 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHao Jin
A Semi-automatic Oriental Ink Painting Framework for Robotic Drawing from 3D Models
Aug 26, 2023
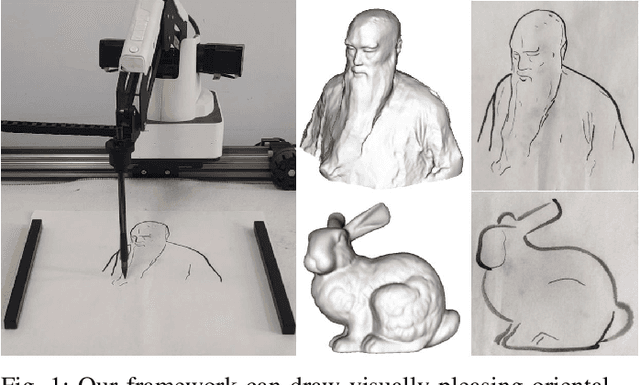
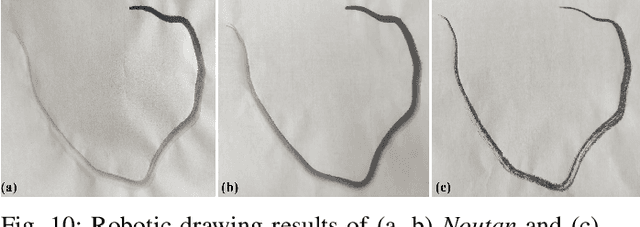

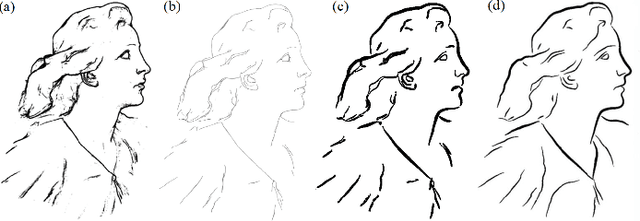
Creating visually pleasing stylized ink paintings from 3D models is a challenge in robotic manipulation. We propose a semi-automatic framework that can extract expressive strokes from 3D models and draw them in oriental ink painting styles by using a robotic arm. The framework consists of a simulation stage and a robotic drawing stage. In the simulation stage, geometrical contours were automatically extracted from a certain viewpoint and a neural network was employed to create simplified contours. Then, expressive digital strokes were generated after interactive editing according to user's aesthetic understanding. In the robotic drawing stage, an optimization method was presented for drawing smooth and physically consistent strokes to the digital strokes, and two oriental ink painting styles termed as Noutan (shade) and Kasure (scratchiness) were applied to the strokes by robotic control of a brush's translation, dipping and scraping. Unlike existing methods that concentrate on generating paintings from 2D images, our framework has the advantage of rendering stylized ink paintings from 3D models by using a consumer-grade robotic arm. We evaluate the proposed framework by taking 3 standard models and a user-defined model as examples. The results show that our framework is able to draw visually pleasing oriental ink paintings with expressive strokes.
Federated Reinforcement Learning with Environment Heterogeneity
Apr 06, 2022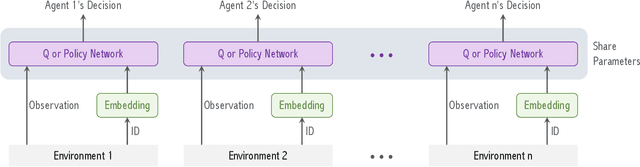
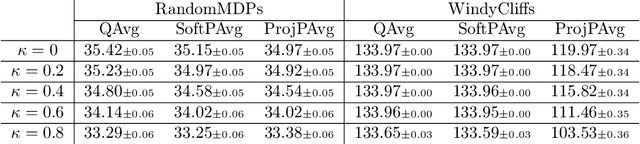

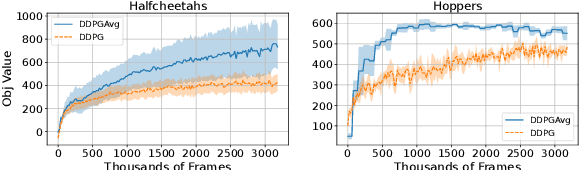
We study a Federated Reinforcement Learning (FedRL) problem in which $n$ agents collaboratively learn a single policy without sharing the trajectories they collected during agent-environment interaction. We stress the constraint of environment heterogeneity, which means $n$ environments corresponding to these $n$ agents have different state transitions. To obtain a value function or a policy function which optimizes the overall performance in all environments, we propose two federated RL algorithms, \texttt{QAvg} and \texttt{PAvg}. We theoretically prove that these algorithms converge to suboptimal solutions, while such suboptimality depends on how heterogeneous these $n$ environments are. Moreover, we propose a heuristic that achieves personalization by embedding the $n$ environments into $n$ vectors. The personalization heuristic not only improves the training but also allows for better generalization to new environments.
Meta-Regularization: An Approach to Adaptive Choice of the Learning Rate in Gradient Descent
Apr 12, 2021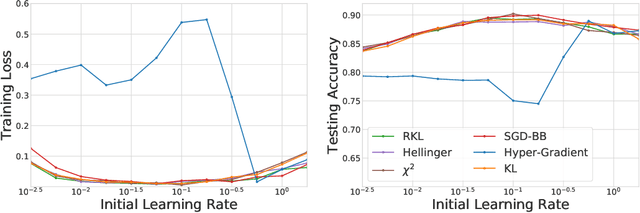
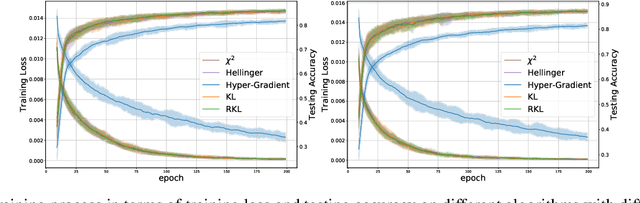
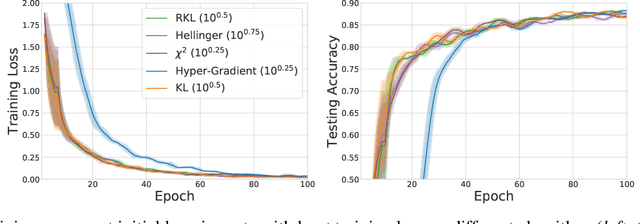
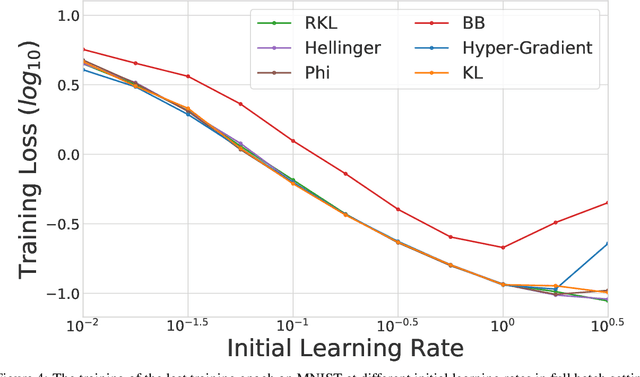
We propose \textit{Meta-Regularization}, a novel approach for the adaptive choice of the learning rate in first-order gradient descent methods. Our approach modifies the objective function by adding a regularization term on the learning rate, and casts the joint updating process of parameters and learning rates into a maxmin problem. Given any regularization term, our approach facilitates the generation of practical algorithms. When \textit{Meta-Regularization} takes the $\varphi$-divergence as a regularizer, the resulting algorithms exhibit comparable theoretical convergence performance with other first-order gradient-based algorithms. Furthermore, we theoretically prove that some well-designed regularizers can improve the convergence performance under the strong-convexity condition of the objective function. Numerical experiments on benchmark problems demonstrate the effectiveness of algorithms derived from some common $\varphi$-divergence in full batch as well as online learning settings.
Natural Language Adversarial Attacks and Defenses in Word Level
Sep 24, 2019
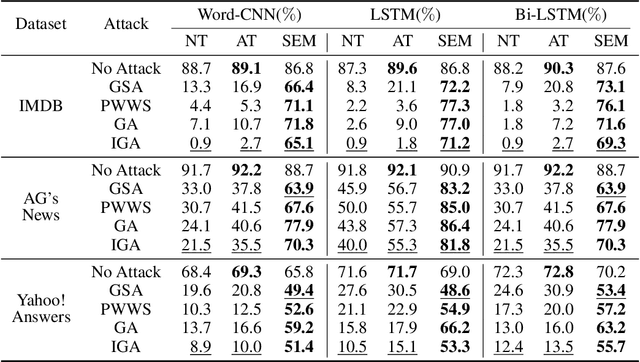
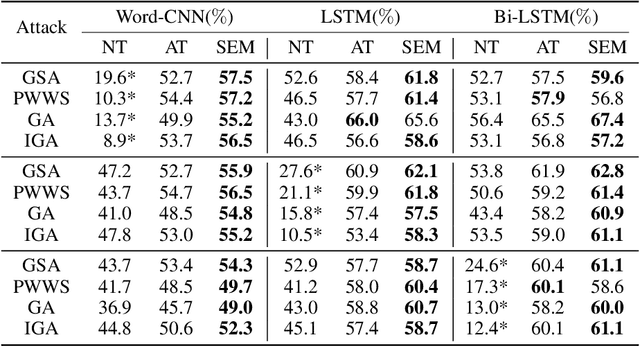
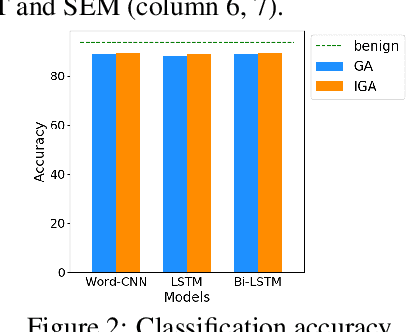
Up until recent two years, inspired by the big amount of research about adversarial example in the field of computer vision, there has been a growing interest in adversarial attacks for Natural Language Processing (NLP). What followed was a very few works of adversarial defense for NLP. However, there exists no defense method against the successful synonyms substitution based attacks that aim to satisfy all the lexical, grammatical, semantic constraints and thus are hard to perceived by humans. To fill this gap, we postulate the generalization of the model leads to the existence of adversarial examples, and propose an adversarial defense method called Synonyms Encoding Method (SEM), which inserts an encoder before the input layer of the model and then trains the model to eliminate adversarial perturbations. Extensive experiments demonstrate that SEM can efficiently defend current best synonym substitution based adversarial attacks with almost no decay on the accuracy for benign examples. Besides, to better evaluate SEM, we also propose a strong attack method called Improved Genetic Algorithm (IGA) that adopts the genetic metaheuristic against synonyms substitution based attacks. Compared with existing genetic based adversarial attack, the proposed IGA can achieve higher attack success rate at the same time maintain the transferability of adversarial examples.
Towards Better Generalization: BP-SVRG in Training Deep Neural Networks
Aug 18, 2019
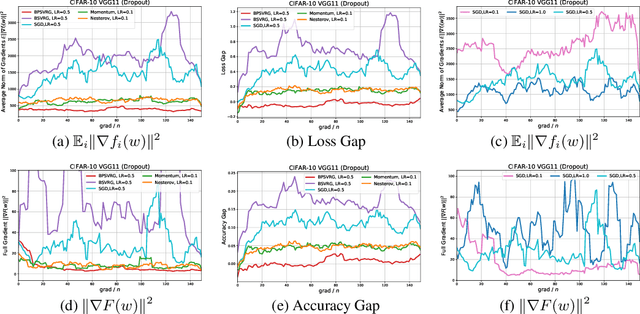

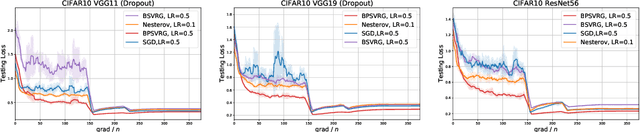
Stochastic variance-reduced gradient (SVRG) is a classical optimization method. Although it is theoretically proved to have better convergence performance than stochastic gradient descent (SGD), the generalization performance of SVRG remains open. In this paper we investigate the effects of some training techniques, mini-batching and learning rate decay, on the generalization performance of SVRG, and verify the generalization performance of Batch-SVRG (B-SVRG). In terms of the relationship between optimization and generalization, we believe that the average norm of gradients on each training sample as well as the norm of average gradient indicate how flat the landscape is and how well the model generalizes. Based on empirical observations of such metrics, we perform a sign switch on B-SVRG and derive a practical algorithm, BatchPlus-SVRG (BP-SVRG), which is numerically shown to enjoy better generalization performance than B-SVRG, even SGD in some scenarios of deep neural networks.