 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHeitor R. Guimarães
An Efficient End-to-End Approach to Noise Invariant Speech Features via Multi-Task Learning
Mar 13, 2024

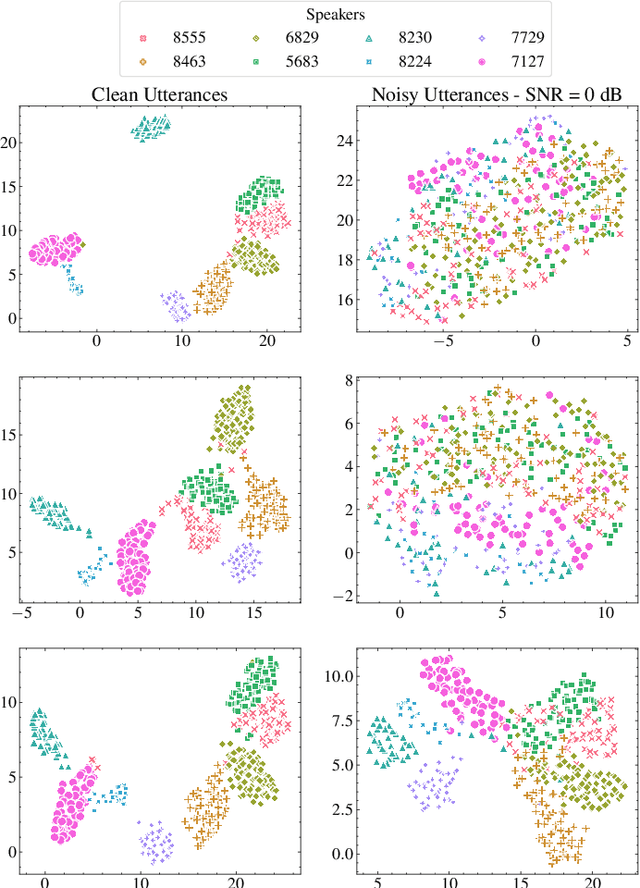


Self-supervised speech representation learning enables the extraction of meaningful features from raw waveforms. These features can then be efficiently used across multiple downstream tasks. However, two significant issues arise when considering the deployment of such methods ``in-the-wild": (i) Their large size, which can be prohibitive for edge applications; and (ii) their robustness to detrimental factors, such as noise and/or reverberation, that can heavily degrade the performance of such systems. In this work, we propose RobustDistiller, a novel knowledge distillation mechanism that tackles both problems jointly. Simultaneously to the distillation recipe, we apply a multi-task learning objective to encourage the network to learn noise-invariant representations by denoising the input. The proposed mechanism is evaluated on twelve different downstream tasks. It outperforms several benchmarks regardless of noise type, or noise and reverberation levels. Experimental results show that the new Student model with 23M parameters can achieve results comparable to the Teacher model with 95M parameters. Lastly, we show that the proposed recipe can be applied to other distillation methodologies, such as the recent DPWavLM. For reproducibility, code and model checkpoints will be made available at \mbox{\url{https://github.com/Hguimaraes/robustdistiller}}.
MSPB: a longitudinal multi-sensor dataset with phenotypic trait measurements from honey bees
Nov 17, 2023We present a longitudinal multi-sensor dataset collected from honey bee colonies (Apis mellifera) with rich phenotypic measurements. Data were continuously collected between May-2020 and April-2021 from 53 hives located at two apiaries in Qu\'ebec, Canada. The sensor data included audio features, temperature, and relative humidity. The phenotypic measurements contained beehive population, number of brood cells (eggs, larva and pupa), Varroa destructor infestation levels, defensive and hygienic behaviors, honey yield, and winter mortality. Our study is amongst the first to provide a wide variety of phenotypic trait measurements annotated by apicultural science experts, which facilitate a broader scope of analysis. We first summarize the data collection procedure, sensor data pre-processing steps, and data composition. We then provide an overview of the phenotypic data distribution as well as a visualization of the sensor data patterns. Lastly, we showcase several hive monitoring applications based on sensor data analysis and machine learning, such as winter mortality prediction, hive population estimation, and the presence of an active and laying queen.
VIC-KD: Variance-Invariance-Covariance Knowledge Distillation to Make Keyword Spotting More Robust Against Adversarial Attacks
Sep 22, 2023



Keyword spotting (KWS) refers to the task of identifying a set of predefined words in audio streams. With the advances seen recently with deep neural networks, it has become a popular technology to activate and control small devices, such as voice assistants. Relying on such models for edge devices, however, can be challenging due to hardware constraints. Moreover, as adversarial attacks have increased against voice-based technologies, developing solutions robust to such attacks has become crucial. In this work, we propose VIC-KD, a robust distillation recipe for model compression and adversarial robustness. Using self-supervised speech representations, we show that imposing geometric priors to the latent representations of both Teacher and Student models leads to more robust target models. Experiments on the Google Speech Commands datasets show that the proposed methodology improves upon current state-of-the-art robust distillation methods, such as ARD and RSLAD, by 12% and 8% in robust accuracy, respectively.
RobustDistiller: Compressing Universal Speech Representations for Enhanced Environment Robustness
Feb 23, 2023



Self-supervised speech pre-training enables deep neural network models to capture meaningful and disentangled factors from raw waveform signals. The learned universal speech representations can then be used across numerous downstream tasks. These representations, however, are sensitive to distribution shifts caused by environmental factors, such as noise and/or room reverberation. Their large sizes, in turn, make them unfeasible for edge applications. In this work, we propose a knowledge distillation methodology termed RobustDistiller which compresses universal representations while making them more robust against environmental artifacts via a multi-task learning objective. The proposed layer-wise distillation recipe is evaluated on top of three well-established universal representations, as well as with three downstream tasks. Experimental results show the proposed methodology applied on top of the WavLM Base+ teacher model outperforming all other benchmarks across noise types and levels, as well as reverberation times. Oftentimes, the obtained results with the student model (24M parameters) achieved results inline with those of the teacher model (95M).
Improving the Robustness of DistilHuBERT to Unseen Noisy Conditions via Data Augmentation, Curriculum Learning, and Multi-Task Enhancement
Nov 12, 2022
Self-supervised speech representation learning aims to extract meaningful factors from the speech signal that can later be used across different downstream tasks, such as speech and/or emotion recognition. Existing models, such as HuBERT, however, can be fairly large thus may not be suitable for edge speech applications. Moreover, realistic applications typically involve speech corrupted by noise and room reverberation, hence models need to provide representations that are robust to such environmental factors. In this study, we build on the so-called DistilHuBERT model, which distils HuBERT to a fraction of its original size, with three modifications, namely: (i) augment the training data with noise and reverberation, while the student model needs to distill the clean representations from the teacher model; (ii) introduce a curriculum learning approach where increasing levels of noise are introduced as the model trains, thus helping with convergence and with the creation of more robust representations; and (iii) introduce a multi-task learning approach where the model also reconstructs the clean waveform jointly with the distillation task, thus also acting as an enhancement step to ensure additional environment robustness to the representation. Experiments on three SUPERB tasks show the advantages of the proposed method not only relative to the original DistilHuBERT, but also to the original HuBERT, thus showing the advantages of the proposed method for ``in the wild'' edge speech applications.