 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHaotian Fu
Model-based Reinforcement Learning for Parameterized Action Spaces
Apr 05, 2024
We propose a novel model-based reinforcement learning algorithm -- Dynamics Learning and predictive control with Parameterized Actions (DLPA) -- for Parameterized Action Markov Decision Processes (PAMDPs). The agent learns a parameterized-action-conditioned dynamics model and plans with a modified Model Predictive Path Integral control. We theoretically quantify the difference between the generated trajectory and the optimal trajectory during planning in terms of the value they achieved through the lens of Lipschitz Continuity. Our empirical results on several standard benchmarks show that our algorithm achieves superior sample efficiency and asymptotic performance than state-of-the-art PAMDP methods.
Language-guided Skill Learning with Temporal Variational Inference
Feb 26, 2024We present an algorithm for skill discovery from expert demonstrations. The algorithm first utilizes Large Language Models (LLMs) to propose an initial segmentation of the trajectories. Following that, a hierarchical variational inference framework incorporates the LLM-generated segmentation information to discover reusable skills by merging trajectory segments. To further control the trade-off between compression and reusability, we introduce a novel auxiliary objective based on the Minimum Description Length principle that helps guide this skill discovery process. Our results demonstrate that agents equipped with our method are able to discover skills that help accelerate learning and outperform baseline skill learning approaches on new long-horizon tasks in BabyAI, a grid world navigation environment, as well as ALFRED, a household simulation environment.
CLIF: Complementary Leaky Integrate-and-Fire Neuron for Spiking Neural Networks
Feb 08, 2024Spiking neural networks (SNNs) are promising brain-inspired energy-efficient models. Compared to conventional deep Artificial Neural Networks (ANNs), SNNs exhibit superior efficiency and capability to process temporal information. However, it remains a challenge to train SNNs due to their undifferentiable spiking mechanism. The surrogate gradients method is commonly used to train SNNs, but often comes with an accuracy disadvantage over ANNs counterpart. We link the degraded accuracy to the vanishing of gradient on the temporal dimension through the analytical and experimental study of the training process of Leaky Integrate-and-Fire (LIF) Neuron-based SNNs. Moreover, we propose the Complementary Leaky Integrate-and-Fire (CLIF) Neuron. CLIF creates extra paths to facilitate the backpropagation in computing temporal gradient while keeping binary output. CLIF is hyperparameter-free and features broad applicability. Extensive experiments on a variety of datasets demonstrate CLIF's clear performance advantage over other neuron models. Moreover, the CLIF's performance even slightly surpasses superior ANNs with identical network structure and training conditions.
SpikePoint: An Efficient Point-based Spiking Neural Network for Event Cameras Action Recognition
Oct 11, 2023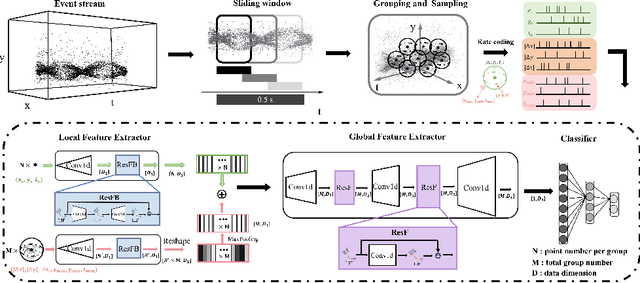
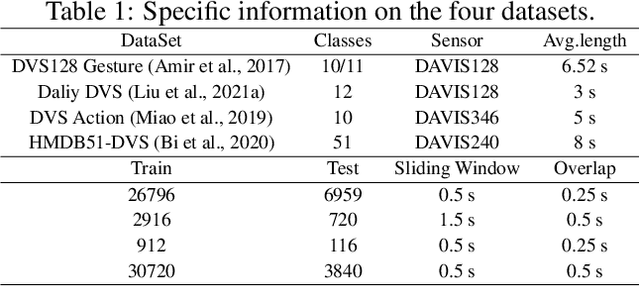
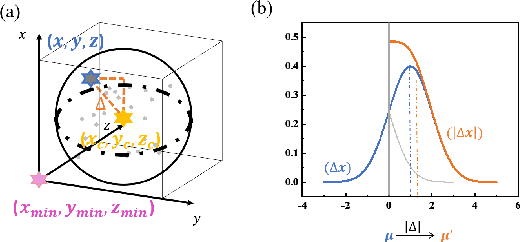
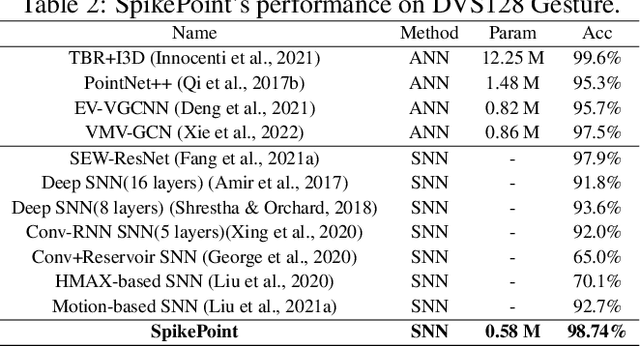
Event cameras are bio-inspired sensors that respond to local changes in light intensity and feature low latency, high energy efficiency, and high dynamic range. Meanwhile, Spiking Neural Networks (SNNs) have gained significant attention due to their remarkable efficiency and fault tolerance. By synergistically harnessing the energy efficiency inherent in event cameras and the spike-based processing capabilities of SNNs, their integration could enable ultra-low-power application scenarios, such as action recognition tasks. However, existing approaches often entail converting asynchronous events into conventional frames, leading to additional data mapping efforts and a loss of sparsity, contradicting the design concept of SNNs and event cameras. To address this challenge, we propose SpikePoint, a novel end-to-end point-based SNN architecture. SpikePoint excels at processing sparse event cloud data, effectively extracting both global and local features through a singular-stage structure. Leveraging the surrogate training method, SpikePoint achieves high accuracy with few parameters and maintains low power consumption, specifically employing the identity mapping feature extractor on diverse datasets. SpikePoint achieves state-of-the-art (SOTA) performance on four event-based action recognition datasets using only 16 timesteps, surpassing other SNN methods. Moreover, it also achieves SOTA performance across all methods on three datasets, utilizing approximately 0.3\% of the parameters and 0.5\% of power consumption employed by artificial neural networks (ANNs). These results emphasize the significance of Point Cloud and pave the way for many ultra-low-power event-based data processing applications.
TTPOINT: A Tensorized Point Cloud Network for Lightweight Action Recognition with Event Cameras
Aug 19, 2023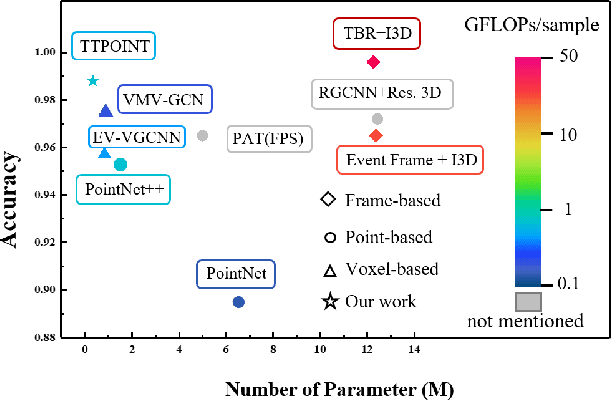

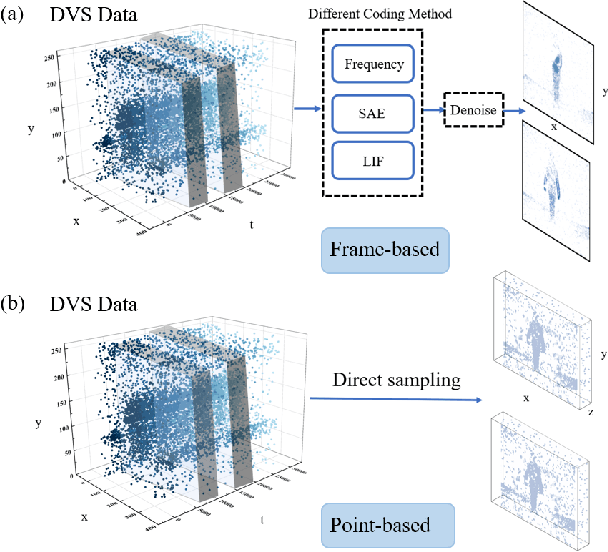

Event cameras have gained popularity in computer vision due to their data sparsity, high dynamic range, and low latency. As a bio-inspired sensor, event cameras generate sparse and asynchronous data, which is inherently incompatible with the traditional frame-based method. Alternatively, the point-based method can avoid additional modality transformation and naturally adapt to the sparsity of events. Still, it typically cannot reach a comparable accuracy as the frame-based method. We propose a lightweight and generalized point cloud network called TTPOINT which achieves competitive results even compared to the state-of-the-art (SOTA) frame-based method in action recognition tasks while only using 1.5 % of the computational resources. The model is adept at abstracting local and global geometry by hierarchy structure. By leveraging tensor-train compressed feature extractors, TTPOINT can be designed with minimal parameters and computational complexity. Additionally, we developed a straightforward downsampling algorithm to maintain the spatio-temporal feature. In the experiment, TTPOINT emerged as the SOTA method on three datasets while also attaining SOTA among point cloud methods on all five datasets. Moreover, by using the tensor-train decomposition method, the accuracy of the proposed TTPOINT is almost unaffected while compressing the parameter size by 55 % in all five datasets.
A Domain-Agnostic Approach for Characterization of Lifelong Learning Systems
Jan 18, 2023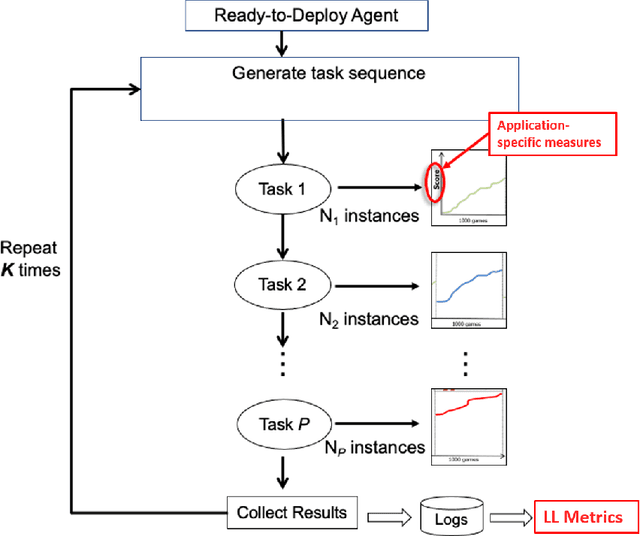
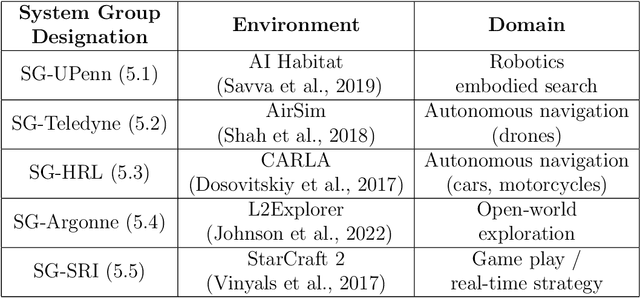


Despite the advancement of machine learning techniques in recent years, state-of-the-art systems lack robustness to "real world" events, where the input distributions and tasks encountered by the deployed systems will not be limited to the original training context, and systems will instead need to adapt to novel distributions and tasks while deployed. This critical gap may be addressed through the development of "Lifelong Learning" systems that are capable of 1) Continuous Learning, 2) Transfer and Adaptation, and 3) Scalability. Unfortunately, efforts to improve these capabilities are typically treated as distinct areas of research that are assessed independently, without regard to the impact of each separate capability on other aspects of the system. We instead propose a holistic approach, using a suite of metrics and an evaluation framework to assess Lifelong Learning in a principled way that is agnostic to specific domains or system techniques. Through five case studies, we show that this suite of metrics can inform the development of varied and complex Lifelong Learning systems. We highlight how the proposed suite of metrics quantifies performance trade-offs present during Lifelong Learning system development - both the widely discussed Stability-Plasticity dilemma and the newly proposed relationship between Sample Efficient and Robust Learning. Further, we make recommendations for the formulation and use of metrics to guide the continuing development of Lifelong Learning systems and assess their progress in the future.
Meta-Learning Transferable Parameterized Skills
Jun 07, 2022
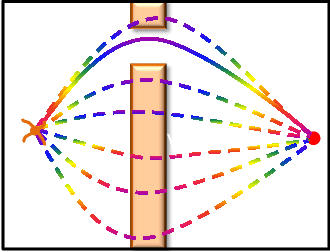
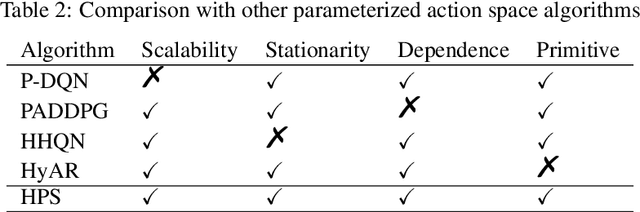
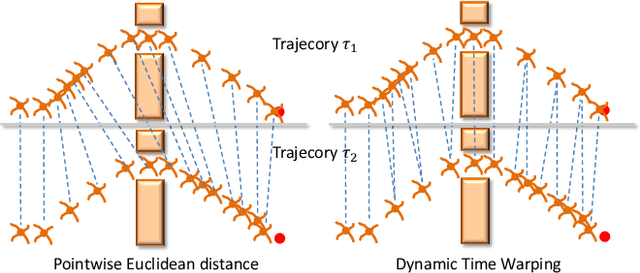
We propose a novel parameterized skill-learning algorithm that aims to learn transferable parameterized skills and synthesize them into a new action space that supports efficient learning in long-horizon tasks. We first propose novel learning objectives -- trajectory-centric diversity and smoothness -- that allow an agent to meta-learn reusable parameterized skills. Our agent can use these learned skills to construct a temporally-extended parameterized-action Markov decision process, for which we propose a hierarchical actor-critic algorithm that aims to efficiently learn a high-level control policy with the learned skills. We empirically demonstrate that the proposed algorithms enable an agent to solve a complicated long-horizon obstacle-course environment.
Towards Effective Context for Meta-Reinforcement Learning: an Approach based on Contrastive Learning
Oct 07, 2020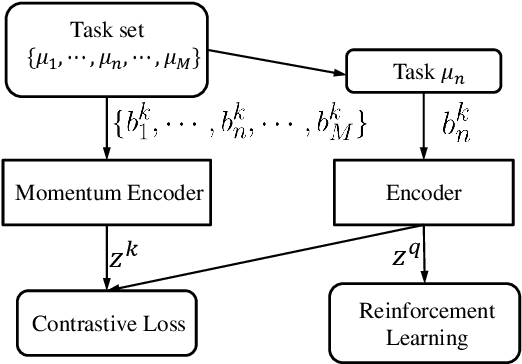

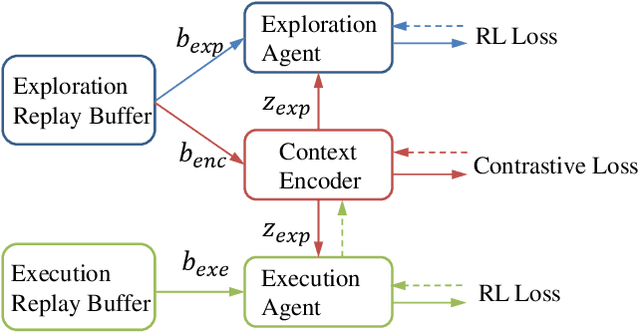
Context, the embedding of previous collected trajectories, is a powerful construct for Meta-Reinforcement Learning (Meta-RL) algorithms. By conditioning on an effective context, Meta-RL policies can easily generalize to new tasks within a few adaptation steps. We argue that improving the quality of context involves answering two questions: 1. How to train a compact and sufficient encoder that can embed the task-specific information contained in prior trajectories? 2. How to collect informative trajectories of which the corresponding context reflects the specification of tasks? To this end, we propose a novel Meta-RL framework called CCM (Contrastive learning augmented Context-based Meta-RL). We first focus on the contrastive nature behind different tasks and leverage it to train a compact and sufficient context encoder. Further, we train a separate exploration policy and theoretically derive a new information-gain-based objective which aims to collect informative trajectories in a few steps. Empirically, we evaluate our approaches on common benchmarks as well as several complex sparse-reward environments. The experimental results show that CCM outperforms state-of-the-art algorithms by addressing previously mentioned problems respectively.
Efficient meta reinforcement learning via meta goal generation
Nov 10, 2019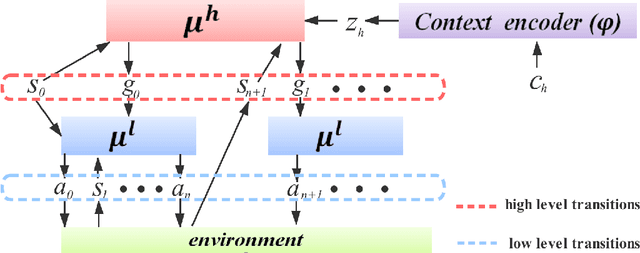
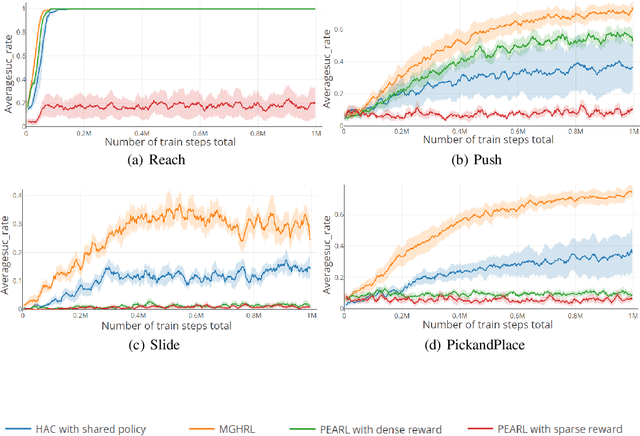
Meta reinforcement learning (meta-RL) is able to accelerate the acquisition of new tasks by learning from past experience. Current meta-RL methods usually learn to adapt to new tasks by directly optimizing the parameters of policies over primitive actions. However, for complex tasks which requires sophisticated control strategies, it would be quite inefficient to to directly learn such a meta-policy. Moreover, this problem can become more severe and even fail in spare reward settings, which is quite common in practice. To this end, we propose a new meta-RL algorithm called meta goal-generation for hierarchical RL (MGHRL) by leveraging hierarchical actor-critic framework. Instead of directly generate policies over primitive actions for new tasks, MGHRL learns to generate high-level meta strategies over subgoals given past experience and leaves the rest of how to achieve subgoals as independent RL subtasks. Our empirical results on several challenging simulated robotics environments show that our method enables more efficient and effective meta-learning from past experience and outperforms state-of-the-art meta-RL and Hierarchical-RL methods in sparse reward settings.
Deep Multi-Agent Reinforcement Learning with Discrete-Continuous Hybrid Action Spaces
Mar 12, 2019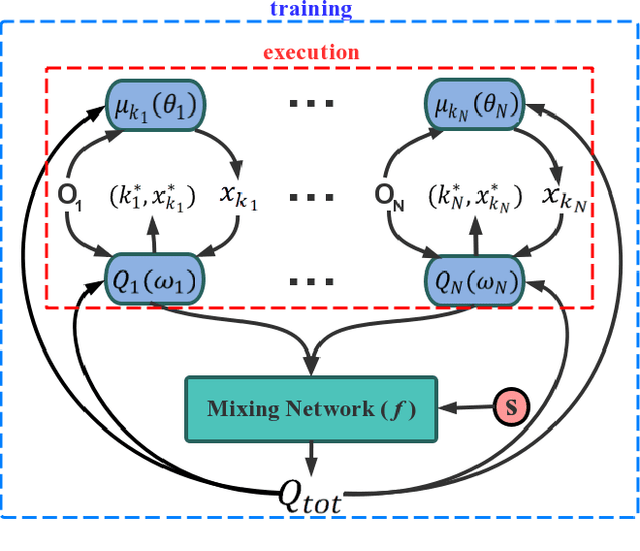
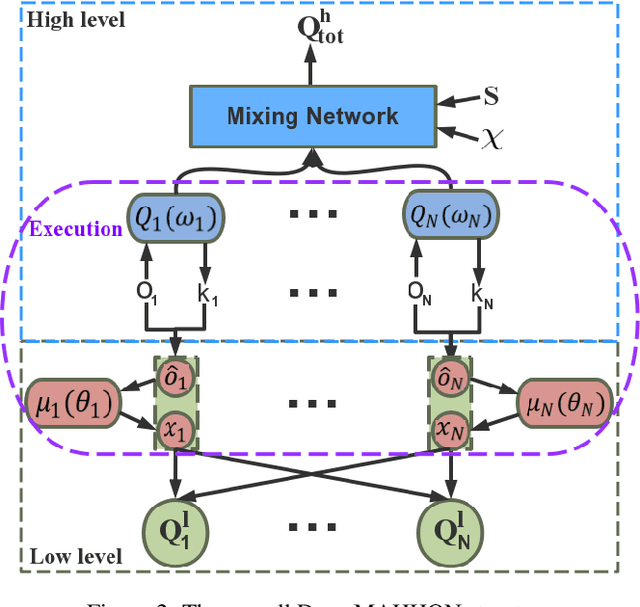
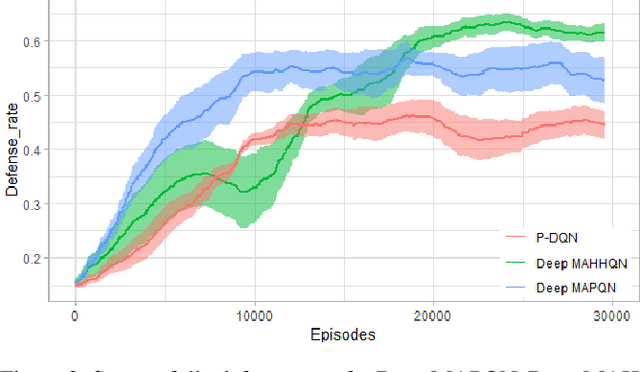
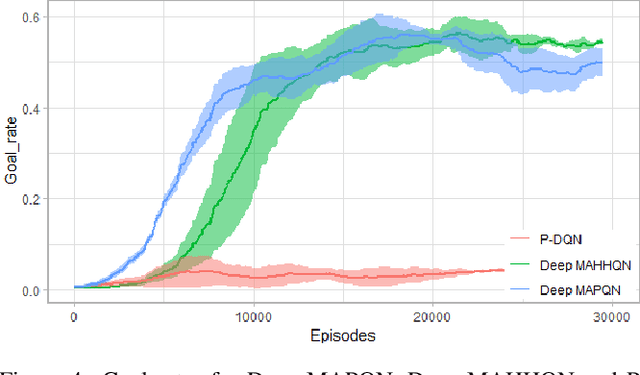
Deep Reinforcement Learning (DRL) has been applied to address a variety of cooperative multi-agent problems with either discrete action spaces or continuous action spaces. However, to the best of our knowledge, no previous work has ever succeeded in applying DRL to multi-agent problems with discrete-continuous hybrid (or parameterized) action spaces which is very common in practice. Our work fills this gap by proposing two novel algorithms: Deep Multi-Agent Parameterized Q-Networks (Deep MAPQN) and Deep Multi-Agent Hierarchical Hybrid Q-Networks (Deep MAHHQN). We follow the centralized training but decentralized execution paradigm: different levels of communication between different agents are used to facilitate the training process, while each agent executes its policy independently based on local observations during execution. Our empirical results on several challenging tasks (simulated RoboCup Soccer and game Ghost Story) show that both Deep MAPQN and Deep MAHHQN are effective and significantly outperform existing independent deep parameterized Q-learning method.