 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMayur Naik
MDB: Interactively Querying Datasets and Models
Aug 13, 2023




As models are trained and deployed, developers need to be able to systematically debug errors that emerge in the machine learning pipeline. We present MDB, a debugging framework for interactively querying datasets and models. MDB integrates functional programming with relational algebra to build expressive queries over a database of datasets and model predictions. Queries are reusable and easily modified, enabling debuggers to rapidly iterate and refine queries to discover and characterize errors and model behaviors. We evaluate MDB on object detection, bias discovery, image classification, and data imputation tasks across self-driving videos, large language models, and medical records. Our experiments show that MDB enables up to 10x faster and 40\% shorter queries than other baselines. In a user study, we find developers can successfully construct complex queries that describe errors of machine learning models.
Rectifying Group Irregularities in Explanations for Distribution Shift
May 25, 2023



It is well-known that real-world changes constituting distribution shift adversely affect model performance. How to characterize those changes in an interpretable manner is poorly understood. Existing techniques to address this problem take the form of shift explanations that elucidate how to map samples from the original distribution toward the shifted one by reducing the disparity between these two distributions. However, these methods can introduce group irregularities, leading to explanations that are less feasible and robust. To address these issues, we propose Group-aware Shift Explanations (GSE), a method that produces interpretable explanations by leveraging worst-group optimization to rectify group irregularities. We demonstrate how GSE not only maintains group structures, such as demographic and hierarchical subpopulations, but also enhances feasibility and robustness in the resulting explanations in a wide range of tabular, language, and image settings.
Improved Logical Reasoning of Language Models via Differentiable Symbolic Programming
May 05, 2023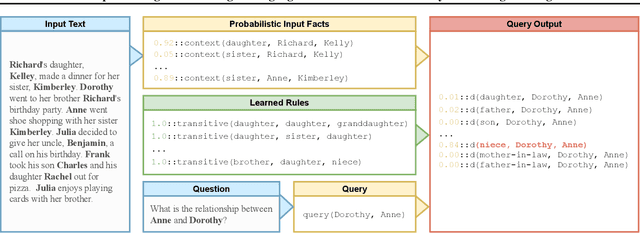

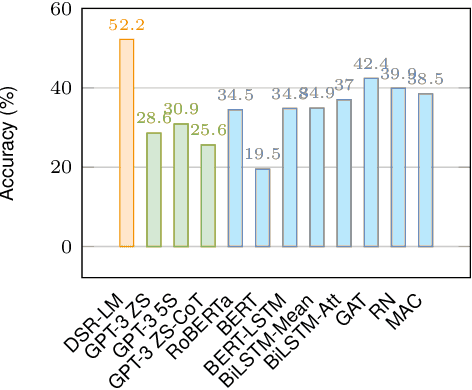

Pre-trained large language models (LMs) struggle to perform logical reasoning reliably despite advances in scale and compositionality. In this work, we tackle this challenge through the lens of symbolic programming. We propose DSR-LM, a Differentiable Symbolic Reasoning framework where pre-trained LMs govern the perception of factual knowledge, and a symbolic module performs deductive reasoning. In contrast to works that rely on hand-crafted logic rules, our differentiable symbolic reasoning framework efficiently learns weighted rules and applies semantic loss to further improve LMs. DSR-LM is scalable, interpretable, and allows easy integration of prior knowledge, thereby supporting extensive symbolic programming to robustly derive a logical conclusion. The results of our experiments suggest that DSR-LM improves the logical reasoning abilities of pre-trained language models, resulting in a significant increase in accuracy of over 20% on deductive reasoning benchmarks. Furthermore, DSR-LM outperforms a variety of competitive baselines when faced with systematic changes in sequence length.
LASER: Neuro-Symbolic Learning of Semantic Video Representations
Apr 15, 2023
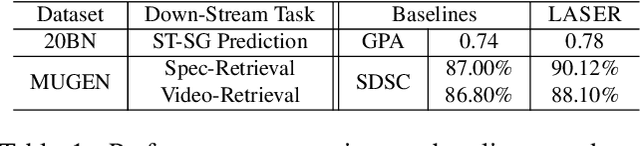
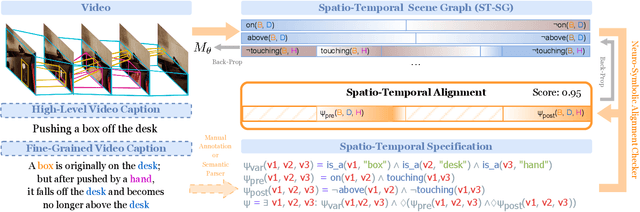
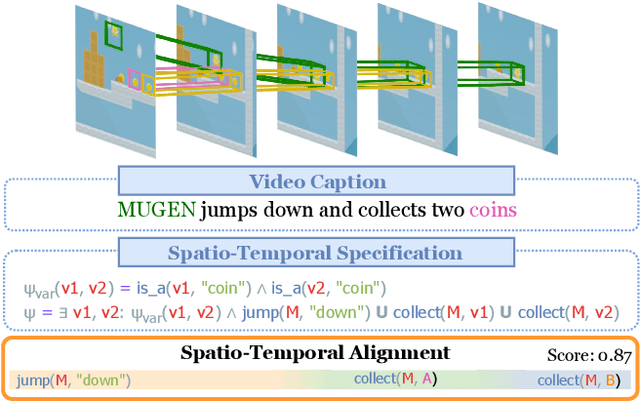
Modern AI applications involving video, such as video-text alignment, video search, and video captioning, benefit from a fine-grained understanding of video semantics. Existing approaches for video understanding are either data-hungry and need low-level annotation, or are based on general embeddings that are uninterpretable and can miss important details. We propose LASER, a neuro-symbolic approach that learns semantic video representations by leveraging logic specifications that can capture rich spatial and temporal properties in video data. In particular, we formulate the problem in terms of alignment between raw videos and specifications. The alignment process efficiently trains low-level perception models to extract a fine-grained video representation that conforms to the desired high-level specification. Our pipeline can be trained end-to-end and can incorporate contrastive and semantic loss functions derived from specifications. We evaluate our method on two datasets with rich spatial and temporal specifications: 20BN-Something-Something and MUGEN. We demonstrate that our method not only learns fine-grained video semantics but also outperforms existing baselines on downstream tasks such as video retrieval.
Scallop: A Language for Neurosymbolic Programming
Apr 10, 2023

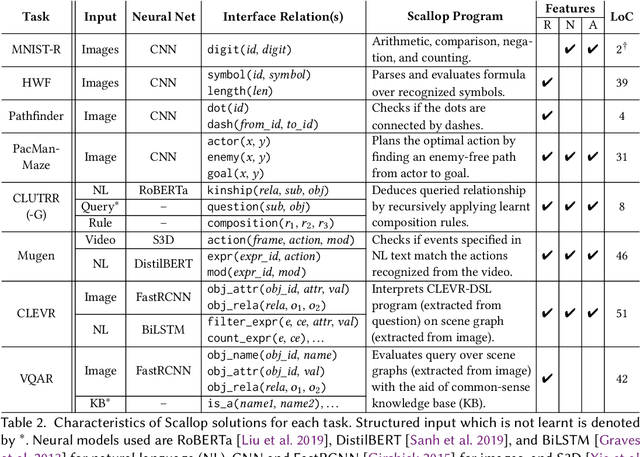
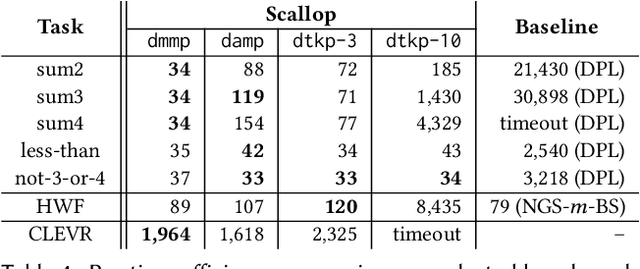
We present Scallop, a language which combines the benefits of deep learning and logical reasoning. Scallop enables users to write a wide range of neurosymbolic applications and train them in a data- and compute-efficient manner. It achieves these goals through three key features: 1) a flexible symbolic representation that is based on the relational data model; 2) a declarative logic programming language that is based on Datalog and supports recursion, aggregation, and negation; and 3) a framework for automatic and efficient differentiable reasoning that is based on the theory of provenance semirings. We evaluate Scallop on a suite of eight neurosymbolic applications from the literature. Our evaluation demonstrates that Scallop is capable of expressing algorithmic reasoning in diverse and challenging AI tasks, provides a succinct interface for machine learning programmers to integrate logical domain knowledge, and yields solutions that are comparable or superior to state-of-the-art models in terms of accuracy. Furthermore, Scallop's solutions outperform these models in aspects such as runtime and data efficiency, interpretability, and generalizability.
Do Machine Learning Models Learn Common Sense?
Mar 02, 2023



Machine learning models can make basic errors that are easily hidden within vast amounts of data. Such errors often run counter to human intuition referred to as "common sense". We thereby seek to characterize common sense for data-driven models, and quantify the extent to which a model has learned common sense. We propose a framework that integrates logic-based methods with statistical inference to derive common sense rules from a model's training data without supervision. We further show how to adapt models at test-time to reduce common sense rule violations and produce more coherent predictions. We evaluate our framework on datasets and models for three different domains. It generates around 250 to 300k rules over these datasets, and uncovers 1.5k to 26k violations of those rules by state-of-the-art models for the respective datasets. Test-time adaptation reduces these violations by up to 38% without impacting overall model accuracy.
Learning to Select Pivotal Samples for Meta Re-weighting
Feb 09, 2023
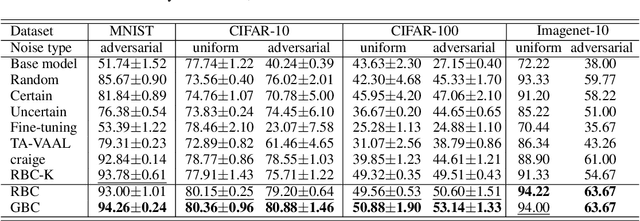
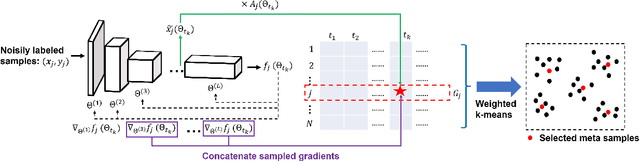
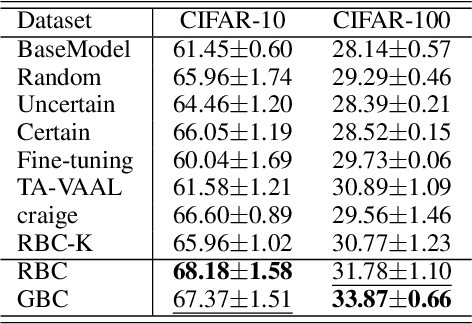
Sample re-weighting strategies provide a promising mechanism to deal with imperfect training data in machine learning, such as noisily labeled or class-imbalanced data. One such strategy involves formulating a bi-level optimization problem called the meta re-weighting problem, whose goal is to optimize performance on a small set of perfect pivotal samples, called meta samples. Many approaches have been proposed to efficiently solve this problem. However, all of them assume that a perfect meta sample set is already provided while we observe that the selections of meta sample set is performance critical. In this paper, we study how to learn to identify such a meta sample set from a large, imperfect training set, that is subsequently cleaned and used to optimize performance in the meta re-weighting setting. We propose a learning framework which reduces the meta samples selection problem to a weighted K-means clustering problem through rigorously theoretical analysis. We propose two clustering methods within our learning framework, Representation-based clustering method (RBC) and Gradient-based clustering method (GBC), for balancing performance and computational efficiency. Empirical studies demonstrate the performance advantage of our methods over various baseline methods.
Synthesizing Datalog Programs using Numerical Relaxation
Jun 01, 2019



The problem of learning logical rules from examples arises in diverse fields, including program synthesis, logic programming, and machine learning. Existing approaches either involve solving computationally difficult combinatorial problems, or performing parameter estimation in complex statistical models. In this paper, we present Difflog, a technique to extend the logic programming language Datalog to the continuous setting. By attaching real-valued weights to individual rules of a Datalog program, we naturally associate numerical values with individual conclusions of the program. Analogous to the strategy of numerical relaxation in optimization problems, we can now first determine the rule weights which cause the best agreement between the training labels and the induced values of output tuples, and subsequently recover the classical discrete-valued target program from the continuous optimum. We evaluate Difflog on a suite of 34 benchmark problems from recent literature in knowledge discovery, formal verification, and database query-by-example, and demonstrate significant improvements in learning complex programs with recursive rules, invented predicates, and relations of arbitrary arity.
Learning Neurosymbolic Generative Models via Program Synthesis
Jan 24, 2019



Significant strides have been made toward designing better generative models in recent years. Despite this progress, however, state-of-the-art approaches are still largely unable to capture complex global structure in data. For example, images of buildings typically contain spatial patterns such as windows repeating at regular intervals; state-of-the-art generative methods can't easily reproduce these structures. We propose to address this problem by incorporating programs representing global structure into the generative model---e.g., a 2D for-loop may represent a configuration of windows. Furthermore, we propose a framework for learning these models by leveraging program synthesis to generate training data. On both synthetic and real-world data, we demonstrate that our approach is substantially better than the state-of-the-art at both generating and completing images that contain global structure.
Mantis: Predicting System Performance through Program Analysis and Modeling
Sep 30, 2010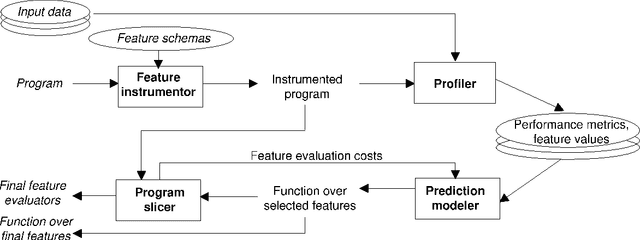

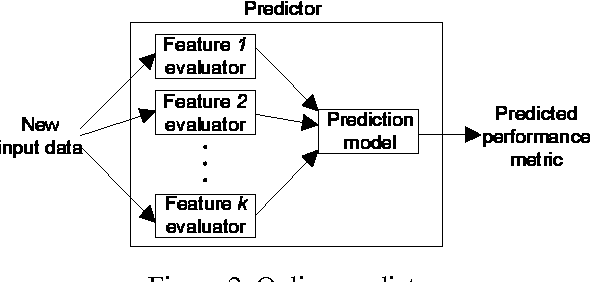
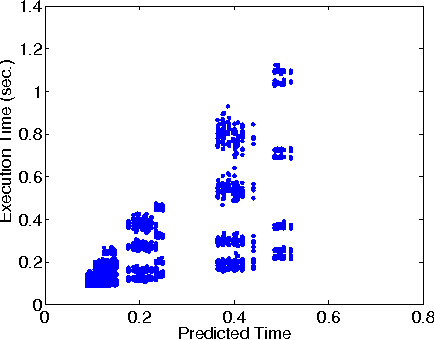
We present Mantis, a new framework that automatically predicts program performance with high accuracy. Mantis integrates techniques from programming language and machine learning for performance modeling, and is a radical departure from traditional approaches. Mantis extracts program features, which are information about program execution runs, through program instrumentation. It uses machine learning techniques to select features relevant to performance and creates prediction models as a function of the selected features. Through program analysis, it then generates compact code slices that compute these feature values for prediction. Our evaluation shows that Mantis can achieve more than 93% accuracy with less than 10% training data set, which is a significant improvement over models that are oblivious to program features. The system generates code slices that are cheap to compute feature values.