 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShengbo Wang
Local stochastic computing using memristor-enabled stochastic logics
Feb 25, 2024
Stochastic computing offers a probabilistic approach to address challenges posed by problems with uncertainty and noise in various fields, particularly machine learning. The realization of stochastic computing, however, faces the limitation of developing reliable stochastic logics. Here, we present stochastic logics development using memristors. Specifically, we integrate memristors into logic circuits to design the stochastic logics, wherein the inherent stochasticity in memristor switching is harnessed to enable stochastic number encoding and processing with well-regulated probabilities and correlations. As a practical application of the stochastic logics, we design a compact stochastic Roberts cross operator for edge detection. Remarkably, the operator demonstrates exceptional contour and texture extractions, even in the presence of 50% noise, and owning to the probabilistic nature and compact design, the operator can consume 95% less computational costs required by conventional binary computing. The results underscore the great potential of our stochastic computing approach as a lightweight local solution to machine learning challenges in autonomous driving, virtual reality, medical diagnosis, industrial automation, and beyond.
Constrained Bayesian Optimization Under Partial Observations: Balanced Improvements and Provable Convergence
Dec 23, 2023The partially observable constrained optimization problems (POCOPs) impede data-driven optimization techniques since an infeasible solution of POCOPs can provide little information about the objective as well as the constraints. We endeavor to design an efficient and provable method for expensive POCOPs under the framework of constrained Bayesian optimization. Our method consists of two key components. Firstly, we present an improved design of the acquisition functions that introduces balanced exploration during optimization. We rigorously study the convergence properties of this design to demonstrate its effectiveness. Secondly, we propose a Gaussian process embedding different likelihoods as the surrogate model for a partially observable constraint. This model leads to a more accurate representation of the feasible regions compared to traditional classification-based models. Our proposed method is empirically studied on both synthetic and real-world problems. The results demonstrate the competitiveness of our method for solving POCOPs.
On the Foundation of Distributionally Robust Reinforcement Learning
Nov 15, 2023Motivated by the need for a robust policy in the face of environment shifts between training and the deployment, we contribute to the theoretical foundation of distributionally robust reinforcement learning (DRRL). This is accomplished through a comprehensive modeling framework centered around distributionally robust Markov decision processes (DRMDPs). This framework obliges the decision maker to choose an optimal policy under the worst-case distributional shift orchestrated by an adversary. By unifying and extending existing formulations, we rigorously construct DRMDPs that embraces various modeling attributes for both the decision maker and the adversary. These attributes include adaptability granularity, exploring history-dependent, Markov, and Markov time-homogeneous decision maker and adversary dynamics. Additionally, we delve into the flexibility of shifts induced by the adversary, examining SA and S-rectangularity. Within this DRMDP framework, we investigate conditions for the existence or absence of the dynamic programming principle (DPP). From an algorithmic standpoint, the existence of DPP holds significant implications, as the vast majority of existing data and computationally efficiency RL algorithms are reliant on the DPP. To study its existence, we comprehensively examine combinations of controller and adversary attributes, providing streamlined proofs grounded in a unified methodology. We also offer counterexamples for settings in which a DPP with full generality is absent.
Optimal Sample Complexity for Average Reward Markov Decision Processes
Oct 13, 2023

We settle the sample complexity of policy learning for the maximization of the long run average reward associated with a uniformly ergodic Markov decision process (MDP), assuming a generative model. In this context, the existing literature provides a sample complexity upper bound of $\widetilde O(|S||A|t_{\text{mix}}^2 \epsilon^{-2})$ and a lower bound of $\Omega(|S||A|t_{\text{mix}} \epsilon^{-2})$. In these expressions, $|S|$ and $|A|$ denote the cardinalities of the state and action spaces respectively, $t_{\text{mix}}$ serves as a uniform upper limit for the total variation mixing times, and $\epsilon$ signifies the error tolerance. Therefore, a notable gap of $t_{\text{mix}}$ still remains to be bridged. Our primary contribution is to establish an estimator for the optimal policy of average reward MDPs with a sample complexity of $\widetilde O(|S||A|t_{\text{mix}}\epsilon^{-2})$, effectively reaching the lower bound in the literature. This is achieved by combining algorithmic ideas in Jin and Sidford (2021) with those of Li et al. (2020).
Intelligent machines work in unstructured environments by differential neural computing
Oct 03, 2023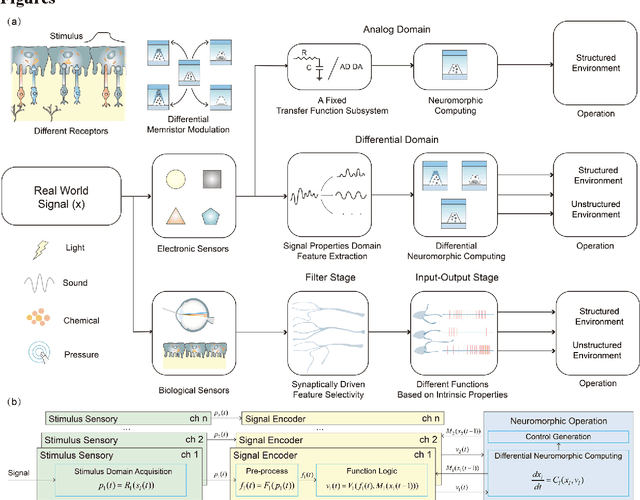
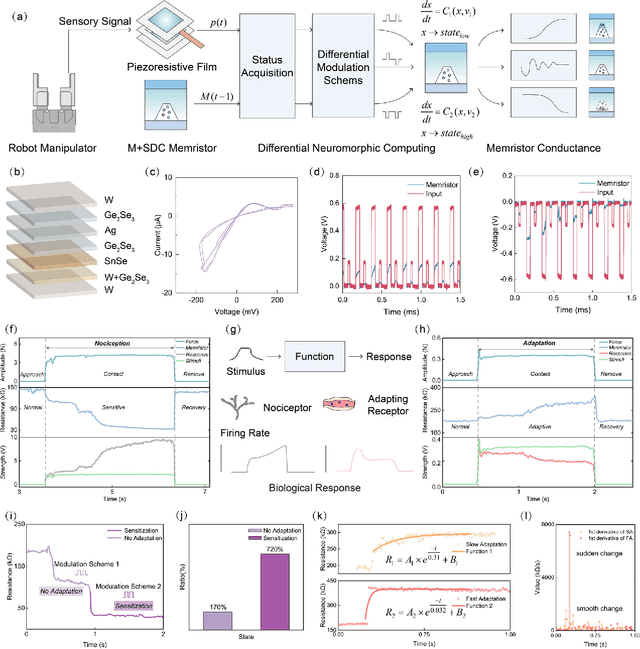
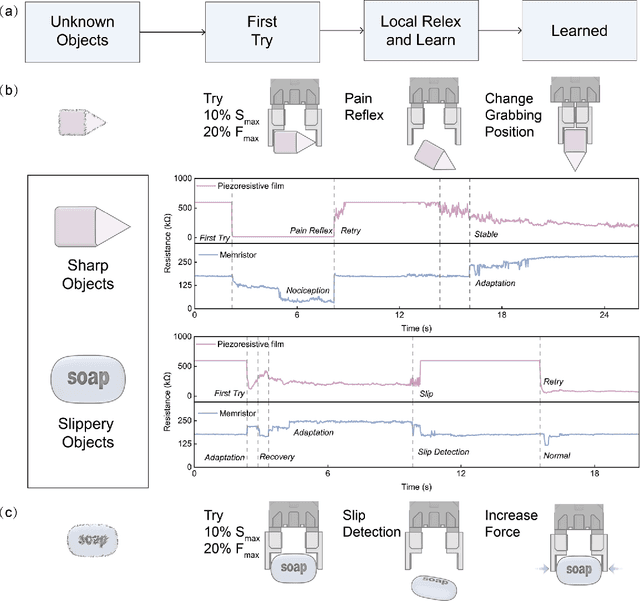
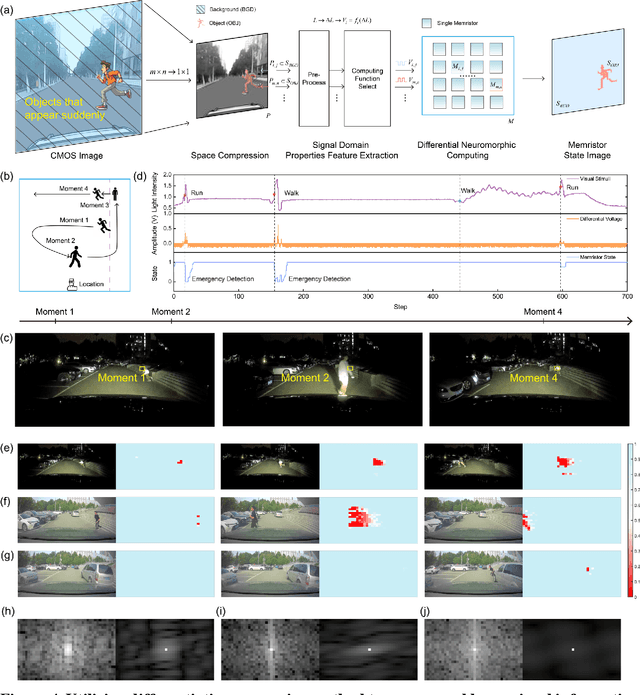
Expecting intelligent machines to efficiently work in real world requires a new method to understand unstructured information in unknown environments with good accuracy, scalability and generalization, like human. Here, a memristive neural computing based perceptual signal differential processing and learning method for intelligent machines is presented, via extracting main features of environmental information and applying associated encoded stimuli to memristors, we successfully obtain human-like ability in processing unstructured environmental information, such as amplification (>720%) and adaptation (<50%) of mechanical stimuli. The method also exhibits good scalability and generalization, validated in two typical applications of intelligent machines: object grasping and autonomous driving. In the former, a robot hand experimentally realizes safe and stable grasping, through learning unknown object features (e.g., sharp corner and smooth surface) with a single memristor in 1 ms. In the latter, the decision-making information of 10 unstructured environments in autonomous driving (e.g., overtaking cars, pedestrians) are accurately (94%) extracted with a 40x25 memristor array. By mimicking the intrinsic nature of human low-level perception mechanisms in electronic memristive neural circuits, the proposed method is adaptable to diverse sensing technologies, helping intelligent machines to generate smart high-level decisions in real world.
Model-Assisted Probabilistic Safe Adaptive Control With Meta-Bayesian Learning
Jul 13, 2023
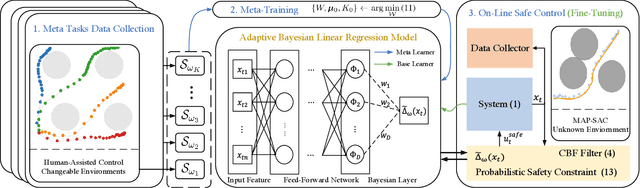
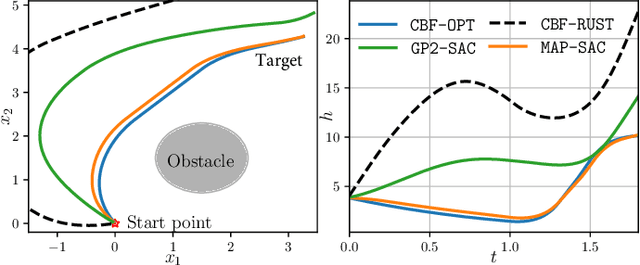
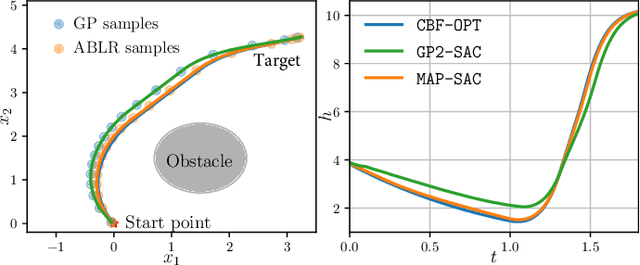
Breaking safety constraints in control systems can lead to potential risks, resulting in unexpected costs or catastrophic damage. Nevertheless, uncertainty is ubiquitous, even among similar tasks. In this paper, we develop a novel adaptive safe control framework that integrates meta learning, Bayesian models, and control barrier function (CBF) method. Specifically, with the help of CBF method, we learn the inherent and external uncertainties by a unified adaptive Bayesian linear regression (ABLR) model, which consists of a forward neural network (NN) and a Bayesian output layer. Meta learning techniques are leveraged to pre-train the NN weights and priors of the ABLR model using data collected from historical similar tasks. For a new control task, we refine the meta-learned models using a few samples, and introduce pessimistic confidence bounds into CBF constraints to ensure safe control. Moreover, we provide theoretical criteria to guarantee probabilistic safety during the control processes. To validate our approach, we conduct comparative experiments in various obstacle avoidance scenarios. The results demonstrate that our algorithm significantly improves the Bayesian model-based CBF method, and is capable for efficient safe exploration even with multiple uncertain constraints.
Sample Complexity of Variance-reduced Distributionally Robust Q-learning
May 28, 2023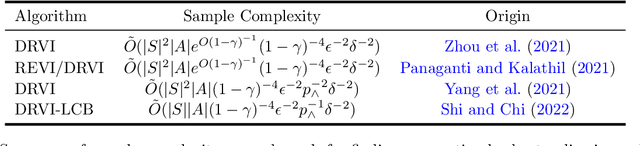
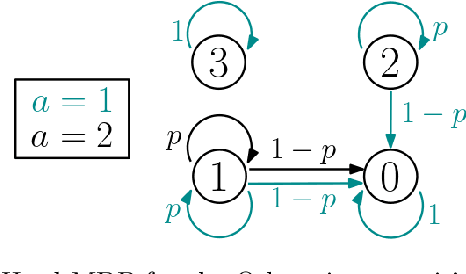

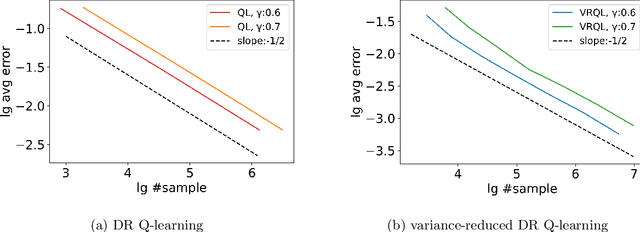
Dynamic decision making under distributional shifts is of fundamental interest in theory and applications of reinforcement learning: The distribution of the environment on which the data is collected can differ from that of the environment on which the model is deployed. This paper presents two novel model-free algorithms, namely the distributionally robust Q-learning and its variance-reduced counterpart, that can effectively learn a robust policy despite distributional shifts. These algorithms are designed to efficiently approximate the $q$-function of an infinite-horizon $\gamma$-discounted robust Markov decision process with Kullback-Leibler uncertainty set to an entry-wise $\epsilon$-degree of precision. Further, the variance-reduced distributionally robust Q-learning combines the synchronous Q-learning with variance-reduction techniques to enhance its performance. Consequently, we establish that it attains a minmax sample complexity upper bound of $\tilde O(|S||A|(1-\gamma)^{-4}\epsilon^{-2})$, where $S$ and $A$ denote the state and action spaces. This is the first complexity result that is independent of the uncertainty size $\delta$, thereby providing new complexity theoretic insights. Additionally, a series of numerical experiments confirm the theoretical findings and the efficiency of the algorithms in handling distributional shifts.
A Finite Sample Complexity Bound for Distributionally Robust Q-learning
Mar 03, 2023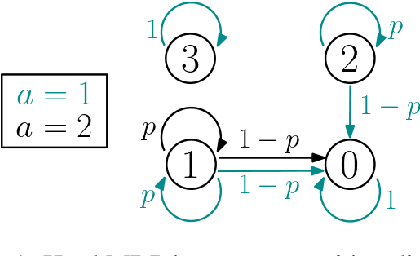

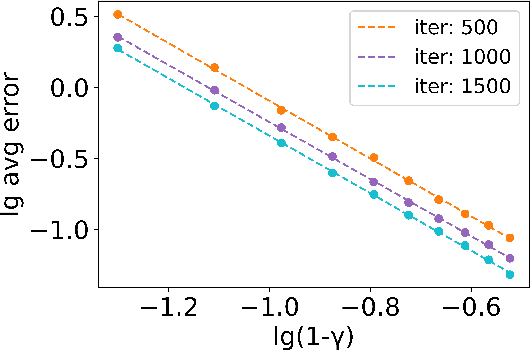
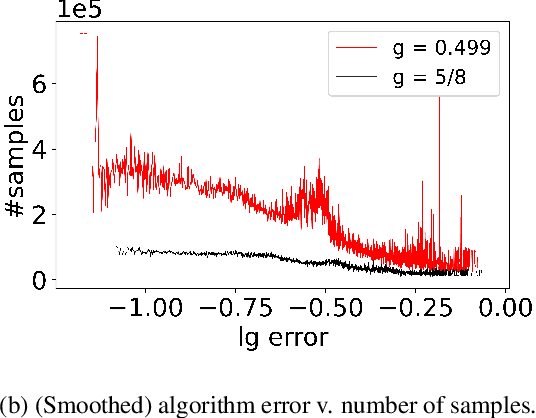
We consider a reinforcement learning setting in which the deployment environment is different from the training environment. Applying a robust Markov decision processes formulation, we extend the distributionally robust $Q$-learning framework studied in Liu et al. [2022]. Further, we improve the design and analysis of their multi-level Monte Carlo estimator. Assuming access to a simulator, we prove that the worst-case expected sample complexity of our algorithm to learn the optimal robust $Q$-function within an $\epsilon$ error in the sup norm is upper bounded by $\tilde O(|S||A|(1-\gamma)^{-5}\epsilon^{-2}p_{\wedge}^{-6}\delta^{-4})$, where $\gamma$ is the discount rate, $p_{\wedge}$ is the non-zero minimal support probability of the transition kernels and $\delta$ is the uncertainty size. This is the first sample complexity result for the model-free robust RL problem. Simulation studies further validate our theoretical results.
Optimal Sample Complexity of Reinforcement Learning for Uniformly Ergodic Discounted Markov Decision Processes
Feb 16, 2023
We consider the optimal sample complexity theory of tabular reinforcement learning (RL) for controlling the infinite horizon discounted reward in a Markov decision process (MDP). Optimal min-max complexity results have been developed for tabular RL in this setting, leading to a sample complexity dependence on $\gamma$ and $\epsilon$ of the form $\tilde \Theta((1-\gamma)^{-3}\epsilon^{-2})$, where $\gamma$ is the discount factor and $\epsilon$ is the tolerance solution error. However, in many applications of interest, the optimal policy (or all policies) will induce mixing. We show that in these settings the optimal min-max complexity is $\tilde \Theta(t_{\text{minorize}}(1-\gamma)^{-2}\epsilon^{-2})$, where $t_{\text{minorize}}$ is a measure of mixing that is within an equivalent factor of the total variation mixing time. Our analysis is based on regeneration-type ideas, that, we believe are of independent interest since they can be used to study related problems for general state space MDPs.
AutoGMap: Learning to Map Large-scale Sparse Graphs on Memristive Crossbars
Nov 15, 2021
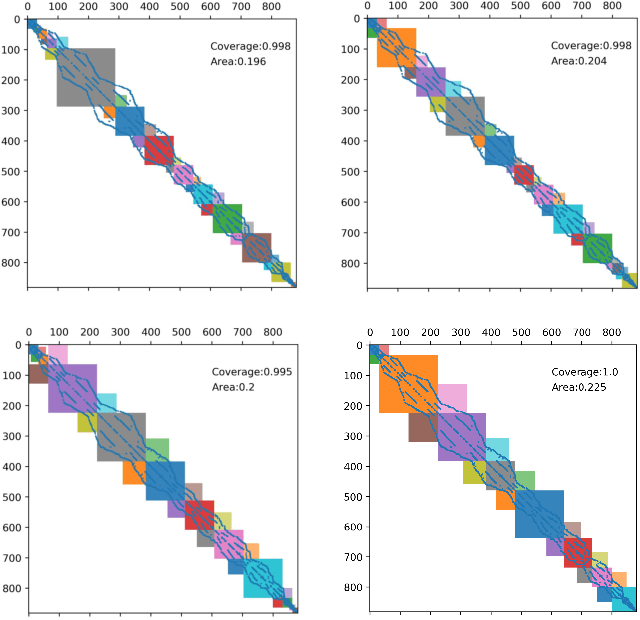
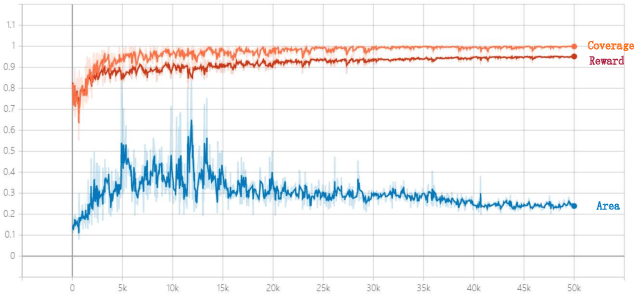

The sparse representation of graphs has shown its great potential for accelerating the computation of the graph applications (e.g. Social Networks, Knowledge Graphs) on traditional computing architectures (CPU, GPU, or TPU). But the exploration of the large-scale sparse graph computing on processing-in-memory (PIM) platforms (typically with memristive crossbars) is still in its infancy. As we look to implement the computation or storage of large-scale or batch graphs on memristive crossbars, a natural assumption would be that we need a large-scale crossbar, but with low utilization. Some recent works have questioned this assumption to avoid the waste of the storage and computational resource by "block partition", which is fixed-size, progressively scheduled, or coarse-grained, thus is not effectively sparsity-aware in our view. This work proposes the dynamic sparsity-aware mapping scheme generating method that models the problem as a sequential decision-making problem which is solved by reinforcement learning (RL) algorithm (REINFORCE). Our generating model (LSTM, combined with our dynamic-fill mechanism) generates remarkable mapping performance on a small-scale typical graph/matrix data (43% area of the original matrix with fully mapping), and two large-scale matrix data (22.5% area on qh882, and 17.1% area on qh1484). Moreover, our coding framework of the scheme is intuitive and has promising adaptability with the deployment or compilation system.