 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHaoyang Liu
Towards Adversarially Robust Dataset Distillation by Curvature Regularization
Mar 15, 2024
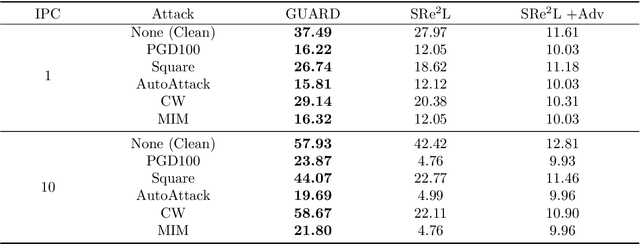

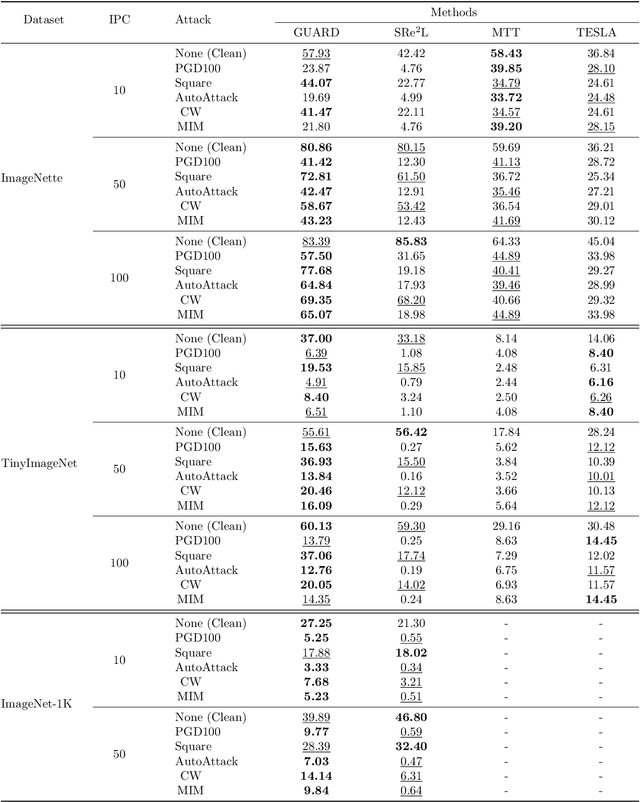
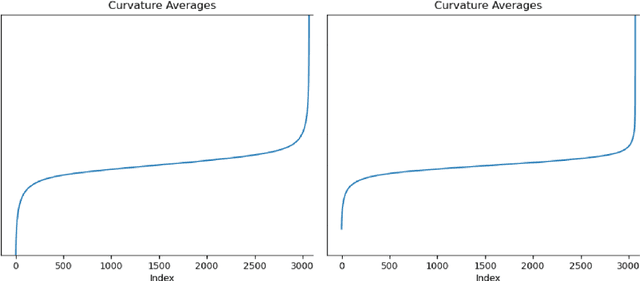
Dataset distillation (DD) allows datasets to be distilled to fractions of their original size while preserving the rich distributional information so that models trained on the distilled datasets can achieve a comparable accuracy while saving significant computational loads. Recent research in this area has been focusing on improving the accuracy of models trained on distilled datasets. In this paper, we aim to explore a new perspective of DD. We study how to embed adversarial robustness in distilled datasets, so that models trained on these datasets maintain the high accuracy and meanwhile acquire better adversarial robustness. We propose a new method that achieves this goal by incorporating curvature regularization into the distillation process with much less computational overhead than standard adversarial training. Extensive empirical experiments suggest that our method not only outperforms standard adversarial training on both accuracy and robustness with less computation overhead but is also capable of generating robust distilled datasets that can withstand various adversarial attacks.
Approximate Nullspace Augmented Finetuning for Robust Vision Transformers
Mar 15, 2024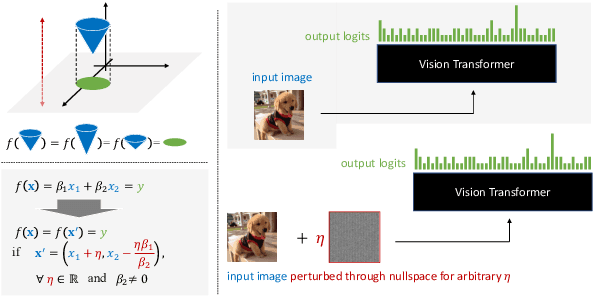
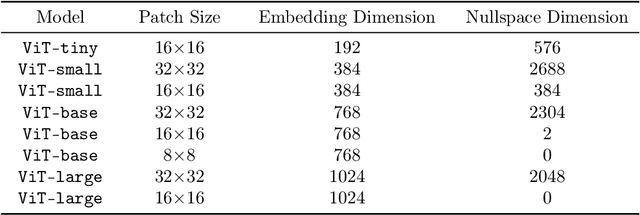

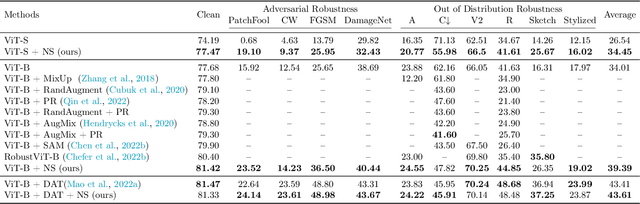
Enhancing the robustness of deep learning models, particularly in the realm of vision transformers (ViTs), is crucial for their real-world deployment. In this work, we provide a finetuning approach to enhance the robustness of vision transformers inspired by the concept of nullspace from linear algebra. Our investigation centers on whether a vision transformer can exhibit resilience to input variations akin to the nullspace property in linear mappings, implying that perturbations sampled from this nullspace do not influence the model's output when added to the input. Firstly, we show that for many pretrained ViTs, a non-trivial nullspace exists due to the presence of the patch embedding layer. Secondly, as nullspace is a concept associated with linear algebra, we demonstrate that it is possible to synthesize approximate nullspace elements for the non-linear blocks of ViTs employing an optimisation strategy. Finally, we propose a fine-tuning strategy for ViTs wherein we augment the training data with synthesized approximate nullspace noise. After finetuning, we find that the model demonstrates robustness to adversarial and natural image perbutations alike.
Toward a Team of AI-made Scientists for Scientific Discovery from Gene Expression Data
Feb 21, 2024Machine learning has emerged as a powerful tool for scientific discovery, enabling researchers to extract meaningful insights from complex datasets. For instance, it has facilitated the identification of disease-predictive genes from gene expression data, significantly advancing healthcare. However, the traditional process for analyzing such datasets demands substantial human effort and expertise for the data selection, processing, and analysis. To address this challenge, we introduce a novel framework, a Team of AI-made Scientists (TAIS), designed to streamline the scientific discovery pipeline. TAIS comprises simulated roles, including a project manager, data engineer, and domain expert, each represented by a Large Language Model (LLM). These roles collaborate to replicate the tasks typically performed by data scientists, with a specific focus on identifying disease-predictive genes. Furthermore, we have curated a benchmark dataset to assess TAIS's effectiveness in gene identification, demonstrating our system's potential to significantly enhance the efficiency and scope of scientific exploration. Our findings represent a solid step towards automating scientific discovery through large language models.
Accelerating PDE Data Generation via Differential Operator Action in Solution Space
Feb 04, 2024Recent advancements in data-driven approaches, such as Neural Operator (NO), have demonstrated their effectiveness in reducing the solving time of Partial Differential Equations (PDEs). However, one major challenge faced by these approaches is the requirement for a large amount of high-precision training data, which needs significant computational costs during the generation process. To address this challenge, we propose a novel PDE dataset generation algorithm, namely Differential Operator Action in Solution space (DiffOAS), which speeds up the data generation process and enhances the precision of the generated data simultaneously. Specifically, DiffOAS obtains a few basic PDE solutions and then combines them to get solutions. It applies differential operators on these solutions, a process we call 'operator action', to efficiently generate precise PDE data points. Theoretical analysis shows that the time complexity of DiffOAS method is one order lower than the existing generation method. Experimental results show that DiffOAS accelerates the generation of large-scale datasets with 10,000 instances by 300 times. Even with just 5% of the generation time, NO trained on the data generated by DiffOAS exhibits comparable performance to that using the existing generation method, which highlights the efficiency of DiffOAS.
Machine Learning Insides OptVerse AI Solver: Design Principles and Applications
Jan 17, 2024In an era of digital ubiquity, efficient resource management and decision-making are paramount across numerous industries. To this end, we present a comprehensive study on the integration of machine learning (ML) techniques into Huawei Cloud's OptVerse AI Solver, which aims to mitigate the scarcity of real-world mathematical programming instances, and to surpass the capabilities of traditional optimization techniques. We showcase our methods for generating complex SAT and MILP instances utilizing generative models that mirror multifaceted structures of real-world problem. Furthermore, we introduce a training framework leveraging augmentation policies to maintain solvers' utility in dynamic environments. Besides the data generation and augmentation, our proposed approaches also include novel ML-driven policies for personalized solver strategies, with an emphasis on applications like graph convolutional networks for initial basis selection and reinforcement learning for advanced presolving and cut selection. Additionally, we detail the incorporation of state-of-the-art parameter tuning algorithms which markedly elevate solver performance. Compared with traditional solvers such as Cplex and SCIP, our ML-augmented OptVerse AI Solver demonstrates superior speed and precision across both established benchmarks and real-world scenarios, reinforcing the practical imperative and effectiveness of machine learning techniques in mathematical programming solvers.
Dataset Distillation via the Wasserstein Metric
Nov 30, 2023Dataset distillation (DD) offers a compelling approach in computer vision, with the goal of condensing extensive datasets into smaller synthetic versions without sacrificing much of the model performance. In this paper, we continue to study the methods for DD, by addressing its conceptually core objective: how to capture the essential representation of extensive datasets in smaller, synthetic forms. We propose a novel approach utilizing the Wasserstein distance, a metric rooted in optimal transport theory, to enhance distribution matching in DD. Our method leverages the Wasserstein barycenter, offering a geometrically meaningful way to quantify distribution differences and effectively capture the centroid of a set of distributions. Our approach retains the computational benefits of distribution matching-based methods while achieving new state-of-the-art performance on several benchmarks. To provide useful prior for learning the images, we embed the synthetic data into the feature space of pretrained classification models to conduct distribution matching. Extensive testing on various high-resolution datasets confirms the effectiveness and adaptability of our method, indicating the promising yet unexplored capabilities of Wasserstein metrics in dataset distillation.
Beyond Pixels: Exploring Human-Readable SVG Generation for Simple Images with Vision Language Models
Nov 27, 2023In the field of computer graphics, the use of vector graphics, particularly Scalable Vector Graphics (SVG), represents a notable development from traditional pixel-based imagery. SVGs, with their XML-based format, are distinct in their ability to directly and explicitly represent visual elements such as shape, color, and path. This direct representation facilitates a more accurate and logical depiction of graphical elements, enhancing reasoning and interpretability. Recognizing the potential of SVGs, the machine learning community has introduced multiple methods for image vectorization. However, transforming images into SVG format while retaining the relational properties and context of the original scene remains a key challenge. Most vectorization methods often yield SVGs that are overly complex and not easily interpretable. In response to this challenge, we introduce our method, Simple-SVG-Generation (S\textsuperscript{2}VG\textsuperscript{2}). Our method focuses on producing SVGs that are both accurate and simple, aligning with human readability and understanding. With simple images, we evaluate our method with reasoning tasks together with advanced language models, the results show a clear improvement over previous SVG generation methods. We also conducted surveys for human evaluation on the readability of our generated SVGs, the results also favor our methods.
Promoting Generalization for Exact Solvers via Adversarial Instance Augmentation
Oct 22, 2023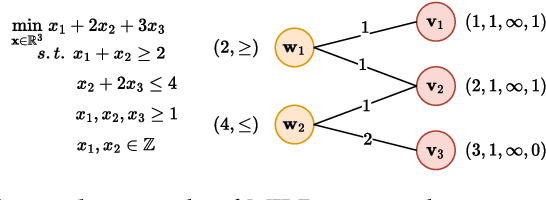
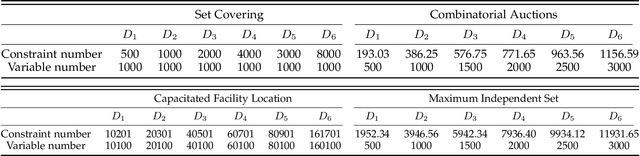
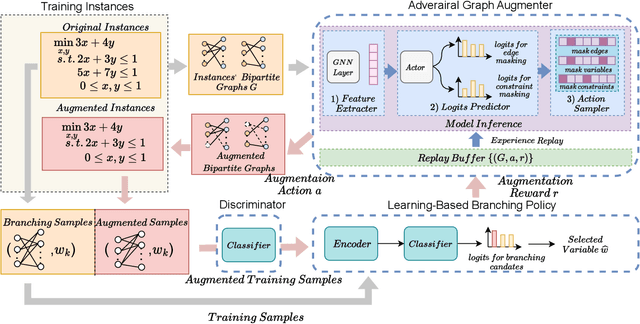
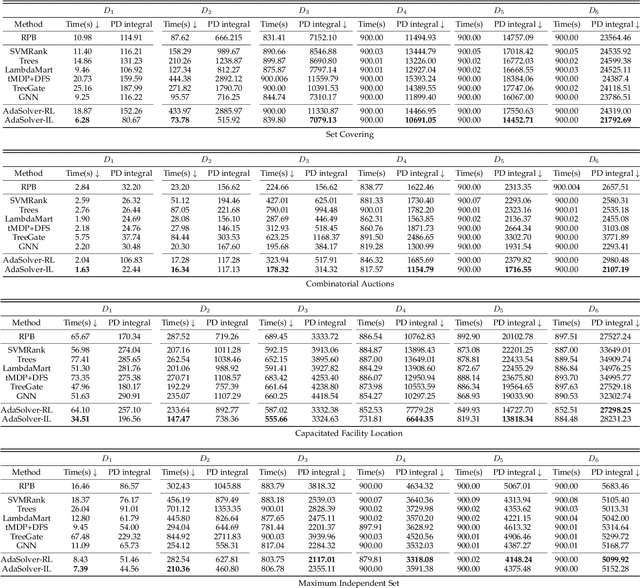
Machine learning has been successfully applied to improve the efficiency of Mixed-Integer Linear Programming (MILP) solvers. However, the learning-based solvers often suffer from severe performance degradation on unseen MILP instances -- especially on large-scale instances from a perturbed environment -- due to the limited diversity of training distributions. To tackle this problem, we propose a novel approach, which is called Adversarial Instance Augmentation and does not require to know the problem type for new instance generation, to promote data diversity for learning-based branching modules in the branch-and-bound (B&B) Solvers (AdaSolver). We use the bipartite graph representations for MILP instances and obtain various perturbed instances to regularize the solver by augmenting the graph structures with a learned augmentation policy. The major technical contribution of AdaSolver is that we formulate the non-differentiable instance augmentation as a contextual bandit problem and adversarially train the learning-based solver and augmentation policy, enabling efficient gradient-based training of the augmentation policy. To the best of our knowledge, AdaSolver is the first general and effective framework for understanding and improving the generalization of both imitation-learning-based (IL-based) and reinforcement-learning-based (RL-based) B&B solvers. Extensive experiments demonstrate that by producing various augmented instances, AdaSolver leads to a remarkable efficiency improvement across various distributions.
QUIZ: An Arbitrary Volumetric Point Matching Method for Medical Image Registration
Sep 30, 2023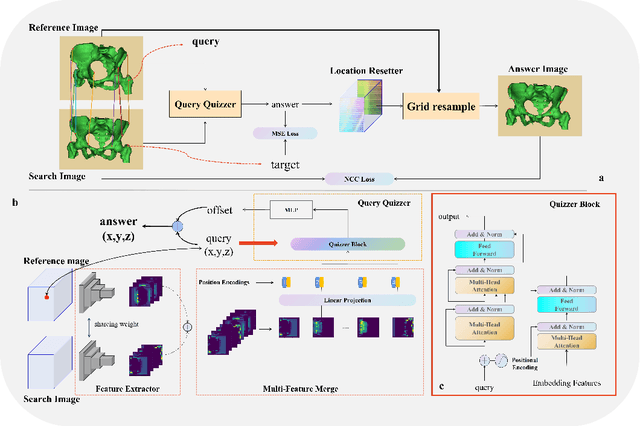
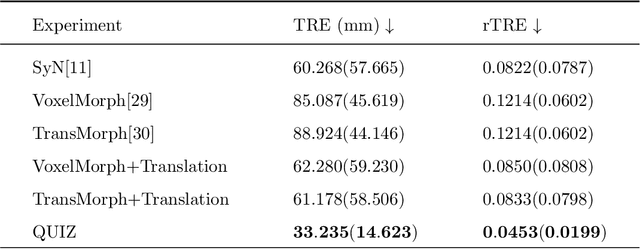
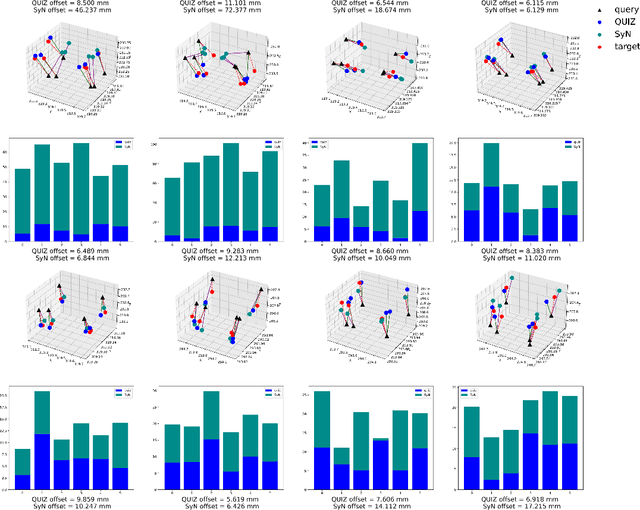
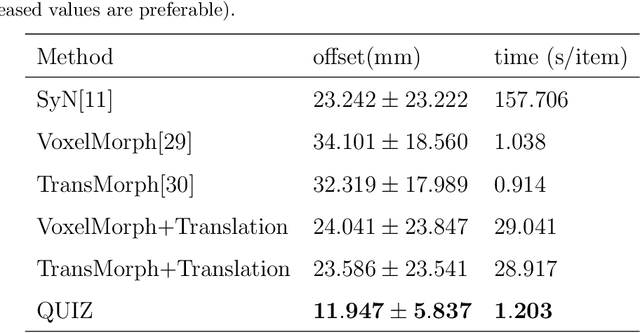
Rigid pre-registration involving local-global matching or other large deformation scenarios is crucial. Current popular methods rely on unsupervised learning based on grayscale similarity, but under circumstances where different poses lead to varying tissue structures, or where image quality is poor, these methods tend to exhibit instability and inaccuracies. In this study, we propose a novel method for medical image registration based on arbitrary voxel point of interest matching, called query point quizzer (QUIZ). QUIZ focuses on the correspondence between local-global matching points, specifically employing CNN for feature extraction and utilizing the Transformer architecture for global point matching queries, followed by applying average displacement for local image rigid transformation. We have validated this approach on a large deformation dataset of cervical cancer patients, with results indicating substantially smaller deviations compared to state-of-the-art methods. Remarkably, even for cross-modality subjects, it achieves results surpassing the current state-of-the-art.
Foundation Model-oriented Robustness: Robust Image Model Evaluation with Pretrained Models
Aug 23, 2023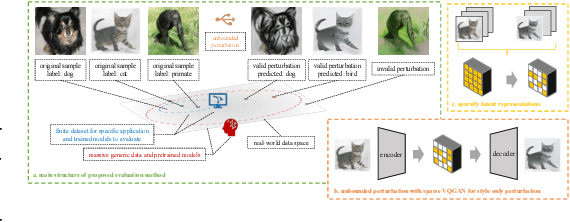
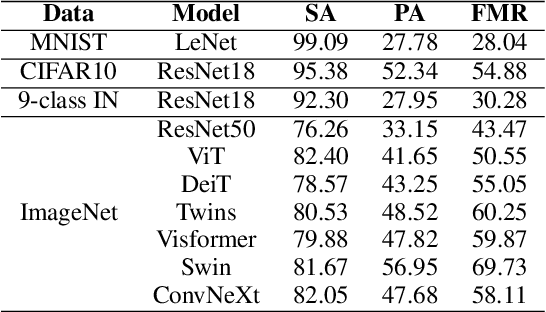
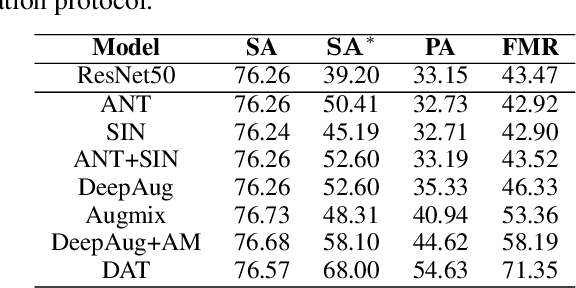

Machine learning has demonstrated remarkable performance over finite datasets, yet whether the scores over the fixed benchmarks can sufficiently indicate the model's performance in the real world is still in discussion. In reality, an ideal robust model will probably behave similarly to the oracle (e.g., the human users), thus a good evaluation protocol is probably to evaluate the models' behaviors in comparison to the oracle. In this paper, we introduce a new robustness measurement that directly measures the image classification model's performance compared with a surrogate oracle (i.e., a foundation model). Besides, we design a simple method that can accomplish the evaluation beyond the scope of the benchmarks. Our method extends the image datasets with new samples that are sufficiently perturbed to be distinct from the ones in the original sets, but are still bounded within the same image-label structure the original test image represents, constrained by a foundation model pretrained with a large amount of samples. As a result, our new method will offer us a new way to evaluate the models' robustness performance, free of limitations of fixed benchmarks or constrained perturbations, although scoped by the power of the oracle. In addition to the evaluation results, we also leverage our generated data to understand the behaviors of the model and our new evaluation strategies.