 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRui Mata
Large language models surpass human experts in predicting neuroscience results
Mar 14, 2024

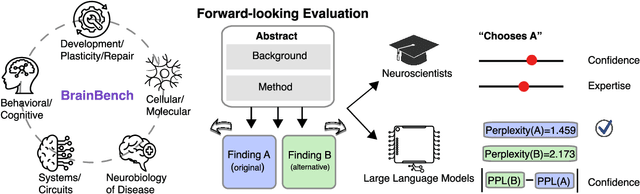
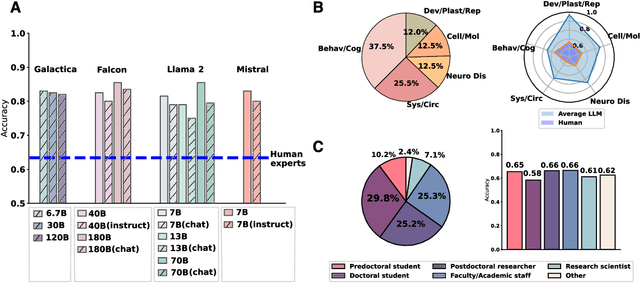
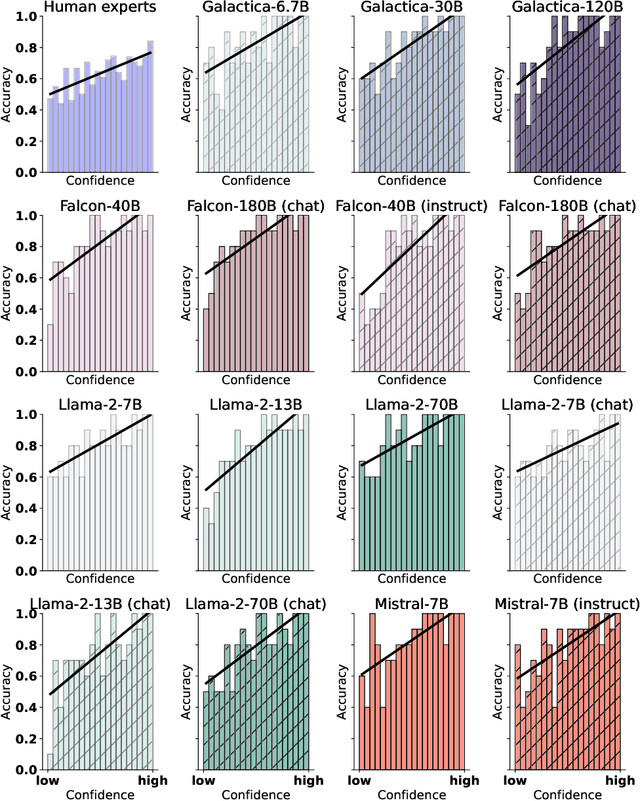
Scientific discoveries often hinge on synthesizing decades of research, a task that potentially outstrips human information processing capacities. Large language models (LLMs) offer a solution. LLMs trained on the vast scientific literature could potentially integrate noisy yet interrelated findings to forecast novel results better than human experts. To evaluate this possibility, we created BrainBench, a forward-looking benchmark for predicting neuroscience results. We find that LLMs surpass experts in predicting experimental outcomes. BrainGPT, an LLM we tuned on the neuroscience literature, performed better yet. Like human experts, when LLMs were confident in their predictions, they were more likely to be correct, which presages a future where humans and LLMs team together to make discoveries. Our approach is not neuroscience-specific and is transferable to other knowledge-intensive endeavors.
Using novel data and ensemble models to improve automated labeling of Sustainable Development Goals
Feb 01, 2023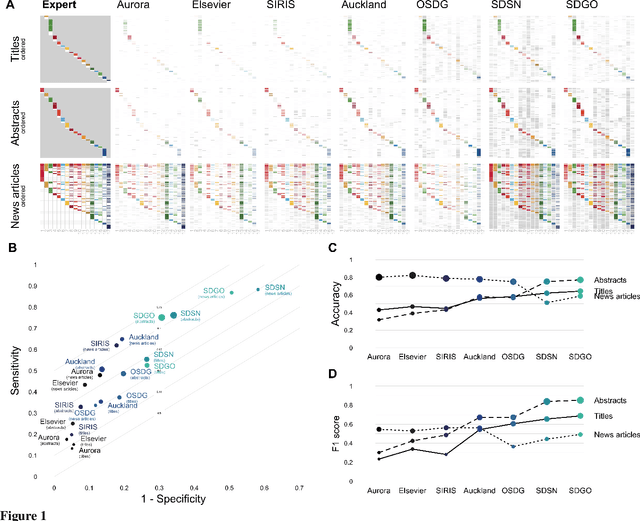
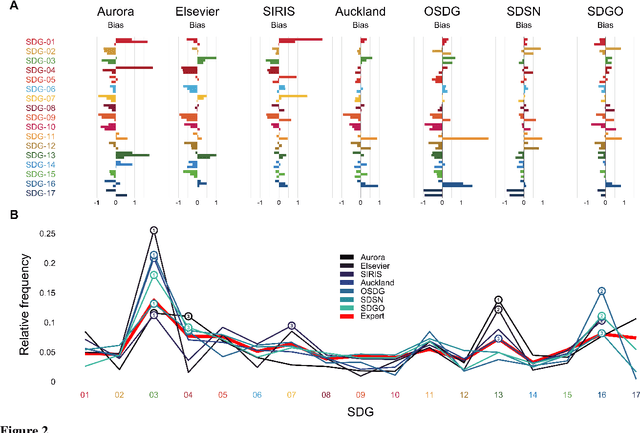
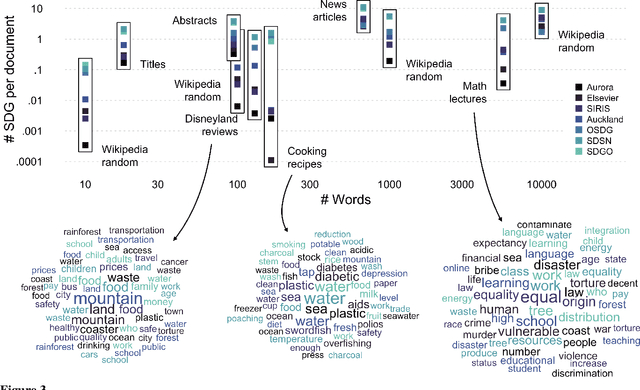
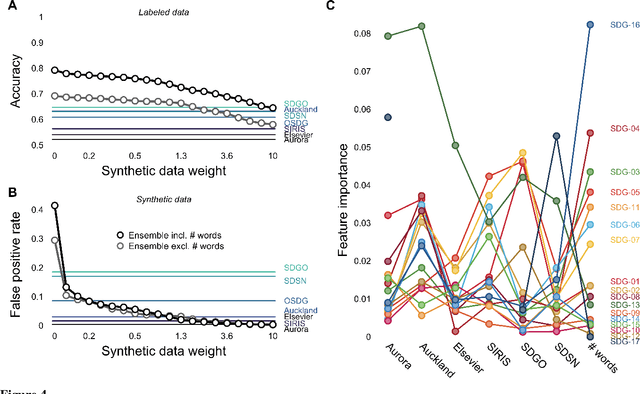
A number of labeling systems based on text have been proposed to help monitor work on the United Nations (UN) Sustainable Development Goals (SDGs). Here, we present a systematic comparison of systems using a variety of text sources and show that systems differ considerably in their specificity (i.e., true-positive rate) and sensitivity (i.e., true-negative rate), have systematic biases (e.g., are more sensitive to specific SDGs relative to others), and are susceptible to the type and amount of text analyzed. We then show that an ensemble model that pools labeling systems alleviates some of these limitations, exceeding the labeling performance of all currently available systems. We conclude that researchers and policymakers should care about the choice of labeling system and that ensemble methods should be favored when drawing conclusions about the absolute and relative prevalence of work on the SDGs based on automated methods.
text2sdg: An open-source solution to monitoring sustainable development goals from text
Oct 20, 2021
Monitoring progress on the United Nations Sustainable Development Goals (SDGs) is important for both academic and non-academic organizations. Existing approaches to monitoring SDGs have focused on specific data types, namely, publications listed in proprietary research databases. We present the text2sdg R package, a user-friendly, open-source package that detects SDGs in any kind of text data using several different query systems from any text source. The text2sdg package thereby facilitates the monitoring of SDGs for a wide array of text sources and provides a much-needed basis for validating and improving extant methods to detect SDGs from text.