 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYi Zhu
Prompt-tuning for Clickbait Detection via Text Summarization
Apr 17, 2024
Clickbaits are surprising social posts or deceptive news headlines that attempt to lure users for more clicks, which have posted at unprecedented rates for more profit or commercial revenue. The spread of clickbait has significant negative impacts on the users, which brings users misleading or even click-jacking attacks. Different from fake news, the crucial problem in clickbait detection is determining whether the headline matches the corresponding content. Most existing methods compute the semantic similarity between the headlines and contents for detecting clickbait. However, due to significant differences in length and semantic features between headlines and contents, directly calculating semantic similarity is often difficult to summarize the relationship between them. To address this problem, we propose a prompt-tuning method for clickbait detection via text summarization in this paper, text summarization is introduced to summarize the contents, and clickbait detection is performed based on the similarity between the generated summary and the contents. Specifically, we first introduce a two-stage text summarization model to produce high-quality news summaries based on pre-trained language models, and then both the headlines and new generated summaries are incorporated as the inputs for prompt-tuning. Additionally, a variety of strategies are conducted to incorporate external knowledge for improving the performance of clickbait detection. The extensive experiments on well-known clickbait detection datasets demonstrate that our method achieved state-of-the-art performance.
Language-Driven Visual Consensus for Zero-Shot Semantic Segmentation
Mar 13, 2024
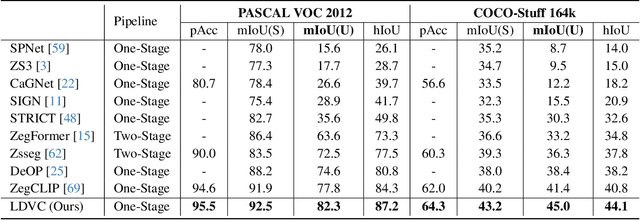
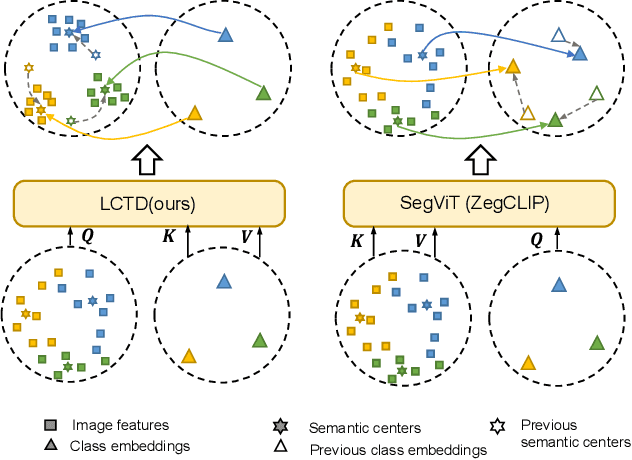
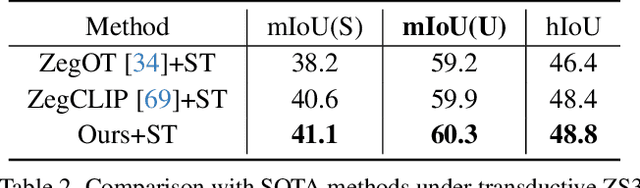
The pre-trained vision-language model, exemplified by CLIP, advances zero-shot semantic segmentation by aligning visual features with class embeddings through a transformer decoder to generate semantic masks. Despite its effectiveness, prevailing methods within this paradigm encounter challenges, including overfitting on seen classes and small fragmentation in masks. To mitigate these issues, we propose a Language-Driven Visual Consensus (LDVC) approach, fostering improved alignment of semantic and visual information.Specifically, we leverage class embeddings as anchors due to their discrete and abstract nature, steering vision features toward class embeddings. Moreover, to circumvent noisy alignments from the vision part due to its redundant nature, we introduce route attention into self-attention for finding visual consensus, thereby enhancing semantic consistency within the same object. Equipped with a vision-language prompting strategy, our approach significantly boosts the generalization capacity of segmentation models for unseen classes. Experimental results underscore the effectiveness of our approach, showcasing mIoU gains of 4.5 on the PASCAL VOC 2012 and 3.6 on the COCO-Stuff 164k for unseen classes compared with the state-of-the-art methods.
Weak Collocation Regression for Inferring Stochastic Dynamics with Lévy Noise
Mar 13, 2024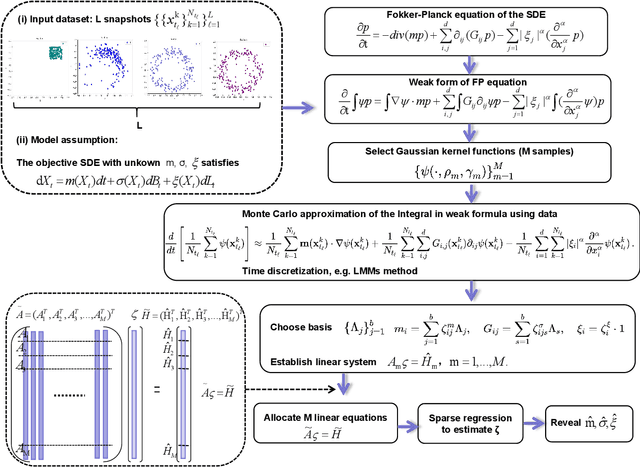
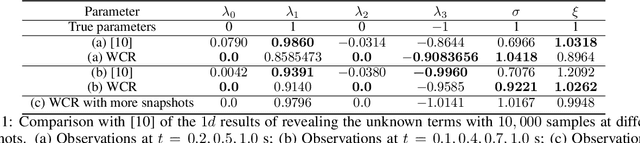
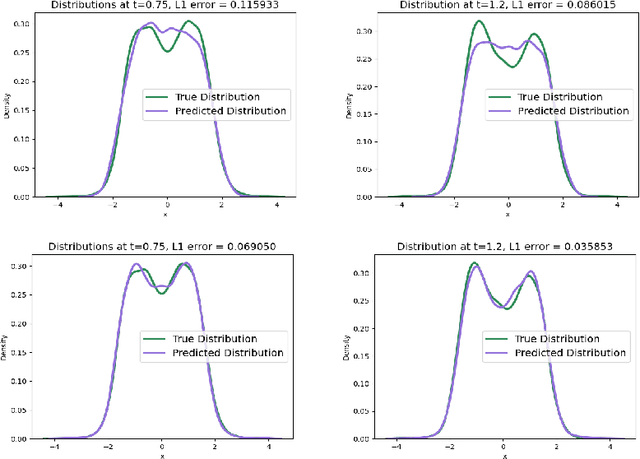

With the rapid increase of observational, experimental and simulated data for stochastic systems, tremendous efforts have been devoted to identifying governing laws underlying the evolution of these systems. Despite the broad applications of non-Gaussian fluctuations in numerous physical phenomena, the data-driven approaches to extracting stochastic dynamics with L\'{e}vy noise are relatively few. In this work, we propose a Weak Collocation Regression (WCR) to explicitly reveal unknown stochastic dynamical systems, i.e., the Stochastic Differential Equation (SDE) with both $\alpha$-stable L\'{e}vy noise and Gaussian noise, from discrete aggregate data. This method utilizes the evolution equation of the probability distribution function, i.e., the Fokker-Planck (FP) equation. With the weak form of the FP equation, the WCR constructs a linear system of unknown parameters where all integrals are evaluated by Monte Carlo method with the observations. Then, the unknown parameters are obtained by a sparse linear regression. For a SDE with L\'{e}vy noise, the corresponding FP equation is a partial integro-differential equation (PIDE), which contains nonlocal terms, and is difficult to deal with. The weak form can avoid complicated multiple integrals. Our approach can simultaneously distinguish mixed noise types, even in multi-dimensional problems. Numerical experiments demonstrate that our method is accurate and computationally efficient.
Towards Deviation-Robust Agent Navigation via Perturbation-Aware Contrastive Learning
Mar 09, 2024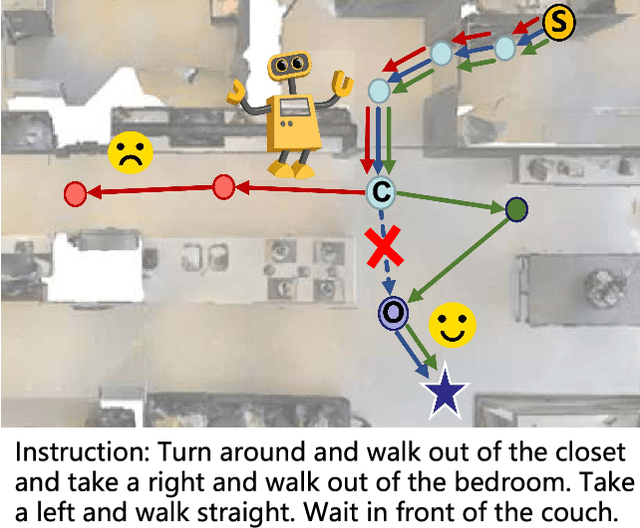
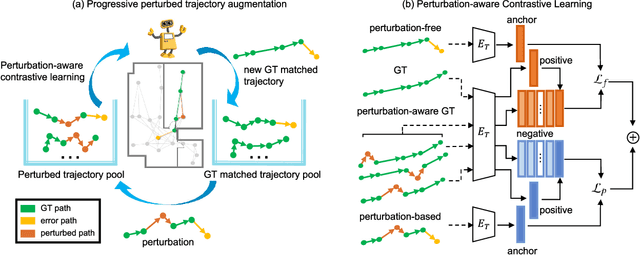
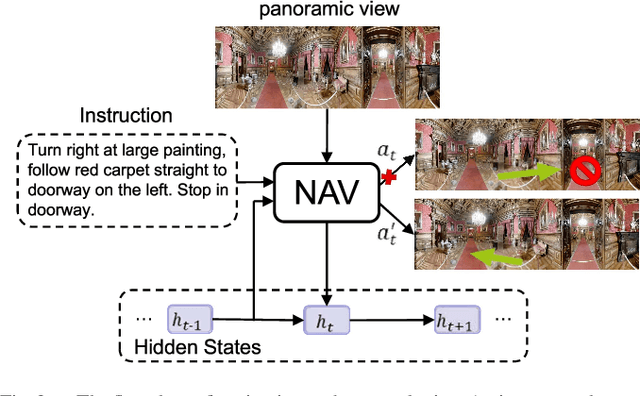
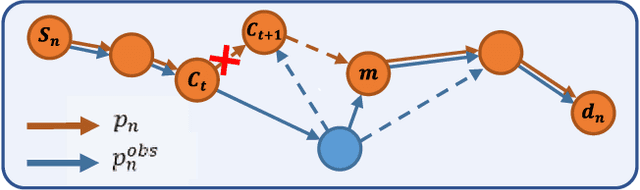
Vision-and-language navigation (VLN) asks an agent to follow a given language instruction to navigate through a real 3D environment. Despite significant advances, conventional VLN agents are trained typically under disturbance-free environments and may easily fail in real-world scenarios, since they are unaware of how to deal with various possible disturbances, such as sudden obstacles or human interruptions, which widely exist and may usually cause an unexpected route deviation. In this paper, we present a model-agnostic training paradigm, called Progressive Perturbation-aware Contrastive Learning (PROPER) to enhance the generalization ability of existing VLN agents, by requiring them to learn towards deviation-robust navigation. Specifically, a simple yet effective path perturbation scheme is introduced to implement the route deviation, with which the agent is required to still navigate successfully following the original instruction. Since directly enforcing the agent to learn perturbed trajectories may lead to inefficient training, a progressively perturbed trajectory augmentation strategy is designed, where the agent can self-adaptively learn to navigate under perturbation with the improvement of its navigation performance for each specific trajectory. For encouraging the agent to well capture the difference brought by perturbation, a perturbation-aware contrastive learning mechanism is further developed by contrasting perturbation-free trajectory encodings and perturbation-based counterparts. Extensive experiments on R2R show that PROPER can benefit multiple VLN baselines in perturbation-free scenarios. We further collect the perturbed path data to construct an introspection subset based on the R2R, called Path-Perturbed R2R (PP-R2R). The results on PP-R2R show unsatisfying robustness of popular VLN agents and the capability of PROPER in improving the navigation robustness.
* Accepted by TPAMI 2023
Efficient Large Language Models: A Survey
Dec 23, 2023Large Language Models (LLMs) have demonstrated remarkable capabilities in important tasks such as natural language understanding, language generation, and complex reasoning and have the potential to make a substantial impact on our society. Such capabilities, however, come with the considerable resources they demand, highlighting the strong need to develop effective techniques for addressing their efficiency challenges. In this survey, we provide a systematic and comprehensive review of efficient LLMs research. We organize the literature in a taxonomy consisting of three main categories, covering distinct yet interconnected efficient LLMs topics from model-centric, data-centric, and framework-centric perspective, respectively. We have also created a GitHub repository where we compile the papers featured in this survey at https://github.com/AIoT-MLSys-Lab/EfficientLLMs, and will actively maintain this repository and incorporate new research as it emerges. We hope our survey can serve as a valuable resource to help researchers and practitioners gain a systematic understanding of the research developments in efficient LLMs and inspire them to contribute to this important and exciting field.
Reconstruction of dynamical systems from data without time labels
Dec 07, 2023In this paper, we study the method to reconstruct dynamical systems from data without time labels. Data without time labels appear in many applications, such as molecular dynamics, single-cell RNA sequencing etc. Reconstruction of dynamical system from time sequence data has been studied extensively. However, these methods do not apply if time labels are unknown. Without time labels, sequence data becomes distribution data. Based on this observation, we propose to treat the data as samples from a probability distribution and try to reconstruct the underlying dynamical system by minimizing the distribution loss, sliced Wasserstein distance more specifically. Extensive experiment results demonstrate the effectiveness of the proposed method.
MSPB: a longitudinal multi-sensor dataset with phenotypic trait measurements from honey bees
Nov 17, 2023We present a longitudinal multi-sensor dataset collected from honey bee colonies (Apis mellifera) with rich phenotypic measurements. Data were continuously collected between May-2020 and April-2021 from 53 hives located at two apiaries in Qu\'ebec, Canada. The sensor data included audio features, temperature, and relative humidity. The phenotypic measurements contained beehive population, number of brood cells (eggs, larva and pupa), Varroa destructor infestation levels, defensive and hygienic behaviors, honey yield, and winter mortality. Our study is amongst the first to provide a wide variety of phenotypic trait measurements annotated by apicultural science experts, which facilitate a broader scope of analysis. We first summarize the data collection procedure, sensor data pre-processing steps, and data composition. We then provide an overview of the phenotypic data distribution as well as a visualization of the sensor data patterns. Lastly, we showcase several hive monitoring applications based on sensor data analysis and machine learning, such as winter mortality prediction, hive population estimation, and the presence of an active and laying queen.
Characterizing the temporal dynamics of universal speech representations for generalizable deepfake detection
Sep 15, 2023Existing deepfake speech detection systems lack generalizability to unseen attacks (i.e., samples generated by generative algorithms not seen during training). Recent studies have explored the use of universal speech representations to tackle this issue and have obtained inspiring results. These works, however, have focused on innovating downstream classifiers while leaving the representation itself untouched. In this study, we argue that characterizing the long-term temporal dynamics of these representations is crucial for generalizability and propose a new method to assess representation dynamics. Indeed, we show that different generative models generate similar representation dynamics patterns with our proposed method. Experiments on the ASVspoof 2019 and 2021 datasets validate the benefits of the proposed method to detect deepfakes from methods unseen during training, significantly improving on several benchmark methods.
Motion-Guided Masking for Spatiotemporal Representation Learning
Aug 24, 2023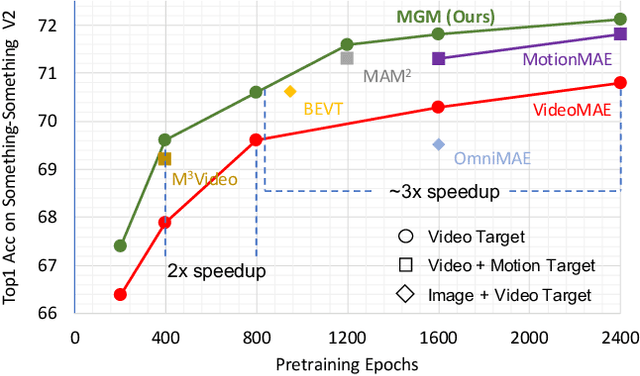
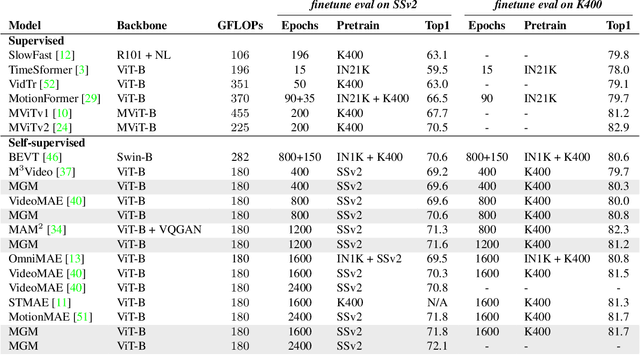
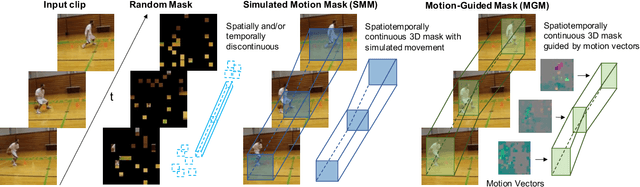
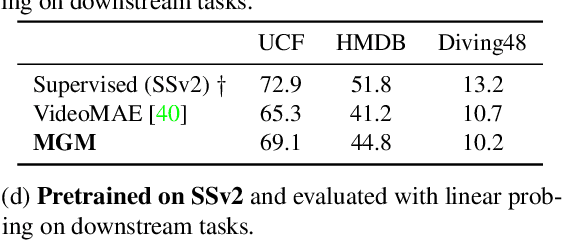
Several recent works have directly extended the image masked autoencoder (MAE) with random masking into video domain, achieving promising results. However, unlike images, both spatial and temporal information are important for video understanding. This suggests that the random masking strategy that is inherited from the image MAE is less effective for video MAE. This motivates the design of a novel masking algorithm that can more efficiently make use of video saliency. Specifically, we propose a motion-guided masking algorithm (MGM) which leverages motion vectors to guide the position of each mask over time. Crucially, these motion-based correspondences can be directly obtained from information stored in the compressed format of the video, which makes our method efficient and scalable. On two challenging large-scale video benchmarks (Kinetics-400 and Something-Something V2), we equip video MAE with our MGM and achieve up to +$1.3\%$ improvement compared to previous state-of-the-art methods. Additionally, our MGM achieves equivalent performance to previous video MAE using up to $66\%$ fewer training epochs. Lastly, we show that MGM generalizes better to downstream transfer learning and domain adaptation tasks on the UCF101, HMDB51, and Diving48 datasets, achieving up to +$4.9\%$ improvement compared to baseline methods.