 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHarin Lee
A Rational Analysis of the Speech-to-Song Illusion
Feb 10, 2024
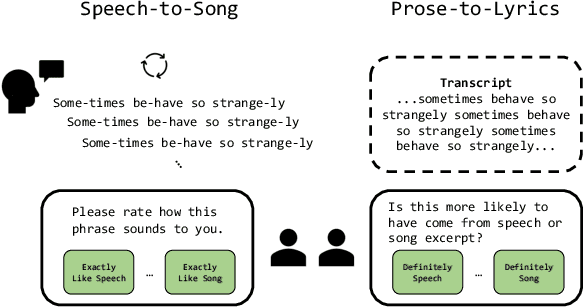
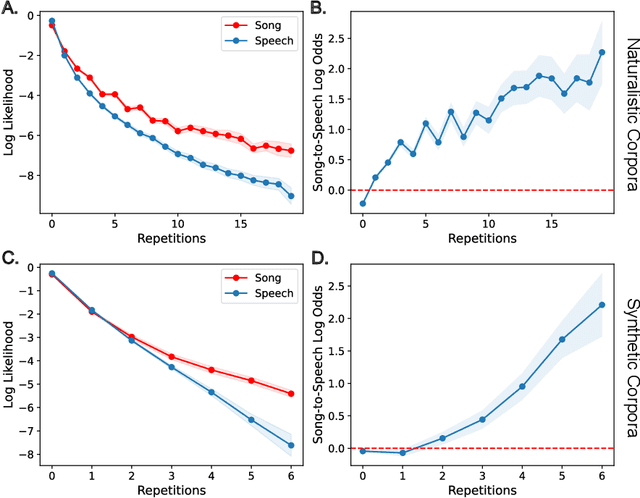

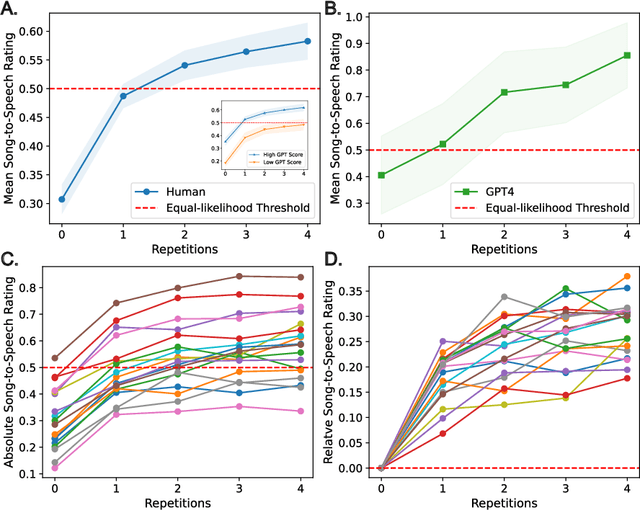
The speech-to-song illusion is a robust psychological phenomenon whereby a spoken sentence sounds increasingly more musical as it is repeated. Despite decades of research, a complete formal account of this transformation is still lacking, and some of its nuanced characteristics, namely, that certain phrases appear to transform while others do not, is not well understood. Here we provide a formal account of this phenomenon, by recasting it as a statistical inference whereby a rational agent attempts to decide whether a sequence of utterances is more likely to have been produced in a song or speech. Using this approach and analyzing song and speech corpora, we further introduce a novel prose-to-lyrics illusion that is purely text-based. In this illusion, simply duplicating written sentences makes them appear more like song lyrics. We provide robust evidence for this new illusion in both human participants and large language models.
Around the world in 60 words: A generative vocabulary test for online research
Feb 03, 2023



Conducting experiments with diverse participants in their native languages can uncover insights into culture, cognition, and language that may not be revealed otherwise. However, conducting these experiments online makes it difficult to validate self-reported language proficiency. Furthermore, existing proficiency tests are small and cover only a few languages. We present an automated pipeline to generate vocabulary tests using text from Wikipedia. Our pipeline samples rare nouns and creates pseudowords with the same low-level statistics. Six behavioral experiments (N=236) in six countries and eight languages show that (a) our test can distinguish between native speakers of closely related languages, (b) the test is reliable ($r=0.82$), and (c) performance strongly correlates with existing tests (LexTale) and self-reports. We further show that test accuracy is negatively correlated with the linguistic distance between the tested and the native language. Our test, available in eight languages, can easily be extended to other languages.
Words are all you need? Capturing human sensory similarity with textual descriptors
Jun 15, 2022



Recent advances in multimodal training use textual descriptions to significantly enhance machine understanding of images and videos. Yet, it remains unclear to what extent language can fully capture sensory experiences across different modalities. A well-established approach for characterizing sensory experiences relies on similarity judgments, namely, the degree to which people perceive two distinct stimuli as similar. We explore the relation between human similarity judgments and language in a series of large-scale behavioral studies ($N=1,823$ participants) across three modalities (images, audio, and video) and two types of text descriptors: simple word tags and free-text captions. In doing so, we introduce a novel adaptive pipeline for tag mining that is both efficient and domain-general. We show that our prediction pipeline based on text descriptors exhibits excellent performance, and we compare it against a comprehensive array of 611 baseline models based on vision-, audio-, and video-processing architectures. We further show that the degree to which textual descriptors and models predict human similarity varies across and within modalities. Taken together, these studies illustrate the value of integrating machine learning and cognitive science approaches to better understand the similarities and differences between human and machine representations. We present an interactive visualization at https://words-are-all-you-need.s3.amazonaws.com/index.html for exploring the similarity between stimuli as experienced by humans and different methods reported in the paper.
Bridging the prosody GAP: Genetic Algorithm with People to efficiently sample emotional prosody
May 10, 2022


The human voice effectively communicates a range of emotions with nuanced variations in acoustics. Existing emotional speech corpora are limited in that they are either (a) highly curated to induce specific emotions with predefined categories that may not capture the full extent of emotional experiences, or (b) entangled in their semantic and prosodic cues, limiting the ability to study these cues separately. To overcome this challenge, we propose a new approach called 'Genetic Algorithm with People' (GAP), which integrates human decision and production into a genetic algorithm. In our design, we allow creators and raters to jointly optimize the emotional prosody over generations. We demonstrate that GAP can efficiently sample from the emotional speech space and capture a broad range of emotions, and show comparable results to state-of-the-art emotional speech corpora. GAP is language-independent and supports large crowd-sourcing, thus can support future large-scale cross-cultural research.
Cross-cultural Mood Perception in Pop Songs and its Alignment with Mood Detection Algorithms
Aug 02, 2021



Do people from different cultural backgrounds perceive the mood in music the same way? How closely do human ratings across different cultures approximate automatic mood detection algorithms that are often trained on corpora of predominantly Western popular music? Analyzing 166 participants responses from Brazil, South Korea, and the US, we examined the similarity between the ratings of nine categories of perceived moods in music and estimated their alignment with four popular mood detection algorithms. We created a dataset of 360 recent pop songs drawn from major music charts of the countries and constructed semantically identical mood descriptors across English, Korean, and Portuguese languages. Multiple participants from the three countries rated their familiarity, preference, and perceived moods for a given song. Ratings were highly similar within and across cultures for basic mood attributes such as sad, cheerful, and energetic. However, we found significant cross-cultural differences for more complex characteristics such as dreamy and love. To our surprise, the results of mood detection algorithms were uniformly correlated across human ratings from all three countries and did not show a detectable bias towards any particular culture. Our study thus suggests that the mood detection algorithms can be considered as an objective measure at least within the popular music context.