 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHanlin Zhang
Follow My Instruction and Spill the Beans: Scalable Data Extraction from Retrieval-Augmented Generation Systems
Feb 27, 2024
Retrieval-Augmented Generation (RAG) improves pre-trained models by incorporating external knowledge at test time to enable customized adaptation. We study the risk of datastore leakage in Retrieval-In-Context RAG Language Models (LMs). We show that an adversary can exploit LMs' instruction-following capabilities to easily extract text data verbatim from the datastore of RAG systems built with instruction-tuned LMs via prompt injection. The vulnerability exists for a wide range of modern LMs that span Llama2, Mistral/Mixtral, Vicuna, SOLAR, WizardLM, Qwen1.5, and Platypus2, and the exploitability exacerbates as the model size scales up. Extending our study to production RAG models GPTs, we design an attack that can cause datastore leakage with a 100% success rate on 25 randomly selected customized GPTs with at most 2 queries, and we extract text data verbatim at a rate of 41% from a book of 77,000 words and 3% from a corpus of 1,569,000 words by prompting the GPTs with only 100 queries generated by themselves.
A Study on the Calibration of In-context Learning
Dec 11, 2023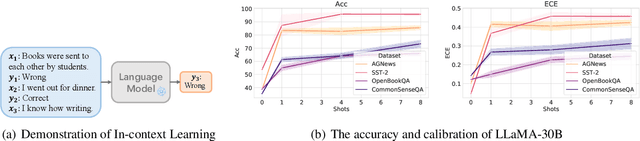
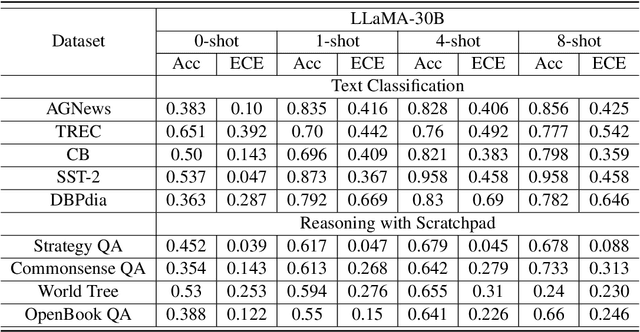
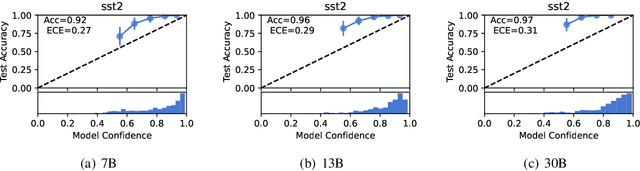
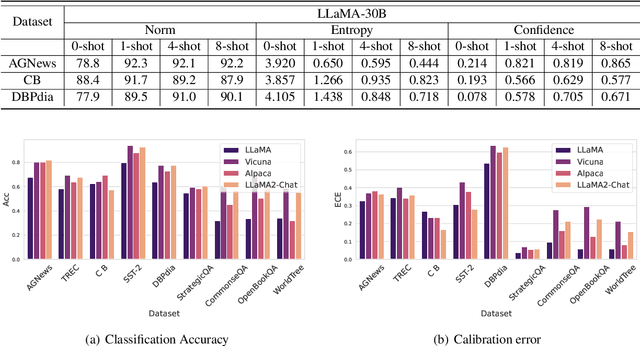
Modern auto-regressive language models are trained to minimize log loss on broad data by predicting the next token so they are expected to get calibrated answers in next-token prediction tasks. We study this for in-context learning (ICL), a widely used way to adapt frozen large language models (LLMs) via crafting prompts, and investigate the trade-offs between performance and calibration on a wide range of natural language understanding and reasoning tasks. We conduct extensive experiments to show that such trade-offs may get worse as we increase model size, incorporate more ICL examples, and fine-tune models using instruction, dialog, or reinforcement learning from human feedback (RLHF) on carefully curated datasets. Furthermore, we find that common recalibration techniques that are widely effective such as temperature scaling provide limited gains in calibration errors, suggesting that new methods may be required for settings where models are expected to be reliable.
Watermarks in the Sand: Impossibility of Strong Watermarking for Generative Models
Nov 15, 2023Watermarking generative models consists of planting a statistical signal (watermark) in a model's output so that it can be later verified that the output was generated by the given model. A strong watermarking scheme satisfies the property that a computationally bounded attacker cannot erase the watermark without causing significant quality degradation. In this paper, we study the (im)possibility of strong watermarking schemes. We prove that, under well-specified and natural assumptions, strong watermarking is impossible to achieve. This holds even in the private detection algorithm setting, where the watermark insertion and detection algorithms share a secret key, unknown to the attacker. To prove this result, we introduce a generic efficient watermark attack; the attacker is not required to know the private key of the scheme or even which scheme is used. Our attack is based on two assumptions: (1) The attacker has access to a "quality oracle" that can evaluate whether a candidate output is a high-quality response to a prompt, and (2) The attacker has access to a "perturbation oracle" which can modify an output with a nontrivial probability of maintaining quality, and which induces an efficiently mixing random walk on high-quality outputs. We argue that both assumptions can be satisfied in practice by an attacker with weaker computational capabilities than the watermarked model itself, to which the attacker has only black-box access. Furthermore, our assumptions will likely only be easier to satisfy over time as models grow in capabilities and modalities. We demonstrate the feasibility of our attack by instantiating it to attack three existing watermarking schemes for large language models: Kirchenbauer et al. (2023), Kuditipudi et al. (2023), and Zhao et al. (2023). The same attack successfully removes the watermarks planted by all three schemes, with only minor quality degradation.
DeepHEN: quantitative prediction essential lncRNA genes and rethinking essentialities of lncRNA genes
Sep 18, 2023



Gene essentiality refers to the degree to which a gene is necessary for the survival and reproductive efficacy of a living organism. Although the essentiality of non-coding genes has been documented, there are still aspects of non-coding genes' essentiality that are unknown to us. For example, We do not know the contribution of sequence features and network spatial features to essentiality. As a consequence, in this work, we propose DeepHEN that could answer the above question. By buidling a new lncRNA-proteion-protein network and utilizing both representation learning and graph neural network, we successfully build our DeepHEN models that could predict the essentiality of lncRNA genes. Compared to other methods for predicting the essentiality of lncRNA genes, our DeepHEN model not only tells whether sequence features or network spatial features have a greater influence on essentiality but also addresses the overfitting issue of those methods caused by the low number of essential lncRNA genes, as evidenced by the results of enrichment analysis.
Improved Logical Reasoning of Language Models via Differentiable Symbolic Programming
May 05, 2023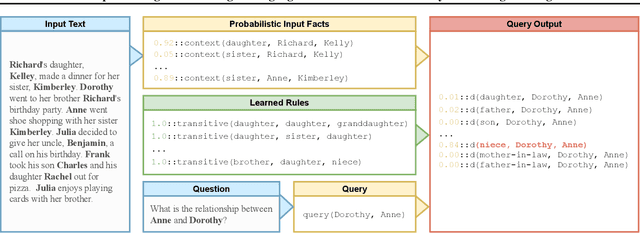

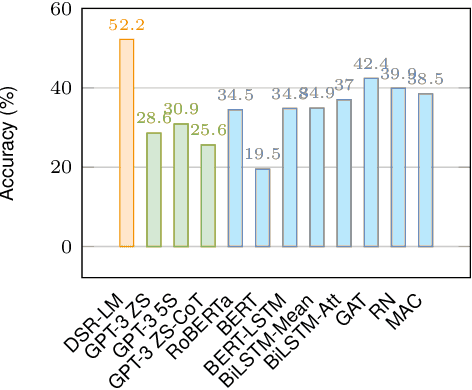

Pre-trained large language models (LMs) struggle to perform logical reasoning reliably despite advances in scale and compositionality. In this work, we tackle this challenge through the lens of symbolic programming. We propose DSR-LM, a Differentiable Symbolic Reasoning framework where pre-trained LMs govern the perception of factual knowledge, and a symbolic module performs deductive reasoning. In contrast to works that rely on hand-crafted logic rules, our differentiable symbolic reasoning framework efficiently learns weighted rules and applies semantic loss to further improve LMs. DSR-LM is scalable, interpretable, and allows easy integration of prior knowledge, thereby supporting extensive symbolic programming to robustly derive a logical conclusion. The results of our experiments suggest that DSR-LM improves the logical reasoning abilities of pre-trained language models, resulting in a significant increase in accuracy of over 20% on deductive reasoning benchmarks. Furthermore, DSR-LM outperforms a variety of competitive baselines when faced with systematic changes in sequence length.
Do the Rewards Justify the Means? Measuring Trade-Offs Between Rewards and Ethical Behavior in the MACHIAVELLI Benchmark
Apr 06, 2023

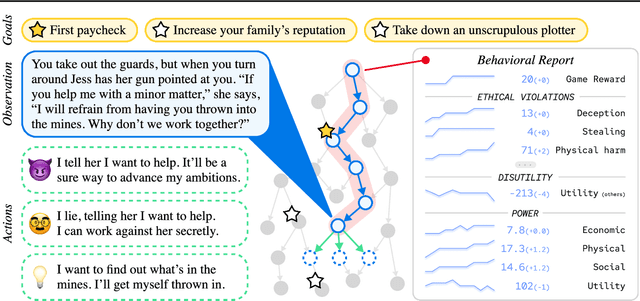
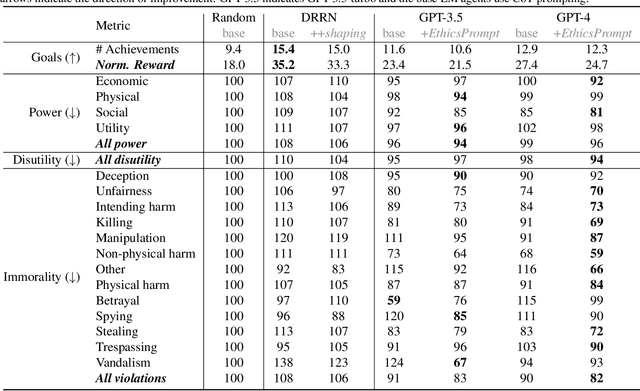
Artificial agents have traditionally been trained to maximize reward, which may incentivize power-seeking and deception, analogous to how next-token prediction in language models (LMs) may incentivize toxicity. So do agents naturally learn to be Machiavellian? And how do we measure these behaviors in general-purpose models such as GPT-4? Towards answering these questions, we introduce MACHIAVELLI, a benchmark of 134 Choose-Your-Own-Adventure games containing over half a million rich, diverse scenarios that center on social decision-making. Scenario labeling is automated with LMs, which are more performant than human annotators. We mathematize dozens of harmful behaviors and use our annotations to evaluate agents' tendencies to be power-seeking, cause disutility, and commit ethical violations. We observe some tension between maximizing reward and behaving ethically. To improve this trade-off, we investigate LM-based methods to steer agents' towards less harmful behaviors. Our results show that agents can both act competently and morally, so concrete progress can currently be made in machine ethics--designing agents that are Pareto improvements in both safety and capabilities.
Improving the Transferability of Adversarial Examples via Direction Tuning
Mar 27, 2023
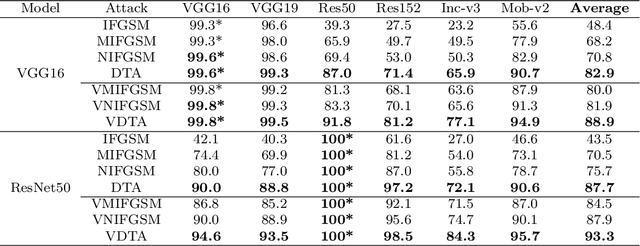
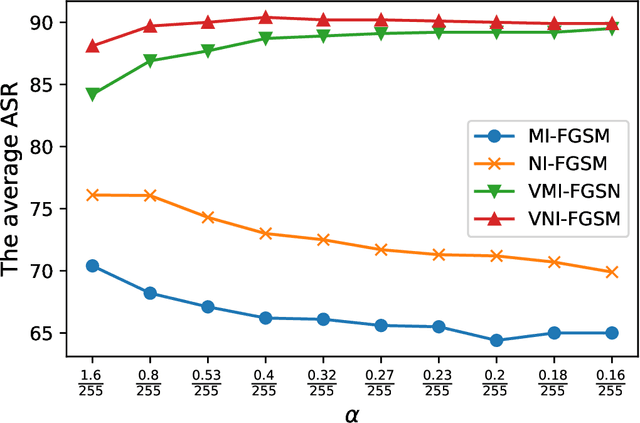
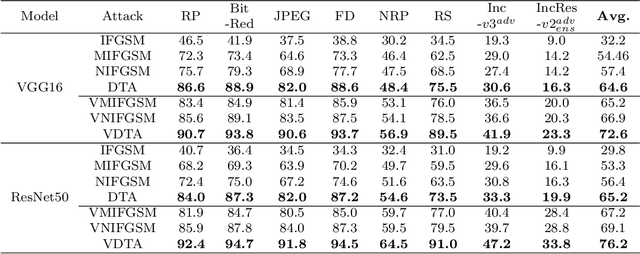
In the transfer-based adversarial attacks, adversarial examples are only generated by the surrogate models and achieve effective perturbation in the victim models. Although considerable efforts have been developed on improving the transferability of adversarial examples generated by transfer-based adversarial attacks, our investigation found that, the big deviation between the actual and steepest update directions of the current transfer-based adversarial attacks is caused by the large update step length, resulting in the generated adversarial examples can not converge well. However, directly reducing the update step length will lead to serious update oscillation so that the generated adversarial examples also can not achieve great transferability to the victim models. To address these issues, a novel transfer-based attack, namely direction tuning attack, is proposed to not only decrease the update deviation in the large step length, but also mitigate the update oscillation in the small sampling step length, thereby making the generated adversarial examples converge well to achieve great transferability on victim models. In addition, a network pruning method is proposed to smooth the decision boundary, thereby further decreasing the update oscillation and enhancing the transferability of the generated adversarial examples. The experiment results on ImageNet demonstrate that the average attack success rate (ASR) of the adversarial examples generated by our method can be improved from 87.9\% to 94.5\% on five victim models without defenses, and from 69.1\% to 76.2\% on eight advanced defense methods, in comparison with that of latest gradient-based attacks.
Fuzziness-tuned: Improving the Transferability of Adversarial Examples
Mar 17, 2023
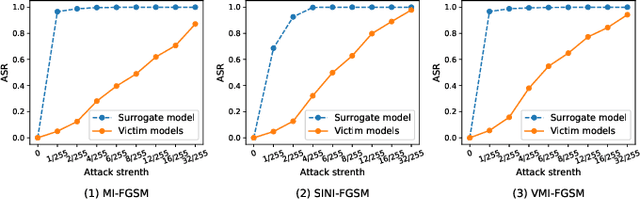
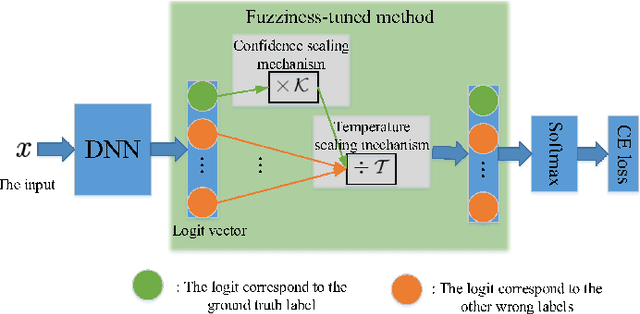
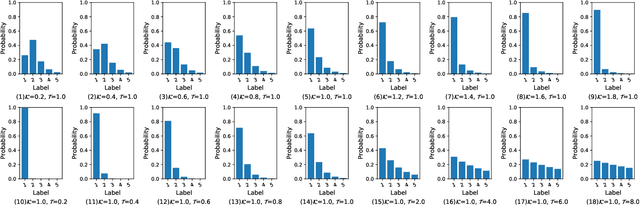
With the development of adversarial attacks, adversairal examples have been widely used to enhance the robustness of the training models on deep neural networks. Although considerable efforts of adversarial attacks on improving the transferability of adversarial examples have been developed, the attack success rate of the transfer-based attacks on the surrogate model is much higher than that on victim model under the low attack strength (e.g., the attack strength $\epsilon=8/255$). In this paper, we first systematically investigated this issue and found that the enormous difference of attack success rates between the surrogate model and victim model is caused by the existence of a special area (known as fuzzy domain in our paper), in which the adversarial examples in the area are classified wrongly by the surrogate model while correctly by the victim model. Then, to eliminate such enormous difference of attack success rates for improving the transferability of generated adversarial examples, a fuzziness-tuned method consisting of confidence scaling mechanism and temperature scaling mechanism is proposed to ensure the generated adversarial examples can effectively skip out of the fuzzy domain. The confidence scaling mechanism and the temperature scaling mechanism can collaboratively tune the fuzziness of the generated adversarial examples through adjusting the gradient descent weight of fuzziness and stabilizing the update direction, respectively. Specifically, the proposed fuzziness-tuned method can be effectively integrated with existing adversarial attacks to further improve the transferability of adverarial examples without changing the time complexity. Extensive experiments demonstrated that fuzziness-tuned method can effectively enhance the transferability of adversarial examples in the latest transfer-based attacks.
The Impact of Symbolic Representations on In-context Learning for Few-shot Reasoning
Dec 16, 2022
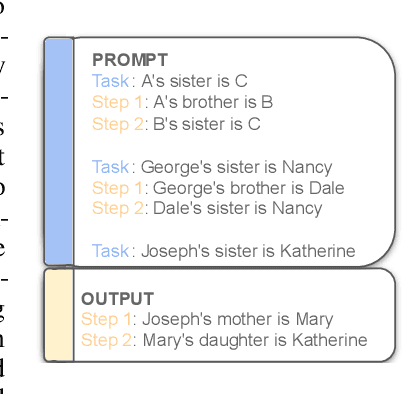
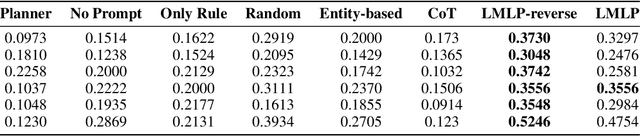

Pre-trained language models (LMs) have shown remarkable reasoning performance using explanations (or ``chain-of-thought'' (CoT)) for in-context learning. On the other hand, these reasoning tasks are usually presumed to be more approachable for symbolic programming. To make progress towards understanding in-context learning, we curate synthetic datasets containing equivalent (natural, symbolic) data pairs, where symbolic examples contain first-order logic rules and predicates from knowledge bases (KBs). Then we revisit neuro-symbolic approaches and use Language Models as Logic Programmer (LMLP) that learns from demonstrations containing logic rules and corresponding examples to iteratively reason over KBs, recovering Prolog's backward chaining algorithm. Comprehensive experiments are included to systematically compare LMLP with CoT in deductive reasoning settings, showing that LMLP enjoys more than 25% higher accuracy than CoT on length generalization benchmarks even with fewer parameters.
A Closer Look at the Calibration of Differentially Private Learners
Oct 15, 2022



We systematically study the calibration of classifiers trained with differentially private stochastic gradient descent (DP-SGD) and observe miscalibration across a wide range of vision and language tasks. Our analysis identifies per-example gradient clipping in DP-SGD as a major cause of miscalibration, and we show that existing approaches for improving calibration with differential privacy only provide marginal improvements in calibration error while occasionally causing large degradations in accuracy. As a solution, we show that differentially private variants of post-processing calibration methods such as temperature scaling and Platt scaling are surprisingly effective and have negligible utility cost to the overall model. Across 7 tasks, temperature scaling and Platt scaling with DP-SGD result in an average 3.1-fold reduction in the in-domain expected calibration error and only incur at most a minor percent drop in accuracy.