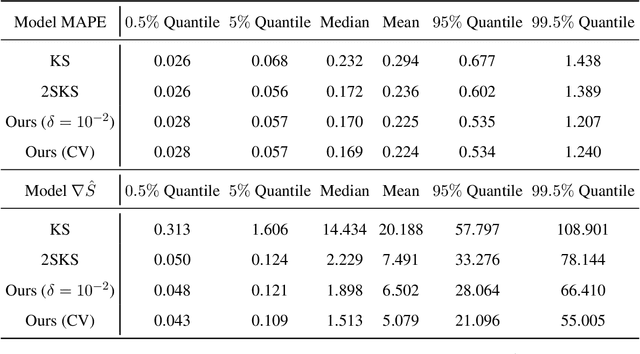
In this paper, we propose a novel conceptual framework to detect outliers using optimal transport with a concave cost function. Conventional outlier detection approaches typically use a two-stage procedure: first, outliers are detected and removed, and then estimation is performed on the cleaned data. However, this approach does not inform outlier removal with the estimation task, leaving room for improvement. To address this limitation, we propose an automatic outlier rectification mechanism that integrates rectification and estimation within a joint optimization framework. We take the first step to utilize an optimal transport distance with a concave cost function to construct a rectification set in the space of probability distributions. Then, we select the best distribution within the rectification set to perform the estimation task. Notably, the concave cost function we introduced in this paper is the key to making our estimator effectively identify the outlier during the optimization process. We discuss the fundamental differences between our estimator and optimal transport-based distributionally robust optimization estimator. finally, we demonstrate the effectiveness and superiority of our approach over conventional approaches in extensive simulation and empirical analyses for mean estimation, least absolute regression, and the fitting of option implied volatility surfaces.
Accelerated Sampling of Rare Events using a Neural Network Bias Potential
Jan 13, 2024In the field of computational physics and material science, the efficient sampling of rare events occurring at atomic scale is crucial. It aids in understanding mechanisms behind a wide range of important phenomena, including protein folding, conformal changes, chemical reactions and materials diffusion and deformation. Traditional simulation methods, such as Molecular Dynamics and Monte Carlo, often prove inefficient in capturing the timescale of these rare events by brute force. In this paper, we introduce a practical approach by combining the idea of importance sampling with deep neural networks (DNNs) that enhance the sampling of these rare events. In particular, we approximate the variance-free bias potential function with DNNs which is trained to maximize the probability of rare event transition under the importance potential function. This method is easily scalable to high-dimensional problems and provides robust statistical guarantees on the accuracy of the estimated probability of rare event transition. Furthermore, our algorithm can actively generate and learn from any successful samples, which is a novel improvement over existing methods. Using a 2D system as a test bed, we provide comparisons between results obtained from different training strategies, traditional Monte Carlo sampling and numerically solved optimal bias potential function under different temperatures. Our numerical results demonstrate the efficacy of the DNN-based importance sampling of rare events.
On the Foundation of Distributionally Robust Reinforcement Learning
Nov 15, 2023Motivated by the need for a robust policy in the face of environment shifts between training and the deployment, we contribute to the theoretical foundation of distributionally robust reinforcement learning (DRRL). This is accomplished through a comprehensive modeling framework centered around distributionally robust Markov decision processes (DRMDPs). This framework obliges the decision maker to choose an optimal policy under the worst-case distributional shift orchestrated by an adversary. By unifying and extending existing formulations, we rigorously construct DRMDPs that embraces various modeling attributes for both the decision maker and the adversary. These attributes include adaptability granularity, exploring history-dependent, Markov, and Markov time-homogeneous decision maker and adversary dynamics. Additionally, we delve into the flexibility of shifts induced by the adversary, examining SA and S-rectangularity. Within this DRMDP framework, we investigate conditions for the existence or absence of the dynamic programming principle (DPP). From an algorithmic standpoint, the existence of DPP holds significant implications, as the vast majority of existing data and computationally efficiency RL algorithms are reliant on the DPP. To study its existence, we comprehensively examine combinations of controller and adversary attributes, providing streamlined proofs grounded in a unified methodology. We also offer counterexamples for settings in which a DPP with full generality is absent.
Payoff-based learning with matrix multiplicative weights in quantum games
Nov 04, 2023In this paper, we study the problem of learning in quantum games - and other classes of semidefinite games - with scalar, payoff-based feedback. For concreteness, we focus on the widely used matrix multiplicative weights (MMW) algorithm and, instead of requiring players to have full knowledge of the game (and/or each other's chosen states), we introduce a suite of minimal-information matrix multiplicative weights (3MW) methods tailored to different information frameworks. The main difficulty to attaining convergence in this setting is that, in contrast to classical finite games, quantum games have an infinite continuum of pure states (the quantum equivalent of pure strategies), so standard importance-weighting techniques for estimating payoff vectors cannot be employed. Instead, we borrow ideas from bandit convex optimization and we design a zeroth-order gradient sampler adapted to the semidefinite geometry of the problem at hand. As a first result, we show that the 3MW method with deterministic payoff feedback retains the $\mathcal{O}(1/\sqrt{T})$ convergence rate of the vanilla, full information MMW algorithm in quantum min-max games, even though the players only observe a single scalar. Subsequently, we relax the algorithm's information requirements even further and we provide a 3MW method that only requires players to observe a random realization of their payoff observable, and converges to equilibrium at an $\mathcal{O}(T^{-1/4})$ rate. Finally, going beyond zero-sum games, we show that a regularized variant of the proposed 3MW method guarantees local convergence with high probability to all equilibria that satisfy a certain first-order stability condition.
Optimal Sample Complexity for Average Reward Markov Decision Processes
Oct 13, 2023

We settle the sample complexity of policy learning for the maximization of the long run average reward associated with a uniformly ergodic Markov decision process (MDP), assuming a generative model. In this context, the existing literature provides a sample complexity upper bound of $\widetilde O(|S||A|t_{\text{mix}}^2 \epsilon^{-2})$ and a lower bound of $\Omega(|S||A|t_{\text{mix}} \epsilon^{-2})$. In these expressions, $|S|$ and $|A|$ denote the cardinalities of the state and action spaces respectively, $t_{\text{mix}}$ serves as a uniform upper limit for the total variation mixing times, and $\epsilon$ signifies the error tolerance. Therefore, a notable gap of $t_{\text{mix}}$ still remains to be bridged. Our primary contribution is to establish an estimator for the optimal policy of average reward MDPs with a sample complexity of $\widetilde O(|S||A|t_{\text{mix}}\epsilon^{-2})$, effectively reaching the lower bound in the literature. This is achieved by combining algorithmic ideas in Jin and Sidford (2021) with those of Li et al. (2020).
Unifying Distributionally Robust Optimization via Optimal Transport Theory
Aug 10, 2023
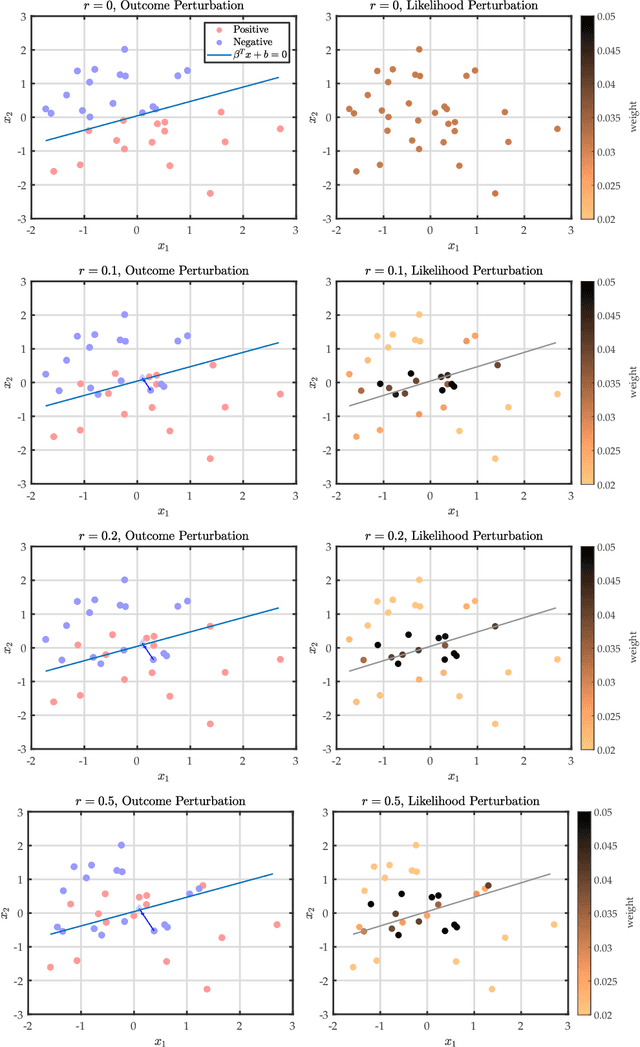
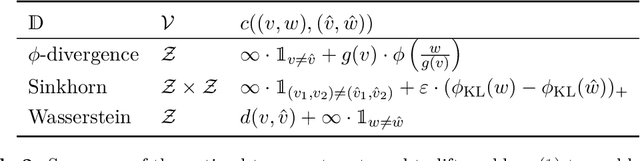
In the past few years, there has been considerable interest in two prominent approaches for Distributionally Robust Optimization (DRO): Divergence-based and Wasserstein-based methods. The divergence approach models misspecification in terms of likelihood ratios, while the latter models it through a measure of distance or cost in actual outcomes. Building upon these advances, this paper introduces a novel approach that unifies these methods into a single framework based on optimal transport (OT) with conditional moment constraints. Our proposed approach, for example, makes it possible for optimal adversarial distributions to simultaneously perturb likelihood and outcomes, while producing an optimal (in an optimal transport sense) coupling between the baseline model and the adversarial model.Additionally, the paper investigates several duality results and presents tractable reformulations that enhance the practical applicability of this unified framework.
Sample Complexity of Variance-reduced Distributionally Robust Q-learning
May 28, 2023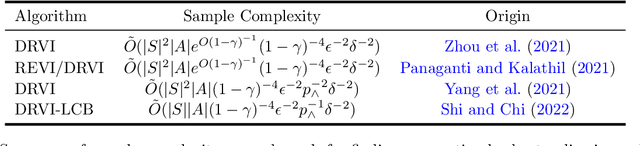
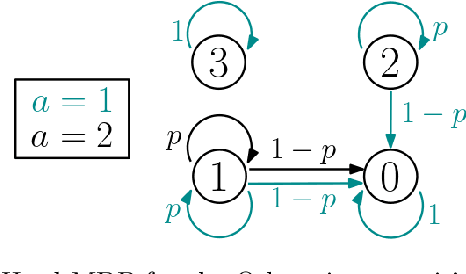

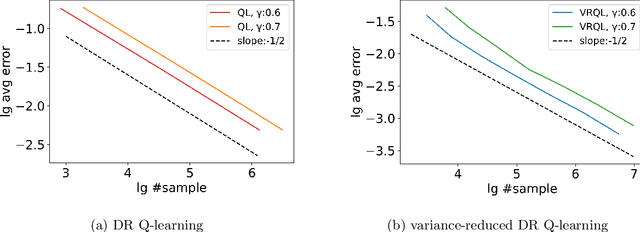
Dynamic decision making under distributional shifts is of fundamental interest in theory and applications of reinforcement learning: The distribution of the environment on which the data is collected can differ from that of the environment on which the model is deployed. This paper presents two novel model-free algorithms, namely the distributionally robust Q-learning and its variance-reduced counterpart, that can effectively learn a robust policy despite distributional shifts. These algorithms are designed to efficiently approximate the $q$-function of an infinite-horizon $\gamma$-discounted robust Markov decision process with Kullback-Leibler uncertainty set to an entry-wise $\epsilon$-degree of precision. Further, the variance-reduced distributionally robust Q-learning combines the synchronous Q-learning with variance-reduction techniques to enhance its performance. Consequently, we establish that it attains a minmax sample complexity upper bound of $\tilde O(|S||A|(1-\gamma)^{-4}\epsilon^{-2})$, where $S$ and $A$ denote the state and action spaces. This is the first complexity result that is independent of the uncertainty size $\delta$, thereby providing new complexity theoretic insights. Additionally, a series of numerical experiments confirm the theoretical findings and the efficiency of the algorithms in handling distributional shifts.