 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIlia Sucholutsky
Large language models surpass human experts in predicting neuroscience results
Mar 14, 2024

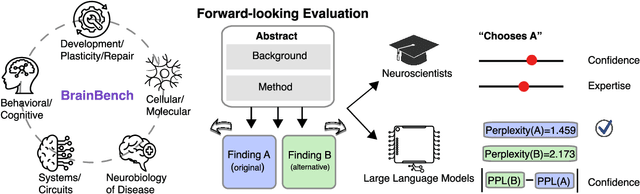
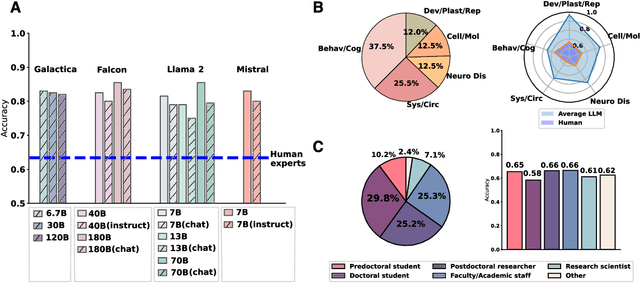
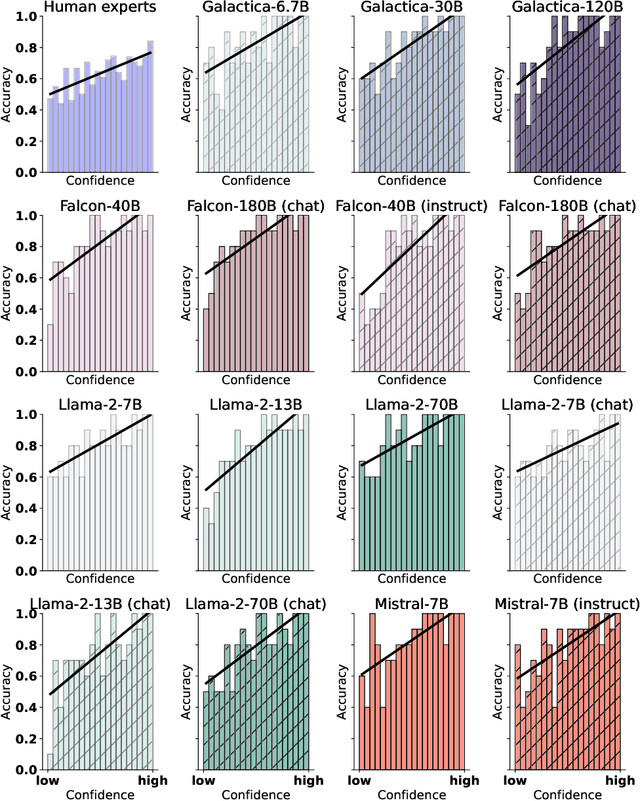
Scientific discoveries often hinge on synthesizing decades of research, a task that potentially outstrips human information processing capacities. Large language models (LLMs) offer a solution. LLMs trained on the vast scientific literature could potentially integrate noisy yet interrelated findings to forecast novel results better than human experts. To evaluate this possibility, we created BrainBench, a forward-looking benchmark for predicting neuroscience results. We find that LLMs surpass experts in predicting experimental outcomes. BrainGPT, an LLM we tuned on the neuroscience literature, performed better yet. Like human experts, when LLMs were confident in their predictions, they were more likely to be correct, which presages a future where humans and LLMs team together to make discoveries. Our approach is not neuroscience-specific and is transferable to other knowledge-intensive endeavors.
Learning with Language-Guided State Abstractions
Mar 06, 2024We describe a framework for using natural language to design state abstractions for imitation learning. Generalizable policy learning in high-dimensional observation spaces is facilitated by well-designed state representations, which can surface important features of an environment and hide irrelevant ones. These state representations are typically manually specified, or derived from other labor-intensive labeling procedures. Our method, LGA (language-guided abstraction), uses a combination of natural language supervision and background knowledge from language models (LMs) to automatically build state representations tailored to unseen tasks. In LGA, a user first provides a (possibly incomplete) description of a target task in natural language; next, a pre-trained LM translates this task description into a state abstraction function that masks out irrelevant features; finally, an imitation policy is trained using a small number of demonstrations and LGA-generated abstract states. Experiments on simulated robotic tasks show that LGA yields state abstractions similar to those designed by humans, but in a fraction of the time, and that these abstractions improve generalization and robustness in the presence of spurious correlations and ambiguous specifications. We illustrate the utility of the learned abstractions on mobile manipulation tasks with a Spot robot.
A Rational Analysis of the Speech-to-Song Illusion
Feb 10, 2024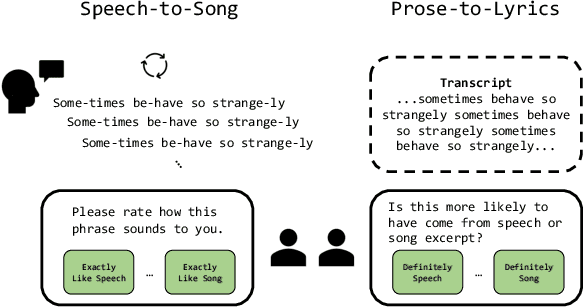
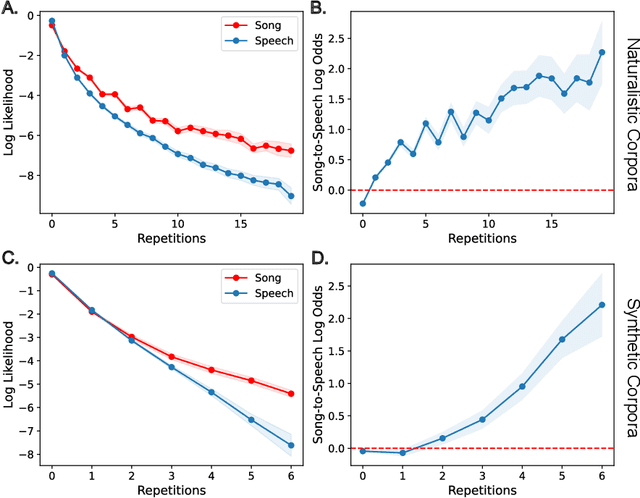

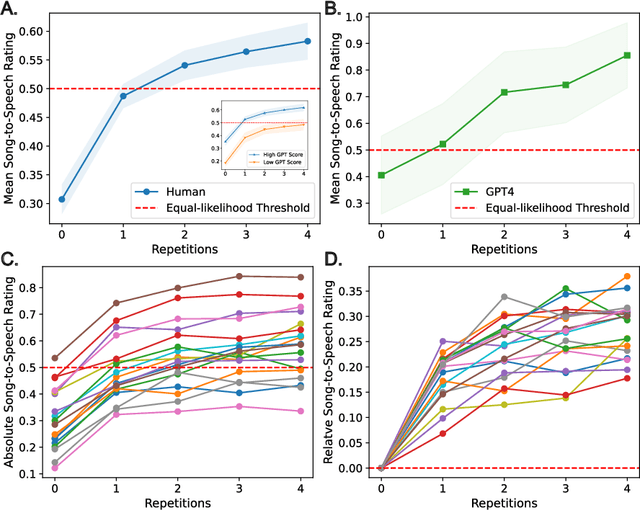
The speech-to-song illusion is a robust psychological phenomenon whereby a spoken sentence sounds increasingly more musical as it is repeated. Despite decades of research, a complete formal account of this transformation is still lacking, and some of its nuanced characteristics, namely, that certain phrases appear to transform while others do not, is not well understood. Here we provide a formal account of this phenomenon, by recasting it as a statistical inference whereby a rational agent attempts to decide whether a sequence of utterances is more likely to have been produced in a song or speech. Using this approach and analyzing song and speech corpora, we further introduce a novel prose-to-lyrics illusion that is purely text-based. In this illusion, simply duplicating written sentences makes them appear more like song lyrics. We provide robust evidence for this new illusion in both human participants and large language models.
Measuring Implicit Bias in Explicitly Unbiased Large Language Models
Feb 06, 2024Large language models (LLMs) can pass explicit bias tests but still harbor implicit biases, similar to humans who endorse egalitarian beliefs yet exhibit subtle biases. Measuring such implicit biases can be a challenge: as LLMs become increasingly proprietary, it may not be possible to access their embeddings and apply existing bias measures; furthermore, implicit biases are primarily a concern if they affect the actual decisions that these systems make. We address both of these challenges by introducing two measures of bias inspired by psychology: LLM Implicit Association Test (IAT) Bias, which is a prompt-based method for revealing implicit bias; and LLM Decision Bias for detecting subtle discrimination in decision-making tasks. Using these measures, we found pervasive human-like stereotype biases in 6 LLMs across 4 social domains (race, gender, religion, health) and 21 categories (weapons, guilt, science, career among others). Our prompt-based measure of implicit bias correlates with embedding-based methods but better predicts downstream behaviors measured by LLM Decision Bias. This measure is based on asking the LLM to decide between individuals, motivated by psychological results indicating that relative not absolute evaluations are more related to implicit biases. Using prompt-based measures informed by psychology allows us to effectively expose nuanced biases and subtle discrimination in proprietary LLMs that do not show explicit bias on standard benchmarks.
Preference-Conditioned Language-Guided Abstraction
Feb 05, 2024Learning from demonstrations is a common way for users to teach robots, but it is prone to spurious feature correlations. Recent work constructs state abstractions, i.e. visual representations containing task-relevant features, from language as a way to perform more generalizable learning. However, these abstractions also depend on a user's preference for what matters in a task, which may be hard to describe or infeasible to exhaustively specify using language alone. How do we construct abstractions to capture these latent preferences? We observe that how humans behave reveals how they see the world. Our key insight is that changes in human behavior inform us that there are differences in preferences for how humans see the world, i.e. their state abstractions. In this work, we propose using language models (LMs) to query for those preferences directly given knowledge that a change in behavior has occurred. In our framework, we use the LM in two ways: first, given a text description of the task and knowledge of behavioral change between states, we query the LM for possible hidden preferences; second, given the most likely preference, we query the LM to construct the state abstraction. In this framework, the LM is also able to ask the human directly when uncertain about its own estimate. We demonstrate our framework's ability to construct effective preference-conditioned abstractions in simulated experiments, a user study, as well as on a real Spot robot performing mobile manipulation tasks.
Concept Alignment
Jan 09, 2024Discussion of AI alignment (alignment between humans and AI systems) has focused on value alignment, broadly referring to creating AI systems that share human values. We argue that before we can even attempt to align values, it is imperative that AI systems and humans align the concepts they use to understand the world. We integrate ideas from philosophy, cognitive science, and deep learning to explain the need for concept alignment, not just value alignment, between humans and machines. We summarize existing accounts of how humans and machines currently learn concepts, and we outline opportunities and challenges in the path towards shared concepts. Finally, we explain how we can leverage the tools already being developed in cognitive science and AI research to accelerate progress towards concept alignment.
Learning Human-like Representations to Enable Learning Human Values
Dec 21, 2023How can we build AI systems that are aligned with human values and objectives in order to avoid causing harm or violating societal standards for acceptable behavior? Making AI systems learn human-like representations of the world has many known benefits, including improving generalization, robustness to domain shifts, and few-shot learning performance, among others. We propose that this kind of representational alignment between machine learning (ML) models and humans is also a necessary condition for value alignment, where ML systems conform to human values and societal norms. We focus on ethics as one aspect of value alignment and train multiple ML agents (support vector regression and kernel regression) in a multi-armed bandit setting, where rewards are sampled from a distribution that reflects the morality of the chosen action. We then study the relationship between each agent's degree of representational alignment with humans and their performance when learning to take the most ethical actions.
Getting aligned on representational alignment
Nov 02, 2023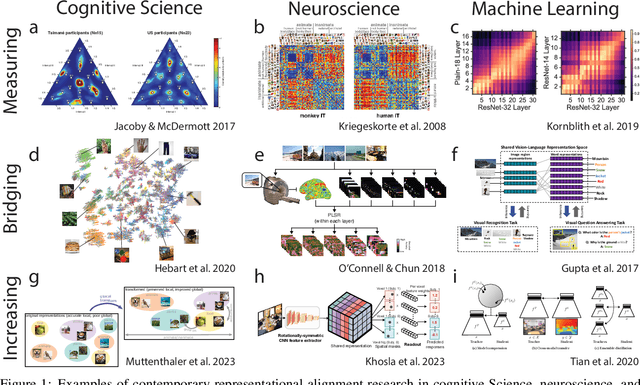
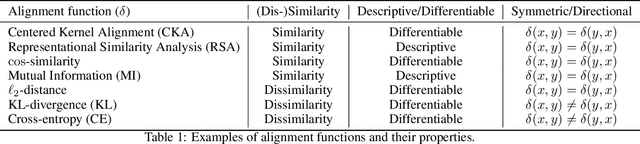
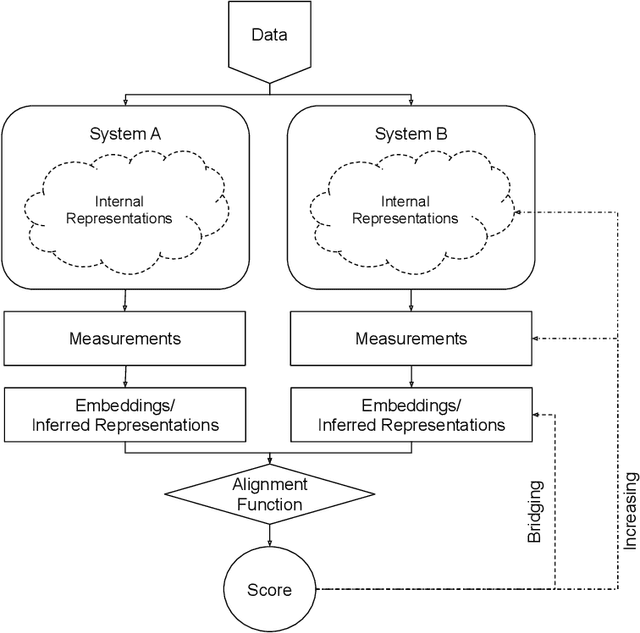
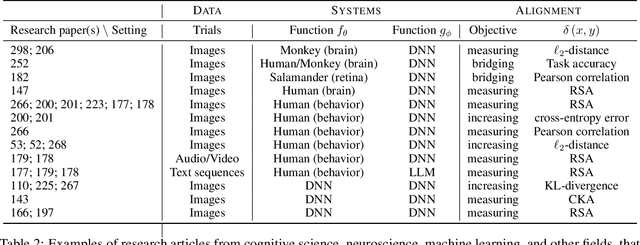
Biological and artificial information processing systems form representations that they can use to categorize, reason, plan, navigate, and make decisions. How can we measure the extent to which the representations formed by these diverse systems agree? Do similarities in representations then translate into similar behavior? How can a system's representations be modified to better match those of another system? These questions pertaining to the study of representational alignment are at the heart of some of the most active research areas in cognitive science, neuroscience, and machine learning. For example, cognitive scientists measure the representational alignment of multiple individuals to identify shared cognitive priors, neuroscientists align fMRI responses from multiple individuals into a shared representational space for group-level analyses, and ML researchers distill knowledge from teacher models into student models by increasing their alignment. Unfortunately, there is limited knowledge transfer between research communities interested in representational alignment, so progress in one field often ends up being rediscovered independently in another. Thus, greater cross-field communication would be advantageous. To improve communication between these fields, we propose a unifying framework that can serve as a common language between researchers studying representational alignment. We survey the literature from all three fields and demonstrate how prior work fits into this framework. Finally, we lay out open problems in representational alignment where progress can benefit all three of these fields. We hope that our work can catalyze cross-disciplinary collaboration and accelerate progress for all communities studying and developing information processing systems. We note that this is a working paper and encourage readers to reach out with their suggestions for future revisions.
Concept Alignment as a Prerequisite for Value Alignment
Oct 30, 2023Value alignment is essential for building AI systems that can safely and reliably interact with people. However, what a person values -- and is even capable of valuing -- depends on the concepts that they are currently using to understand and evaluate what happens in the world. The dependence of values on concepts means that concept alignment is a prerequisite for value alignment -- agents need to align their representation of a situation with that of humans in order to successfully align their values. Here, we formally analyze the concept alignment problem in the inverse reinforcement learning setting, show how neglecting concept alignment can lead to systematic value mis-alignment, and describe an approach that helps minimize such failure modes by jointly reasoning about a person's concepts and values. Additionally, we report experimental results with human participants showing that humans reason about the concepts used by an agent when acting intentionally, in line with our joint reasoning model.
Human Uncertainty in Concept-Based AI Systems
Mar 22, 2023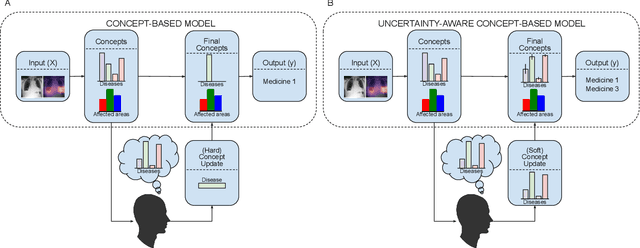
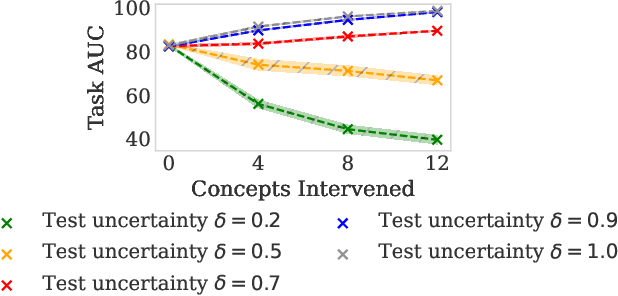
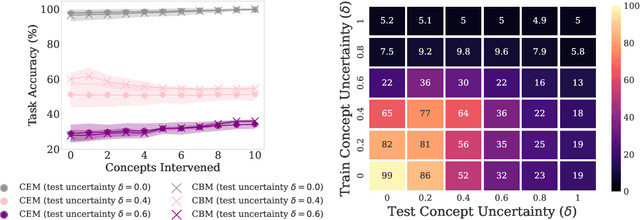
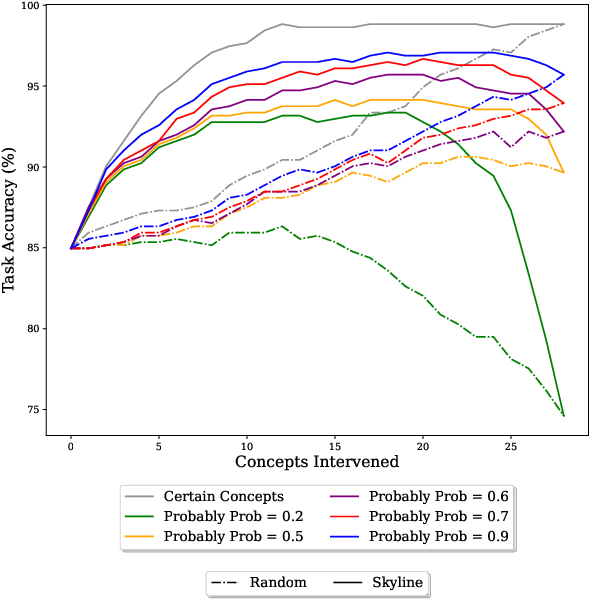
Placing a human in the loop may abate the risks of deploying AI systems in safety-critical settings (e.g., a clinician working with a medical AI system). However, mitigating risks arising from human error and uncertainty within such human-AI interactions is an important and understudied issue. In this work, we study human uncertainty in the context of concept-based models, a family of AI systems that enable human feedback via concept interventions where an expert intervenes on human-interpretable concepts relevant to the task. Prior work in this space often assumes that humans are oracles who are always certain and correct. Yet, real-world decision-making by humans is prone to occasional mistakes and uncertainty. We study how existing concept-based models deal with uncertain interventions from humans using two novel datasets: UMNIST, a visual dataset with controlled simulated uncertainty based on the MNIST dataset, and CUB-S, a relabeling of the popular CUB concept dataset with rich, densely-annotated soft labels from humans. We show that training with uncertain concept labels may help mitigate weaknesses of concept-based systems when handling uncertain interventions. These results allow us to identify several open challenges, which we argue can be tackled through future multidisciplinary research on building interactive uncertainty-aware systems. To facilitate further research, we release a new elicitation platform, UElic, to collect uncertain feedback from humans in collaborative prediction tasks.