 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHao Ban
Fair Resource Allocation in Multi-Task Learning
Feb 23, 2024
By jointly learning multiple tasks, multi-task learning (MTL) can leverage the shared knowledge across tasks, resulting in improved data efficiency and generalization performance. However, a major challenge in MTL lies in the presence of conflicting gradients, which can hinder the fair optimization of some tasks and subsequently impede MTL's ability to achieve better overall performance. Inspired by fair resource allocation in communication networks, we formulate the optimization of MTL as a utility maximization problem, where the loss decreases across tasks are maximized under different fairness measurements. To solve this problem, we propose FairGrad, a novel MTL optimization method. FairGrad not only enables flexible emphasis on certain tasks but also achieves a theoretical convergence guarantee. Extensive experiments demonstrate that our method can achieve state-of-the-art performance among gradient manipulation methods on a suite of multi-task benchmarks in supervised learning and reinforcement learning. Furthermore, we incorporate the idea of $\alpha$-fairness into loss functions of various MTL methods. Extensive empirical studies demonstrate that their performance can be significantly enhanced. Code is provided at \url{https://github.com/OptMN-Lab/fairgrad}.
Direction-oriented Multi-objective Learning: Simple and Provable Stochastic Algorithms
May 28, 2023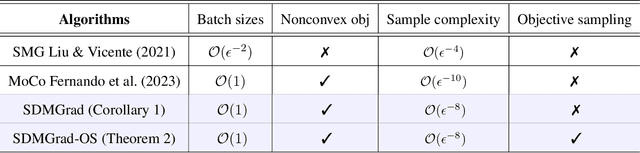
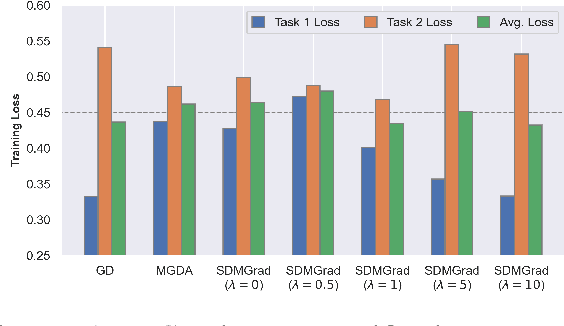
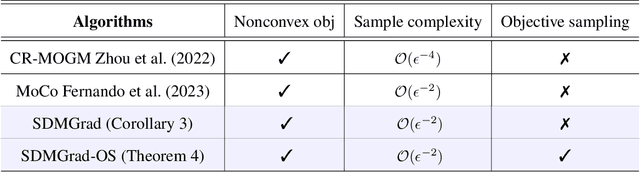
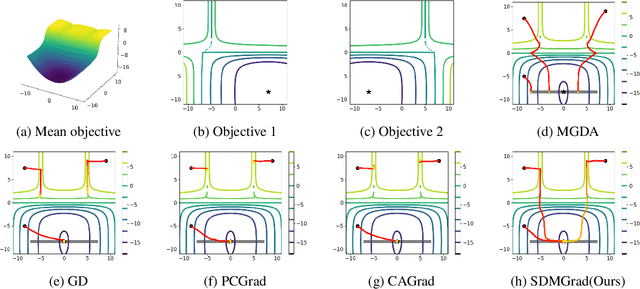
Multi-objective optimization (MOO) has become an influential framework in many machine learning problems with multiple objectives such as learning with multiple criteria and multi-task learning (MTL). In this paper, we propose a new direction-oriented multi-objective problem by regularizing the common descent direction within a neighborhood of a direction that optimizes a linear combination of objectives such as the average loss in MTL. This formulation includes GD and MGDA as special cases, enjoys the direction-oriented benefit as in CAGrad, and facilitates the design of stochastic algorithms. To solve this problem, we propose Stochastic Direction-oriented Multi-objective Gradient descent (SDMGrad) with simple SGD type of updates, and its variant SDMGrad-OS with an efficient objective sampling in the setting where the number of objectives is large. For a constant-level regularization parameter $\lambda$, we show that SDMGrad and SDMGrad-OS provably converge to a Pareto stationary point with improved complexities and milder assumptions. For an increasing $\lambda$, this convergent point reduces to a stationary point of the linear combination of objectives. We demonstrate the superior performance of the proposed methods in a series of tasks on multi-task supervised learning and reinforcement learning. Code is provided at https://github.com/ml-opt-lab/sdmgrad.
Interleaving Learning, with Application to Neural Architecture Search
Mar 12, 2021



Interleaving learning is a human learning technique where a learner interleaves the studies of multiple topics, which increases long-term retention and improves ability to transfer learned knowledge. Inspired by the interleaving learning technique of humans, in this paper we explore whether this learning methodology is beneficial for improving the performance of machine learning models as well. We propose a novel machine learning framework referred to as interleaving learning (IL). In our framework, a set of models collaboratively learn a data encoder in an interleaving fashion: the encoder is trained by model 1 for a while, then passed to model 2 for further training, then model 3, and so on; after trained by all models, the encoder returns back to model 1 and is trained again, then moving to model 2, 3, etc. This process repeats for multiple rounds. Our framework is based on multi-level optimization consisting of multiple inter-connected learning stages. An efficient gradient-based algorithm is developed to solve the multi-level optimization problem. We apply interleaving learning to search neural architectures for image classification on CIFAR-10, CIFAR-100, and ImageNet. The effectiveness of our method is strongly demonstrated by the experimental results.
Skillearn: Machine Learning Inspired by Humans' Learning Skills
Dec 09, 2020



Humans, as the most powerful learners on the planet, have accumulated a lot of learning skills, such as learning through tests, interleaving learning, self-explanation, active recalling, to name a few. These learning skills and methodologies enable humans to learn new topics more effectively and efficiently. We are interested in investigating whether humans' learning skills can be borrowed to help machines to learn better. Specifically, we aim to formalize these skills and leverage them to train better machine learning (ML) models. To achieve this goal, we develop a general framework -- Skillearn, which provides a principled way to represent humans' learning skills mathematically and use the formally-represented skills to improve the training of ML models. In two case studies, we apply Skillearn to formalize two learning skills of humans: learning by passing tests and interleaving learning, and use the formalized skills to improve neural architecture search. Experiments on various datasets show that trained using the skills formalized by Skillearn, ML models achieve significantly better performance.