 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHaoyu Li
TDT-KWS: Fast And Accurate Keyword Spotting Using Token-and-duration Transducer
Mar 20, 2024
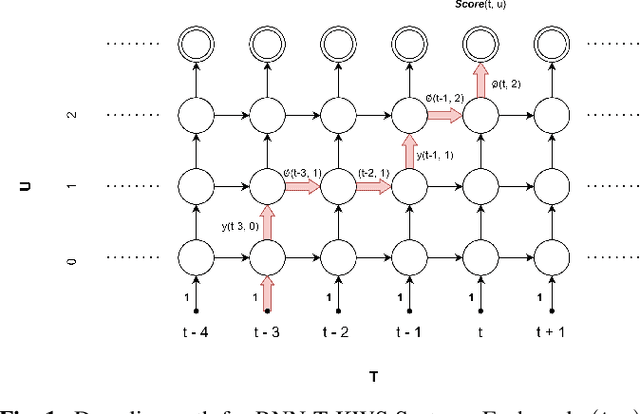

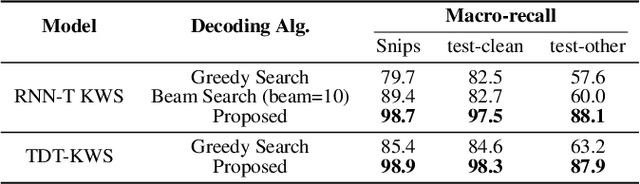
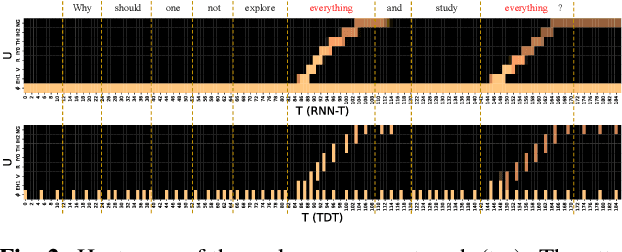
Designing an efficient keyword spotting (KWS) system that delivers exceptional performance on resource-constrained edge devices has long been a subject of significant attention. Existing KWS search algorithms typically follow a frame-synchronous approach, where search decisions are made repeatedly at each frame despite the fact that most frames are keyword-irrelevant. In this paper, we propose TDT-KWS, which leverages token-and-duration Transducers (TDT) for KWS tasks. We also propose a novel KWS task-specific decoding algorithm for Transducer-based models, which supports highly effective frame-asynchronous keyword search in streaming speech scenarios. With evaluations conducted on both the public Hey Snips and self-constructed LibriKWS-20 datasets, our proposed KWS-decoding algorithm produces more accurate results than conventional ASR decoding algorithms. Additionally, TDT-KWS achieves on-par or better wake word detection performance than both RNN-T and traditional TDT-ASR systems while achieving significant inference speed-up. Furthermore, experiments show that TDT-KWS is more robust to noisy environments compared to RNN-T KWS.
NeuralDiffuser: Controllable fMRI Reconstruction with Primary Visual Feature Guided Diffusion
Mar 02, 2024Reconstructing visual stimuli from functional Magnetic Resonance Imaging (fMRI) based on Latent Diffusion Models (LDM) provides a fine-grained retrieval of the brain. A challenge persists in reconstructing a cohesive alignment of details (such as structure, background, texture, color, etc.). Moreover, LDMs would generate different image results even under the same conditions. For these, we first uncover the neuroscientific perspective of LDM-based methods that is top-down creation based on pre-trained knowledge from massive images but lack of detail-driven bottom-up perception resulting in unfaithful details. We propose NeuralDiffuser which introduces primary visual feature guidance to provide detail cues in the form of gradients, extending the bottom-up process for LDM-based methods to achieve faithful semantics and details. We also developed a novel guidance strategy to ensure the consistency of repeated reconstructions rather than a variety of results. We obtain the state-of-the-art performance of NeuralDiffuser on the Natural Senses Dataset (NSD), which offers more faithful details and consistent results.
Improving Efficiency of Iso-Surface Extraction on Implicit Neural Representations Using Uncertainty Propagation
Feb 21, 2024Implicit Neural representations (INRs) are widely used for scientific data reduction and visualization by modeling the function that maps a spatial location to a data value. Without any prior knowledge about the spatial distribution of values, we are forced to sample densely from INRs to perform visualization tasks like iso-surface extraction which can be very computationally expensive. Recently, range analysis has shown promising results in improving the efficiency of geometric queries, such as ray casting and hierarchical mesh extraction, on INRs for 3D geometries by using arithmetic rules to bound the output range of the network within a spatial region. However, the analysis bounds are often too conservative for complex scientific data. In this paper, we present an improved technique for range analysis by revisiting the arithmetic rules and analyzing the probability distribution of the network output within a spatial region. We model this distribution efficiently as a Gaussian distribution by applying the central limit theorem. Excluding low probability values, we are able to tighten the output bounds, resulting in a more accurate estimation of the value range, and hence more accurate identification of iso-surface cells and more efficient iso-surface extraction on INRs. Our approach demonstrates superior performance in terms of the iso-surface extraction time on four datasets compared to the original range analysis method and can also be generalized to other geometric query tasks.
Accelerating Distributed Deep Learning using Lossless Homomorphic Compression
Feb 12, 2024As deep neural networks (DNNs) grow in complexity and size, the resultant increase in communication overhead during distributed training has become a significant bottleneck, challenging the scalability of distributed training systems. Existing solutions, while aiming to mitigate this bottleneck through worker-level compression and in-network aggregation, fall short due to their inability to efficiently reconcile the trade-offs between compression effectiveness and computational overhead, hindering overall performance and scalability. In this paper, we introduce a novel compression algorithm that effectively merges worker-level compression with in-network aggregation. Our solution is both homomorphic, allowing for efficient in-network aggregation without CPU/GPU processing, and lossless, ensuring no compromise on training accuracy. Theoretically optimal in compression and computational efficiency, our approach is empirically validated across diverse DNN models such as NCF, LSTM, VGG19, and BERT-base, showing up to a 6.33$\times$ improvement in aggregation throughput and a 3.74$\times$ increase in per-iteration training speed.
The Future of Cognitive Strategy-enhanced Persuasive Dialogue Agents: New Perspectives and Trends
Feb 07, 2024Persuasion, as one of the crucial abilities in human communication, has garnered extensive attention from researchers within the field of intelligent dialogue systems. We humans tend to persuade others to change their viewpoints, attitudes or behaviors through conversations in various scenarios (e.g., persuasion for social good, arguing in online platforms). Developing dialogue agents that can persuade others to accept certain standpoints is essential to achieving truly intelligent and anthropomorphic dialogue system. Benefiting from the substantial progress of Large Language Models (LLMs), dialogue agents have acquired an exceptional capability in context understanding and response generation. However, as a typical and complicated cognitive psychological system, persuasive dialogue agents also require knowledge from the domain of cognitive psychology to attain a level of human-like persuasion. Consequently, the cognitive strategy-enhanced persuasive dialogue agent (defined as CogAgent), which incorporates cognitive strategies to achieve persuasive targets through conversation, has become a predominant research paradigm. To depict the research trends of CogAgent, in this paper, we first present several fundamental cognitive psychology theories and give the formalized definition of three typical cognitive strategies, including the persuasion strategy, the topic path planning strategy, and the argument structure prediction strategy. Then we propose a new system architecture by incorporating the formalized definition to lay the foundation of CogAgent. Representative works are detailed and investigated according to the combined cognitive strategy, followed by the summary of authoritative benchmarks and evaluation metrics. Finally, we summarize our insights on open issues and future directions of CogAgent for upcoming researchers.
Data Attribution for Diffusion Models: Timestep-induced Bias in Influence Estimation
Jan 21, 2024Data attribution methods trace model behavior back to its training dataset, offering an effective approach to better understand ''black-box'' neural networks. While prior research has established quantifiable links between model output and training data in diverse settings, interpreting diffusion model outputs in relation to training samples remains underexplored. In particular, diffusion models operate over a sequence of timesteps instead of instantaneous input-output relationships in previous contexts, posing a significant challenge to extend existing frameworks to diffusion models directly. Notably, we present Diffusion-TracIn that incorporates this temporal dynamics and observe that samples' loss gradient norms are highly dependent on timestep. This trend leads to a prominent bias in influence estimation, and is particularly noticeable for samples trained on large-norm-inducing timesteps, causing them to be generally influential. To mitigate this effect, we introduce Diffusion-ReTrac as a re-normalized adaptation that enables the retrieval of training samples more targeted to the test sample of interest, facilitating a localized measurement of influence and considerably more intuitive visualization. We demonstrate the efficacy of our approach through various evaluation metrics and auxiliary tasks, reducing the amount of generally influential samples to $\frac{1}{3}$ of its original quantity.
Hybrid HMM Decoder For Convolutional Codes By Joint Trellis-Like Structure and Channel Prior
Nov 12, 2022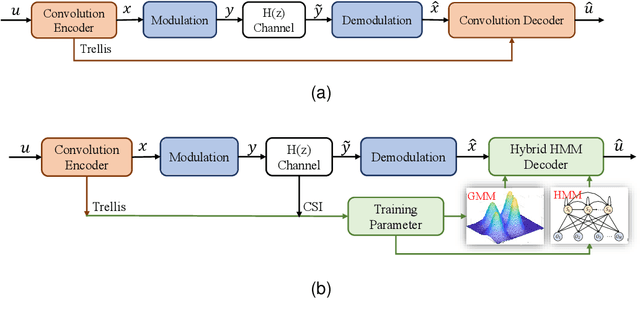
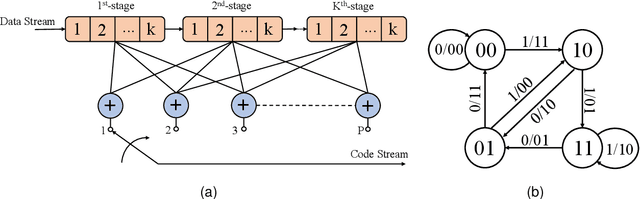
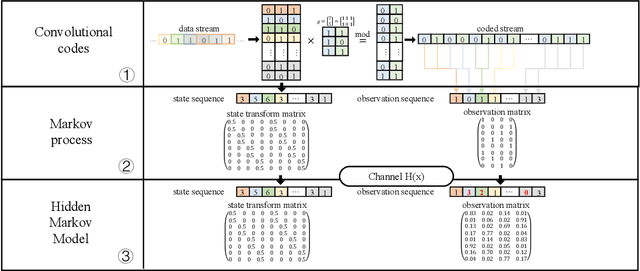
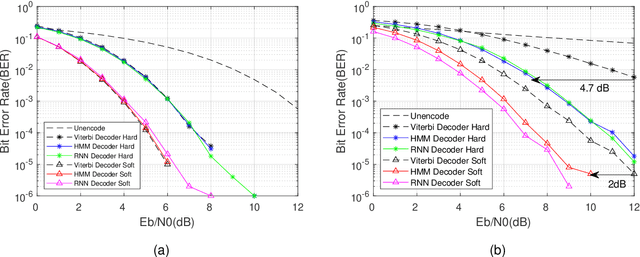
The anti-interference capability of wireless links is a physical layer problem for edge computing. Although convolutional codes have inherent error correction potential due to the redundancy introduced in the data, the performance of the convolutional code is drastically degraded due to multipath effects on the channel. In this paper, we propose the use of a Hidden Markov Model (HMM) for the reconstruction of convolutional codes and decoding by the Viterbi algorithm. Furthermore, to implement soft-decision decoding, the observation of HMM is replaced by Gaussian mixture models (GMM). Our method provides superior error correction potential than the standard method because the model parameters contain channel state information (CSI). We evaluated the performance of the method compared to standard Viterbi decoding by numerical simulation. In the multipath channel, the hybrid HMM decoder can achieve a performance gain of 4.7 dB and 2 dB when using hard-decision and soft-decision decoding, respectively. The HMM decoder also achieves significant performance gains for the RSC code, suggesting that the method could be extended to turbo codes.
* 12 pages, 8 figures
IDLat: An Importance-Driven Latent Generation Method for Scientific Data
Aug 05, 2022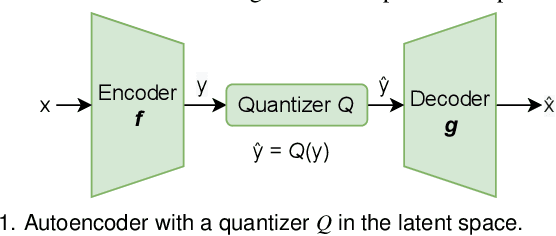
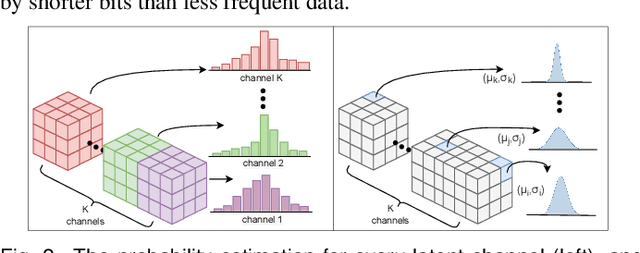


Deep learning based latent representations have been widely used for numerous scientific visualization applications such as isosurface similarity analysis, volume rendering, flow field synthesis, and data reduction, just to name a few. However, existing latent representations are mostly generated from raw data in an unsupervised manner, which makes it difficult to incorporate domain interest to control the size of the latent representations and the quality of the reconstructed data. In this paper, we present a novel importance-driven latent representation to facilitate domain-interest-guided scientific data visualization and analysis. We utilize spatial importance maps to represent various scientific interests and take them as the input to a feature transformation network to guide latent generation. We further reduced the latent size by a lossless entropy encoding algorithm trained together with the autoencoder, improving the storage and memory efficiency. We qualitatively and quantitatively evaluate the effectiveness and efficiency of latent representations generated by our method with data from multiple scientific visualization applications.
VDL-Surrogate: A View-Dependent Latent-based Model for Parameter Space Exploration of Ensemble Simulations
Jul 29, 2022
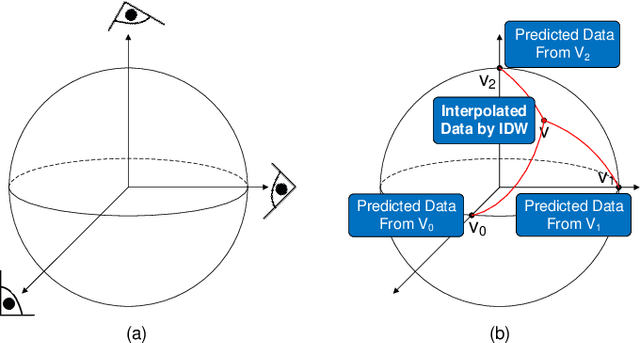


We propose VDL-Surrogate, a view-dependent neural-network-latent-based surrogate model for parameter space exploration of ensemble simulations that allows high-resolution visualizations and user-specified visual mappings. Surrogate-enabled parameter space exploration allows domain scientists to preview simulation results without having to run a large number of computationally costly simulations. Limited by computational resources, however, existing surrogate models may not produce previews with sufficient resolution for visualization and analysis. To improve the efficient use of computational resources and support high-resolution exploration, we perform ray casting from different viewpoints to collect samples and produce compact latent representations. This latent encoding process reduces the cost of surrogate model training while maintaining the output quality. In the model training stage, we select viewpoints to cover the whole viewing sphere and train corresponding VDL-Surrogate models for the selected viewpoints. In the model inference stage, we predict the latent representations at previously selected viewpoints and decode the latent representations to data space. For any given viewpoint, we make interpolations over decoded data at selected viewpoints and generate visualizations with user-specified visual mappings. We show the effectiveness and efficiency of VDL-Surrogate in cosmological and ocean simulations with quantitative and qualitative evaluations. Source code is publicly available at https://github.com/trainsn/VDL-Surrogate.
Joint Noise Reduction and Listening Enhancement for Full-End Speech Enhancement
Mar 22, 2022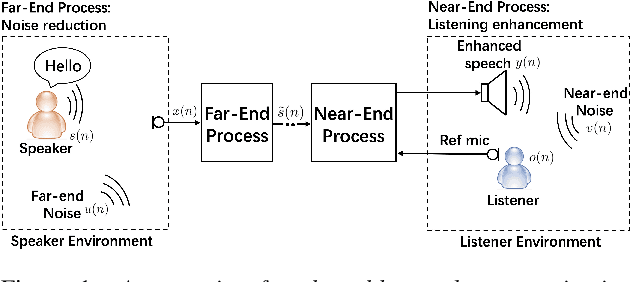
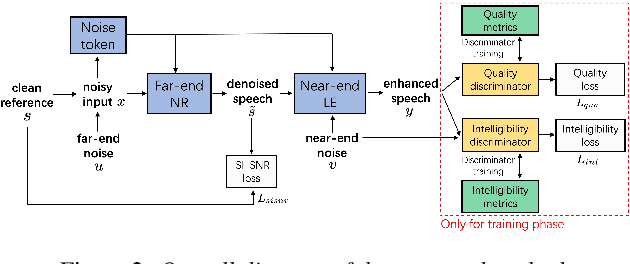
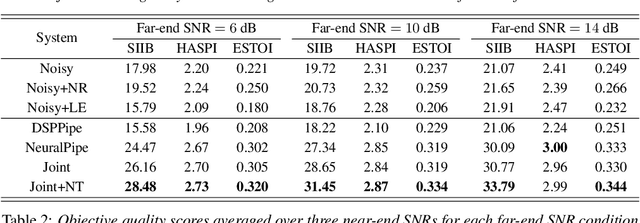

Speech enhancement (SE) methods mainly focus on recovering clean speech from noisy input. In real-world speech communication, however, noises often exist in not only speaker but also listener environments. Although SE methods can suppress the noise contained in the speaker's voice, they cannot deal with the noise that is physically present in the listener side. To address such a complicated but common scenario, we investigate a deep learning-based joint framework integrating noise reduction (NR) with listening enhancement (LE), in which the NR module first suppresses noise and the LE module then modifies the denoised speech, i.e., the output of the NR module, to further improve speech intelligibility. The enhanced speech can thus be less noisy and more intelligible for listeners. Experimental results show that our proposed method achieves promising results and significantly outperforms the disjoint processing methods in terms of various speech evaluation metrics.