 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKaiyi Ji
Fair Resource Allocation in Multi-Task Learning
Feb 23, 2024
By jointly learning multiple tasks, multi-task learning (MTL) can leverage the shared knowledge across tasks, resulting in improved data efficiency and generalization performance. However, a major challenge in MTL lies in the presence of conflicting gradients, which can hinder the fair optimization of some tasks and subsequently impede MTL's ability to achieve better overall performance. Inspired by fair resource allocation in communication networks, we formulate the optimization of MTL as a utility maximization problem, where the loss decreases across tasks are maximized under different fairness measurements. To solve this problem, we propose FairGrad, a novel MTL optimization method. FairGrad not only enables flexible emphasis on certain tasks but also achieves a theoretical convergence guarantee. Extensive experiments demonstrate that our method can achieve state-of-the-art performance among gradient manipulation methods on a suite of multi-task benchmarks in supervised learning and reinforcement learning. Furthermore, we incorporate the idea of $\alpha$-fairness into loss functions of various MTL methods. Extensive empirical studies demonstrate that their performance can be significantly enhanced. Code is provided at \url{https://github.com/OptMN-Lab/fairgrad}.
Discriminative Adversarial Unlearning
Feb 13, 2024We introduce a novel machine unlearning framework founded upon the established principles of the min-max optimization paradigm. We capitalize on the capabilities of strong Membership Inference Attacks (MIA) to facilitate the unlearning of specific samples from a trained model. We consider the scenario of two networks, the attacker $\mathbf{A}$ and the trained defender $\mathbf{D}$ pitted against each other in an adversarial objective, wherein the attacker aims at teasing out the information of the data to be unlearned in order to infer membership, and the defender unlearns to defend the network against the attack, whilst preserving its general performance. The algorithm can be trained end-to-end using backpropagation, following the well known iterative min-max approach in updating the attacker and the defender. We additionally incorporate a self-supervised objective effectively addressing the feature space discrepancies between the forget set and the validation set, enhancing unlearning performance. Our proposed algorithm closely approximates the ideal benchmark of retraining from scratch for both random sample forgetting and class-wise forgetting schemes on standard machine-unlearning datasets. Specifically, on the class unlearning scheme, the method demonstrates near-optimal performance and comprehensively overcomes known methods over the random sample forgetting scheme across all metrics and multiple network pruning strategies.
Achieving ${O}(ε^{-1.5})$ Complexity in Hessian/Jacobian-free Stochastic Bilevel Optimization
Dec 20, 2023In this paper, we revisit the bilevel optimization problem, in which the upper-level objective function is generally nonconvex and the lower-level objective function is strongly convex. Although this type of problem has been studied extensively, it still remains an open question how to achieve an ${O}(\epsilon^{-1.5})$ sample complexity in Hessian/Jacobian-free stochastic bilevel optimization without any second-order derivative computation. To fill this gap, we propose a novel Hessian/Jacobian-free bilevel optimizer named FdeHBO, which features a simple fully single-loop structure, a projection-aided finite-difference Hessian/Jacobian-vector approximation, and momentum-based updates. Theoretically, we show that FdeHBO requires ${O}(\epsilon^{-1.5})$ iterations (each using ${O}(1)$ samples and only first-order gradient information) to find an $\epsilon$-accurate stationary point. As far as we know, this is the first Hessian/Jacobian-free method with an ${O}(\epsilon^{-1.5})$ sample complexity for nonconvex-strongly-convex stochastic bilevel optimization.
Non-Convex Bilevel Optimization with Time-Varying Objective Functions
Aug 07, 2023Bilevel optimization has become a powerful tool in a wide variety of machine learning problems. However, the current nonconvex bilevel optimization considers an offline dataset and static functions, which may not work well in emerging online applications with streaming data and time-varying functions. In this work, we study online bilevel optimization (OBO) where the functions can be time-varying and the agent continuously updates the decisions with online streaming data. To deal with the function variations and the unavailability of the true hypergradients in OBO, we propose a single-loop online bilevel optimizer with window averaging (SOBOW), which updates the outer-level decision based on a window average of the most recent hypergradient estimations stored in the memory. Compared to existing algorithms, SOBOW is computationally efficient and does not need to know previous functions. To handle the unique technical difficulties rooted in single-loop update and function variations for OBO, we develop a novel analytical technique that disentangles the complex couplings between decision variables, and carefully controls the hypergradient estimation error. We show that SOBOW can achieve a sublinear bilevel local regret under mild conditions. Extensive experiments across multiple domains corroborate the effectiveness of SOBOW.
SimFBO: Towards Simple, Flexible and Communication-efficient Federated Bilevel Learning
Jun 12, 2023Federated bilevel optimization (FBO) has shown great potential recently in machine learning and edge computing due to the emerging nested optimization structure in meta-learning, fine-tuning, hyperparameter tuning, etc. However, existing FBO algorithms often involve complicated computations and require multiple sub-loops per iteration, each of which contains a number of communication rounds. In this paper, we propose a simple and flexible FBO framework named SimFBO, which is easy to implement without sub-loops, and includes a generalized server-side aggregation and update for improving communication efficiency. We further propose System-level heterogeneity robust FBO (ShroFBO) as a variant of SimFBO with stronger resilience to heterogeneous local computation. We show that SimFBO and ShroFBO provably achieve a linear convergence speedup with partial client participation and client sampling without replacement, as well as improved sample and communication complexities. Experiments demonstrate the effectiveness of the proposed methods over existing FBO algorithms.
Direction-oriented Multi-objective Learning: Simple and Provable Stochastic Algorithms
May 28, 2023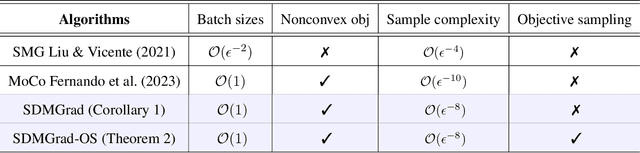
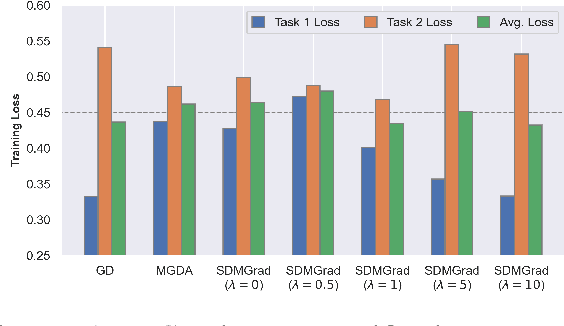
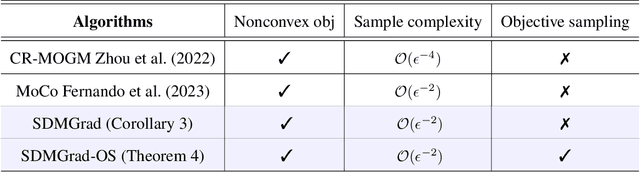
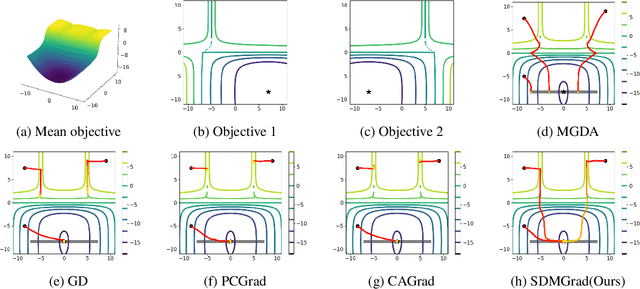
Multi-objective optimization (MOO) has become an influential framework in many machine learning problems with multiple objectives such as learning with multiple criteria and multi-task learning (MTL). In this paper, we propose a new direction-oriented multi-objective problem by regularizing the common descent direction within a neighborhood of a direction that optimizes a linear combination of objectives such as the average loss in MTL. This formulation includes GD and MGDA as special cases, enjoys the direction-oriented benefit as in CAGrad, and facilitates the design of stochastic algorithms. To solve this problem, we propose Stochastic Direction-oriented Multi-objective Gradient descent (SDMGrad) with simple SGD type of updates, and its variant SDMGrad-OS with an efficient objective sampling in the setting where the number of objectives is large. For a constant-level regularization parameter $\lambda$, we show that SDMGrad and SDMGrad-OS provably converge to a Pareto stationary point with improved complexities and milder assumptions. For an increasing $\lambda$, this convergent point reduces to a stationary point of the linear combination of objectives. We demonstrate the superior performance of the proposed methods in a series of tasks on multi-task supervised learning and reinforcement learning. Code is provided at https://github.com/ml-opt-lab/sdmgrad.
Communication-Efficient Federated Hypergradient Computation via Aggregated Iterative Differentiation
Feb 23, 2023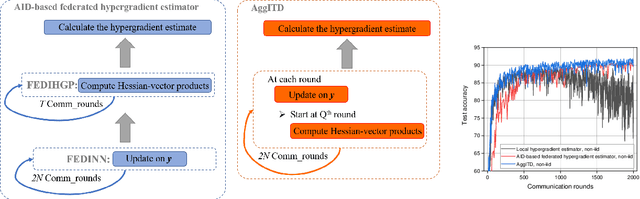
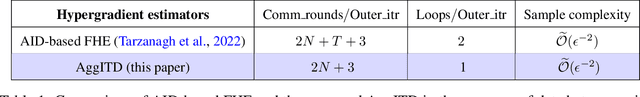


Federated bilevel optimization has attracted increasing attention due to emerging machine learning and communication applications. The biggest challenge lies in computing the gradient of the upper-level objective function (i.e., hypergradient) in the federated setting due to the nonlinear and distributed construction of a series of global Hessian matrices. In this paper, we propose a novel communication-efficient federated hypergradient estimator via aggregated iterative differentiation (AggITD). AggITD is simple to implement and significantly reduces the communication cost by conducting the federated hypergradient estimation and the lower-level optimization simultaneously. We show that the proposed AggITD-based algorithm achieves the same sample complexity as existing approximate implicit differentiation (AID)-based approaches with much fewer communication rounds in the presence of data heterogeneity. Our results also shed light on the great advantage of ITD over AID in the federated/distributed hypergradient estimation. This differs from the comparison in the non-distributed bilevel optimization, where ITD is less efficient than AID. Our extensive experiments demonstrate the great effectiveness and communication efficiency of the proposed method.
Achieving Linear Speedup in Non-IID Federated Bilevel Learning
Feb 10, 2023
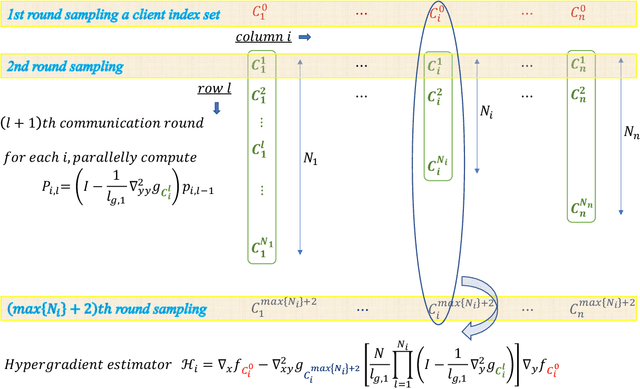
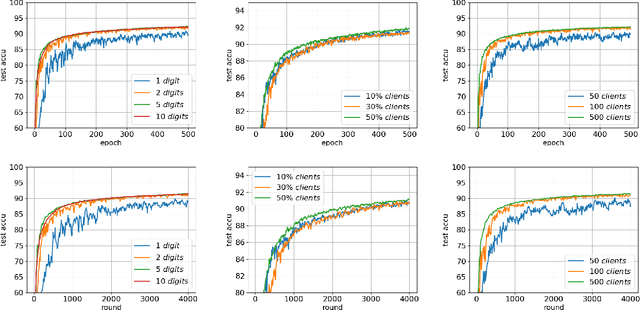
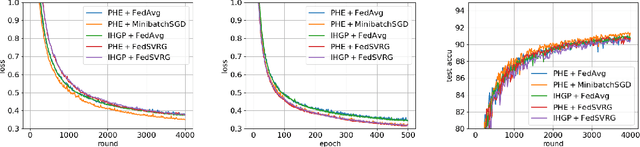
Federated bilevel optimization has received increasing attention in various emerging machine learning and communication applications. Recently, several Hessian-vector-based algorithms have been proposed to solve the federated bilevel optimization problem. However, several important properties in federated learning such as the partial client participation and the linear speedup for convergence (i.e., the convergence rate and complexity are improved linearly with respect to the number of sampled clients) in the presence of non-i.i.d.~datasets, still remain open. In this paper, we fill these gaps by proposing a new federated bilevel algorithm named FedMBO with a novel client sampling scheme in the federated hypergradient estimation. We show that FedMBO achieves a convergence rate of $\mathcal{O}\big(\frac{1}{\sqrt{nK}}+\frac{1}{K}+\frac{\sqrt{n}}{K^{3/2}}\big)$ on non-i.i.d.~datasets, where $n$ is the number of participating clients in each round, and $K$ is the total number of iteration. This is the first theoretical linear speedup result for non-i.i.d.~federated bilevel optimization. Extensive experiments validate our theoretical results and demonstrate the effectiveness of our proposed method.