 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHan-Wei Shen
Improving Efficiency of Iso-Surface Extraction on Implicit Neural Representations Using Uncertainty Propagation
Feb 21, 2024
Implicit Neural representations (INRs) are widely used for scientific data reduction and visualization by modeling the function that maps a spatial location to a data value. Without any prior knowledge about the spatial distribution of values, we are forced to sample densely from INRs to perform visualization tasks like iso-surface extraction which can be very computationally expensive. Recently, range analysis has shown promising results in improving the efficiency of geometric queries, such as ray casting and hierarchical mesh extraction, on INRs for 3D geometries by using arithmetic rules to bound the output range of the network within a spatial region. However, the analysis bounds are often too conservative for complex scientific data. In this paper, we present an improved technique for range analysis by revisiting the arithmetic rules and analyzing the probability distribution of the network output within a spatial region. We model this distribution efficiently as a Gaussian distribution by applying the central limit theorem. Excluding low probability values, we are able to tighten the output bounds, resulting in a more accurate estimation of the value range, and hence more accurate identification of iso-surface cells and more efficient iso-surface extraction on INRs. Our approach demonstrates superior performance in terms of the iso-surface extraction time on four datasets compared to the original range analysis method and can also be generalized to other geometric query tasks.
PSRFlow: Probabilistic Super Resolution with Flow-Based Models for Scientific Data
Aug 08, 2023



Although many deep-learning-based super-resolution approaches have been proposed in recent years, because no ground truth is available in the inference stage, few can quantify the errors and uncertainties of the super-resolved results. For scientific visualization applications, however, conveying uncertainties of the results to scientists is crucial to avoid generating misleading or incorrect information. In this paper, we propose PSRFlow, a novel normalizing flow-based generative model for scientific data super-resolution that incorporates uncertainty quantification into the super-resolution process. PSRFlow learns the conditional distribution of the high-resolution data based on the low-resolution counterpart. By sampling from a Gaussian latent space that captures the missing information in the high-resolution data, one can generate different plausible super-resolution outputs. The efficient sampling in the Gaussian latent space allows our model to perform uncertainty quantification for the super-resolved results. During model training, we augment the training data with samples across various scales to make the model adaptable to data of different scales, achieving flexible super-resolution for a given input. Our results demonstrate superior performance and robust uncertainty quantification compared with existing methods such as interpolation and GAN-based super-resolution networks.
Adaptively Placed Multi-Grid Scene Representation Networks for Large-Scale Data Visualization
Jul 16, 2023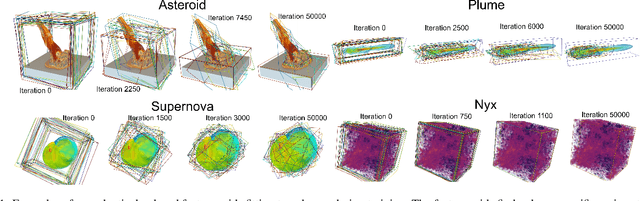



Scene representation networks (SRNs) have been recently proposed for compression and visualization of scientific data. However, state-of-the-art SRNs do not adapt the allocation of available network parameters to the complex features found in scientific data, leading to a loss in reconstruction quality. We address this shortcoming with an adaptively placed multi-grid SRN (APMGSRN) and propose a domain decomposition training and inference technique for accelerated parallel training on multi-GPU systems. We also release an open-source neural volume rendering application that allows plug-and-play rendering with any PyTorch-based SRN. Our proposed APMGSRN architecture uses multiple spatially adaptive feature grids that learn where to be placed within the domain to dynamically allocate more neural network resources where error is high in the volume, improving state-of-the-art reconstruction accuracy of SRNs for scientific data without requiring expensive octree refining, pruning, and traversal like previous adaptive models. In our domain decomposition approach for representing large-scale data, we train an set of APMGSRNs in parallel on separate bricks of the volume to reduce training time while avoiding overhead necessary for an out-of-core solution for volumes too large to fit in GPU memory. After training, the lightweight SRNs are used for realtime neural volume rendering in our open-source renderer, where arbitrary view angles and transfer functions can be explored. A copy of this paper, all code, all models used in our experiments, and all supplemental materials and videos are available at https://github.com/skywolf829/APMGSRN.
Neural Stream Functions
Jul 16, 2023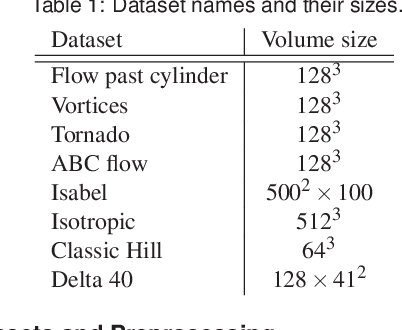

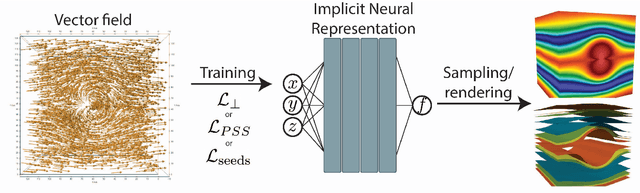

We present a neural network approach to compute stream functions, which are scalar functions with gradients orthogonal to a given vector field. As a result, isosurfaces of the stream function extract stream surfaces, which can be visualized to analyze flow features. Our approach takes a vector field as input and trains an implicit neural representation to learn a stream function for that vector field. The network learns to map input coordinates to a stream function value by minimizing the inner product of the gradient of the neural network's output and the vector field. Since stream function solutions may not be unique, we give optional constraints for the network to learn particular stream functions of interest. Specifically, we introduce regularizing loss functions that can optionally be used to generate stream function solutions whose stream surfaces follow the flow field's curvature, or that can learn a stream function that includes a stream surface passing through a seeding rake. We also discuss considerations for properly visualizing the trained implicit network and extracting artifact-free surfaces. We compare our results with other implicit solutions and present qualitative and quantitative results for several synthetic and simulated vector fields.
SKG: A Versatile Information Retrieval and Analysis Framework for Academic Papers with Semantic Knowledge Graphs
Jun 07, 2023



The number of published research papers has experienced exponential growth in recent years, which makes it crucial to develop new methods for efficient and versatile information extraction and knowledge discovery. To address this need, we propose a Semantic Knowledge Graph (SKG) that integrates semantic concepts from abstracts and other meta-information to represent the corpus. The SKG can support various semantic queries in academic literature thanks to the high diversity and rich information content stored within. To extract knowledge from unstructured text, we develop a Knowledge Extraction Module that includes a semi-supervised pipeline for entity extraction and entity normalization. We also create an ontology to integrate the concepts with other meta information, enabling us to build the SKG. Furthermore, we design and develop a dataflow system that demonstrates how to conduct various semantic queries flexibly and interactively over the SKG. To demonstrate the effectiveness of our approach, we conduct the research based on the visualization literature and provide real-world use cases to show the usefulness of the SKG. The dataset and codes for this work are available at https://osf.io/aqv8p/?view_only=2c26b36e3e3941ce999df47e4616207f.
VMap: An Interactive Rectangular Space-filling Visualization for Map-like Vertex-centric Graph Exploration
May 31, 2023



We present VMap, a map-like rectangular space-filling visualization, to perform vertex-centric graph exploration. Existing visualizations have limited support for quality optimization among rectangular aspect ratios, vertex-edge intersection, and data encoding accuracy. To tackle this problem, VMap integrates three novel components: (1) a desired-aspect-ratio (DAR) rectangular partitioning algorithm, (2) a two-stage rectangle adjustment algorithm, and (3) a simulated annealing based heuristic optimizer. First, to generate a rectangular space-filling layout of an input graph, we subdivide the 2D embedding of the graph into rectangles with optimization of rectangles' aspect ratios toward a desired aspect ratio. Second, to route graph edges between rectangles without vertex-edge occlusion, we devise a two-stage algorithm to adjust a rectangular layout to insert border space between rectangles. Third, to produce and arrange rectangles by considering multiple visual criteria, we design a simulated annealing based heuristic optimization to adjust vertices' 2D embedding to support trade-offs among aspect ratio quality and the encoding accuracy of vertices' weights and adjacency. We evaluated the effectiveness of VMap on both synthetic and application datasets. The resulting rectangular layout has better aspect ratio quality on synthetic data compared with the existing method for the rectangular partitioning of 2D points. On three real-world datasets, VMap achieved better encoding accuracy and attained faster generation speed compared with existing methods on graphs' rectangular layout generation. We further illustrate the usefulness of VMap for vertex-centric graph exploration through three case studies on visualizing social networks, representing academic communities, and displaying geographic information.
GNNInterpreter: A Probabilistic Generative Model-Level Explanation for Graph Neural Networks
Sep 15, 2022



Recently, Graph Neural Networks (GNNs) have significantly advanced the performance of machine learning tasks on graphs. However, this technological breakthrough makes people wonder: how does a GNN make such decisions, and can we trust its prediction with high confidence? When it comes to some critical fields such as biomedicine, where making wrong decisions can have severe consequences, interpreting the inner working mechanisms of GNNs before applying them is crucial. In this paper, we propose a novel model-agnostic model-level explanation method for different GNNs that follow the message passing scheme, GNNInterpreter, to explain the high-level decision-making process of the GNN model. More specifically, with continuous relaxation of graphs and the reparameterization trick, GNNInterpreter learns a probabilistic generative graph distribution which produces the most representative graph for the target prediction in the eye of the GNN model. Compared with the only existing work, GNNInterpreter is more computationally efficient and more flexible in generating explanation graphs with different types of node features and edge features, without introducing another blackbox to explain the GNN and without requiring domain-specific knowledge. Additionally, the experimental studies conducted on four different datasets demonstrate that the explanation graph generated by GNNInterpreter can match the desired graph pattern when the model is ideal and reveal potential model pitfalls if there exist any.
IDLat: An Importance-Driven Latent Generation Method for Scientific Data
Aug 05, 2022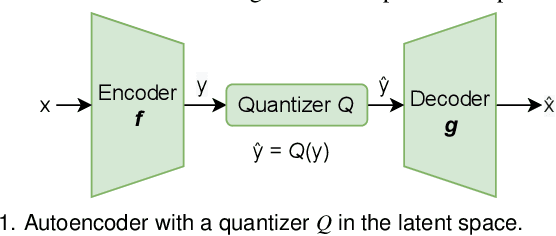
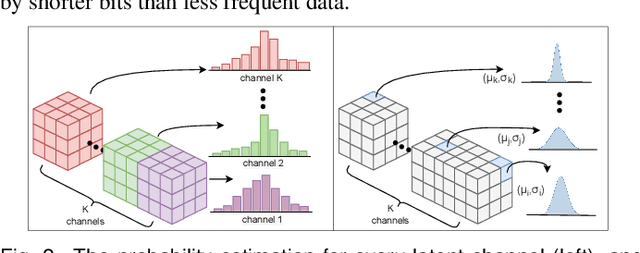


Deep learning based latent representations have been widely used for numerous scientific visualization applications such as isosurface similarity analysis, volume rendering, flow field synthesis, and data reduction, just to name a few. However, existing latent representations are mostly generated from raw data in an unsupervised manner, which makes it difficult to incorporate domain interest to control the size of the latent representations and the quality of the reconstructed data. In this paper, we present a novel importance-driven latent representation to facilitate domain-interest-guided scientific data visualization and analysis. We utilize spatial importance maps to represent various scientific interests and take them as the input to a feature transformation network to guide latent generation. We further reduced the latent size by a lossless entropy encoding algorithm trained together with the autoencoder, improving the storage and memory efficiency. We qualitatively and quantitatively evaluate the effectiveness and efficiency of latent representations generated by our method with data from multiple scientific visualization applications.
VDL-Surrogate: A View-Dependent Latent-based Model for Parameter Space Exploration of Ensemble Simulations
Jul 29, 2022
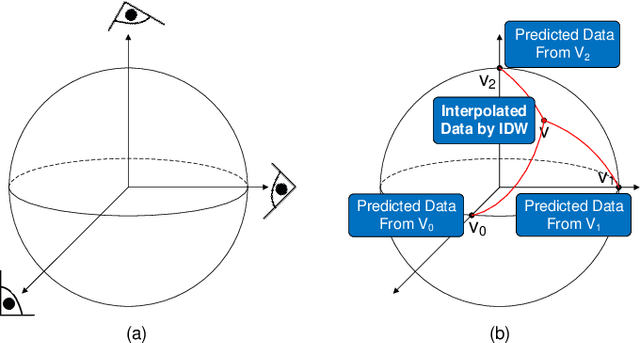


We propose VDL-Surrogate, a view-dependent neural-network-latent-based surrogate model for parameter space exploration of ensemble simulations that allows high-resolution visualizations and user-specified visual mappings. Surrogate-enabled parameter space exploration allows domain scientists to preview simulation results without having to run a large number of computationally costly simulations. Limited by computational resources, however, existing surrogate models may not produce previews with sufficient resolution for visualization and analysis. To improve the efficient use of computational resources and support high-resolution exploration, we perform ray casting from different viewpoints to collect samples and produce compact latent representations. This latent encoding process reduces the cost of surrogate model training while maintaining the output quality. In the model training stage, we select viewpoints to cover the whole viewing sphere and train corresponding VDL-Surrogate models for the selected viewpoints. In the model inference stage, we predict the latent representations at previously selected viewpoints and decode the latent representations to data space. For any given viewpoint, we make interpolations over decoded data at selected viewpoints and generate visualizations with user-specified visual mappings. We show the effectiveness and efficiency of VDL-Surrogate in cosmological and ocean simulations with quantitative and qualitative evaluations. Source code is publicly available at https://github.com/trainsn/VDL-Surrogate.
On Pre-Training for Federated Learning
Jun 23, 2022



In most of the literature on federated learning (FL), neural networks are initialized with random weights. In this paper, we present an empirical study on the effect of pre-training on FL. Specifically, we aim to investigate if pre-training can alleviate the drastic accuracy drop when clients' decentralized data are non-IID. We focus on FedAvg, the fundamental and most widely used FL algorithm. We found that pre-training does largely close the gap between FedAvg and centralized learning under non-IID data, but this does not come from alleviating the well-known model drifting problem in FedAvg's local training. Instead, how pre-training helps FedAvg is by making FedAvg's global aggregation more stable. When pre-training using real data is not feasible for FL, we propose a novel approach to pre-train with synthetic data. On various image datasets (including one for segmentation), our approach with synthetic pre-training leads to a notable gain, essentially a critical step toward scaling up federated learning for real-world applications.