 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZhongwei Wan
SVD-LLM: Truncation-aware Singular Value Decomposition for Large Language Model Compression
Mar 15, 2024
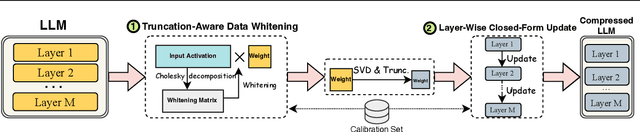
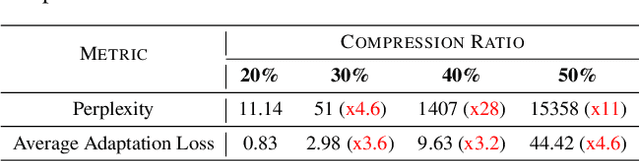
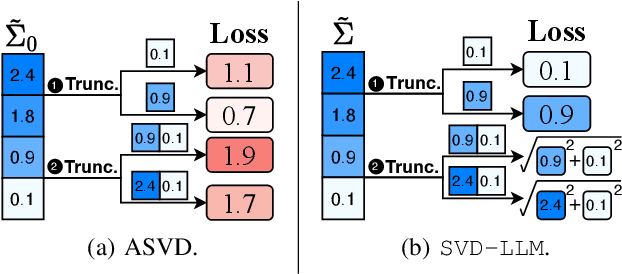

The advancements in Large Language Models (LLMs) have been hindered by their substantial sizes, which necessitate LLM compression methods for practical deployment. Singular Value Decomposition (SVD) offers a promising solution for LLM compression. However, state-of-the-art SVD-based LLM compression methods have two key limitations: truncating smaller singular values may lead to higher compression loss, and the lack of update on the remaining model parameters after SVD truncation. In this work, we propose SVD-LLM, a new SVD-based LLM compression method that addresses the limitations of existing methods. SVD-LLM incorporates a truncation-aware data whitening strategy to ensure a direct mapping between singular values and compression loss. Moreover, SVD-LLM adopts a layer-wise closed-form model parameter update strategy to compensate for accuracy degradation caused by SVD truncation. We evaluate SVD-LLM on a total of 11 datasets and seven models from three different LLM families at four different scales. Our results demonstrate the superiority of SVD-LLM over state-of-the-arts, especially at high model compression ratios. The source code is available at https://github.com/AIoT-MLSys-Lab/SVD-LLM.
Electrocardiogram Instruction Tuning for Report Generation
Mar 13, 2024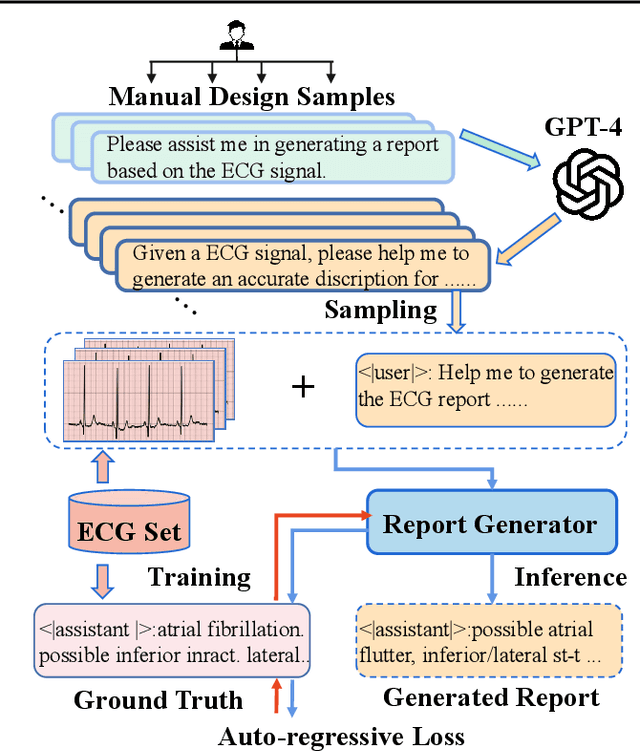
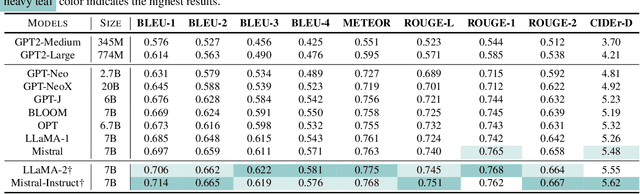
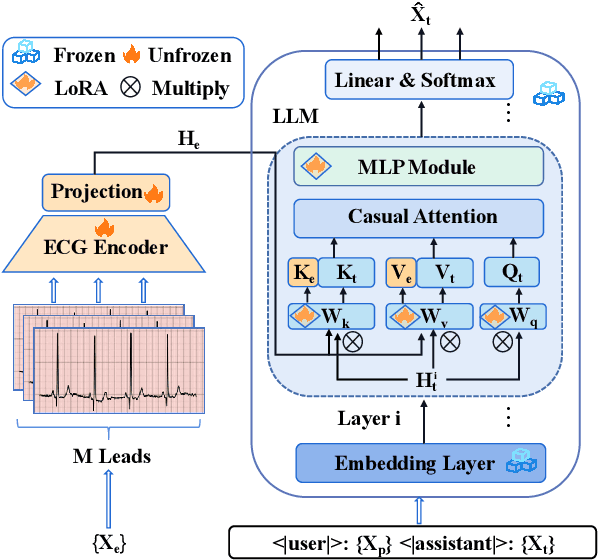
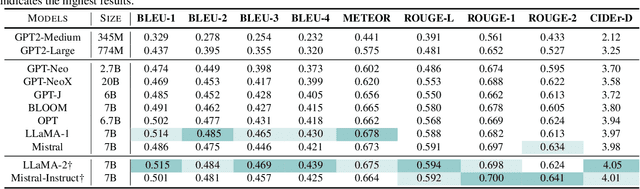
Electrocardiogram (ECG) serves as the primary non-invasive diagnostic tool for cardiac conditions monitoring, are crucial in assisting clinicians. Recent studies have concentrated on classifying cardiac conditions using ECG data but have overlooked ECG report generation, which is not only time-consuming but also requires clinical expertise. To automate ECG report generation and ensure its versatility, we propose the Multimodal ECG Instruction Tuning (MEIT) framework, the \textit{first} attempt to tackle ECG report generation with LLMs and multimodal instructions. To facilitate future research, we establish a benchmark to evaluate MEIT with various LLMs backbones across two large-scale ECG datasets. Our approach uniquely aligns the representations of the ECG signal and the report, and we conduct extensive experiments to benchmark MEIT with nine open source LLMs, using more than 800,000 ECG reports. MEIT's results underscore the superior performance of instruction-tuned LLMs, showcasing their proficiency in quality report generation, zero-shot capabilities, and resilience to signal perturbation. These findings emphasize the efficacy of our MEIT framework and its potential for real-world clinical application.
Zero-Shot ECG Classification with Multimodal Learning and Test-time Clinical Knowledge Enhancement
Mar 11, 2024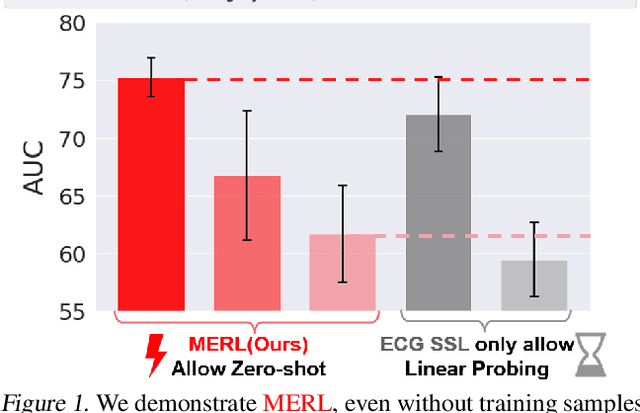

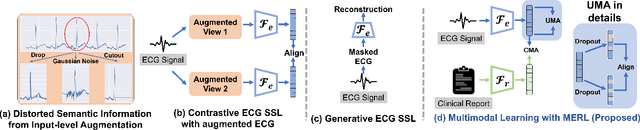
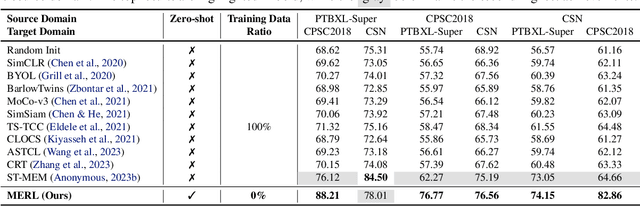
Electrocardiograms (ECGs) are non-invasive diagnostic tools crucial for detecting cardiac arrhythmic diseases in clinical practice. While ECG Self-supervised Learning (eSSL) methods show promise in representation learning from unannotated ECG data, they often overlook the clinical knowledge that can be found in reports. This oversight and the requirement for annotated samples for downstream tasks limit eSSL's versatility. In this work, we address these issues with the Multimodal ECG Representation Learning (MERL}) framework. Through multimodal learning on ECG records and associated reports, MERL is capable of performing zero-shot ECG classification with text prompts, eliminating the need for training data in downstream tasks. At test time, we propose the Clinical Knowledge Enhanced Prompt Engineering (CKEPE) approach, which uses Large Language Models (LLMs) to exploit external expert-verified clinical knowledge databases, generating more descriptive prompts and reducing hallucinations in LLM-generated content to boost zero-shot classification. Based on MERL, we perform the first benchmark across six public ECG datasets, showing the superior performance of MERL compared against eSSL methods. Notably, MERL achieves an average AUC score of 75.2% in zero-shot classification (without training data), 3.2% higher than linear probed eSSL methods with 10\% annotated training data, averaged across all six datasets.
IoT in the Era of Generative AI: Vision and Challenges
Jan 06, 2024Equipped with sensing, networking, and computing capabilities, Internet of Things (IoT) such as smartphones, wearables, smart speakers, and household robots have been seamlessly weaved into our daily lives. Recent advancements in Generative AI exemplified by GPT, LLaMA, DALL-E, and Stable Difussion hold immense promise to push IoT to the next level. In this article, we share our vision and views on the benefits that Generative AI brings to IoT, and discuss some of the most important applications of Generative AI in IoT-related domains. Fully harnessing Generative AI in IoT is a complex challenge. We identify some of the most critical challenges including high resource demands of the Generative AI models, prompt engineering, on-device inference, offloading, on-device fine-tuning, federated learning, security, as well as development tools and benchmarks, and discuss current gaps as well as promising opportunities on enabling Generative AI for IoT. We hope this article can inspire new research on IoT in the era of Generative AI.
Efficient Large Language Models: A Survey
Dec 23, 2023Large Language Models (LLMs) have demonstrated remarkable capabilities in important tasks such as natural language understanding, language generation, and complex reasoning and have the potential to make a substantial impact on our society. Such capabilities, however, come with the considerable resources they demand, highlighting the strong need to develop effective techniques for addressing their efficiency challenges. In this survey, we provide a systematic and comprehensive review of efficient LLMs research. We organize the literature in a taxonomy consisting of three main categories, covering distinct yet interconnected efficient LLMs topics from model-centric, data-centric, and framework-centric perspective, respectively. We have also created a GitHub repository where we compile the papers featured in this survey at https://github.com/AIoT-MLSys-Lab/EfficientLLMs, and will actively maintain this repository and incorporate new research as it emerges. We hope our survey can serve as a valuable resource to help researchers and practitioners gain a systematic understanding of the research developments in efficient LLMs and inspire them to contribute to this important and exciting field.
Text Classification: A Perspective of Deep Learning Methods
Sep 24, 2023

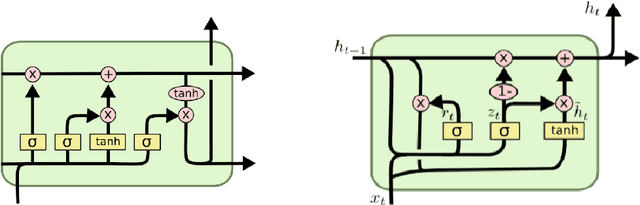
In recent years, with the rapid development of information on the Internet, the number of complex texts and documents has increased exponentially, which requires a deeper understanding of deep learning methods in order to accurately classify texts using deep learning techniques, and thus deep learning methods have become increasingly important in text classification. Text classification is a class of tasks that automatically classifies a set of documents into multiple predefined categories based on their content and subject matter. Thus, the main goal of text classification is to enable users to extract information from textual resources and process processes such as retrieval, classification, and machine learning techniques together in order to classify different categories. Many new techniques of deep learning have already achieved excellent results in natural language processing. The success of these learning algorithms relies on their ability to understand complex models and non-linear relationships in data. However, finding the right structure, architecture, and techniques for text classification is a challenge for researchers. This paper introduces deep learning-based text classification algorithms, including important steps required for text classification tasks such as feature extraction, feature reduction, and evaluation strategies and methods. At the end of the article, different deep learning text classification methods are compared and summarized.
ETP: Learning Transferable ECG Representations via ECG-Text Pre-training
Sep 06, 2023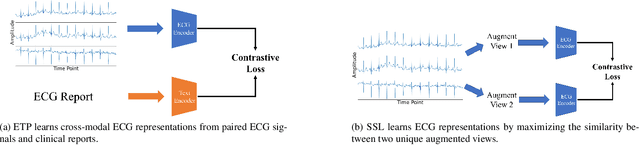
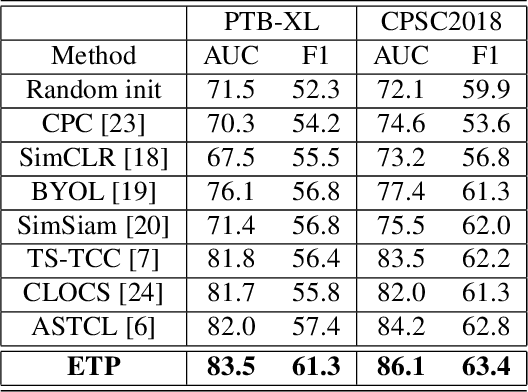
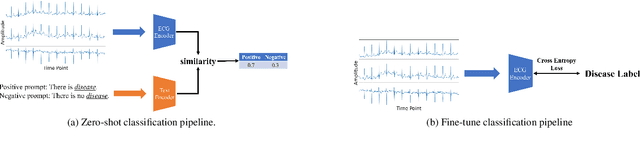
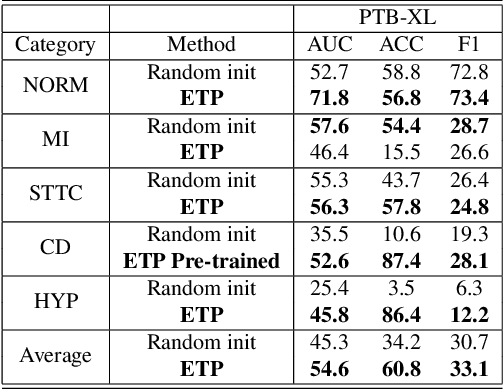
In the domain of cardiovascular healthcare, the Electrocardiogram (ECG) serves as a critical, non-invasive diagnostic tool. Although recent strides in self-supervised learning (SSL) have been promising for ECG representation learning, these techniques often require annotated samples and struggle with classes not present in the fine-tuning stages. To address these limitations, we introduce ECG-Text Pre-training (ETP), an innovative framework designed to learn cross-modal representations that link ECG signals with textual reports. For the first time, this framework leverages the zero-shot classification task in the ECG domain. ETP employs an ECG encoder along with a pre-trained language model to align ECG signals with their corresponding textual reports. The proposed framework excels in both linear evaluation and zero-shot classification tasks, as demonstrated on the PTB-XL and CPSC2018 datasets, showcasing its ability for robust and generalizable cross-modal ECG feature learning.
Med-UniC: Unifying Cross-Lingual Medical Vision-Language Pre-Training by Diminishing Bias
May 31, 2023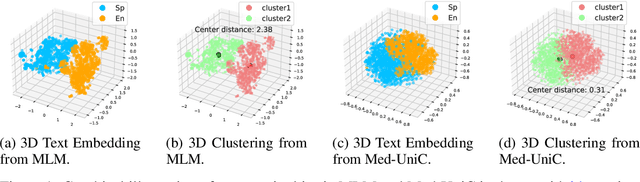
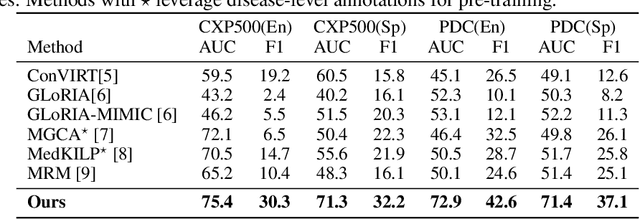

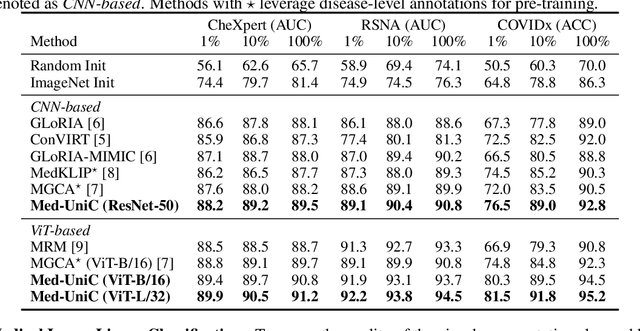
The scarcity of data presents a critical obstacle to the efficacy of medical visionlanguage pre-training (VLP). A potential solution lies in the combination of datasets from various language communities. Nevertheless, the main challenge stems from the complexity of integrating diverse syntax and semantics, language-specific medical terminology, and culture-specific implicit knowledge. Therefore, one crucial aspect to consider is the presence of community bias caused by different languages. This paper presents a novel framework named Unifying Cross-Lingual Medical Vision-Language Pre-Training (Med-UniC), designed to integrate multimodal medical data from the two most prevalent languages, English and Spanish. Specifically, we propose Cross-lingual Text Alignment Regularization (CTR) to explicitly unify cross-lingual semantic representations of medical reports originating from diverse language communities. CTR is optimized through latent language disentanglement, rendering our optimization objective to not depend on negative samples, thereby significantly mitigating the bias from determining positive-negative sample pairs within analogous medical reports. Furthermore, it ensures that the cross-lingual representation is not biased toward any specific language community. Med-UniC reaches superior performance across 5 medical image tasks and 10 datasets encompassing over 30 diseases, offering a versatile framework for unifying multi-modal medical data within diverse linguistic communities. The experimental outcomes highlight the presence of community bias in cross-lingual VLP. Reducing this bias enhances the performance not only in vision-language tasks but also in uni-modal visual tasks.
G-MAP: General Memory-Augmented Pre-trained Language Model for Domain Tasks
Dec 08, 2022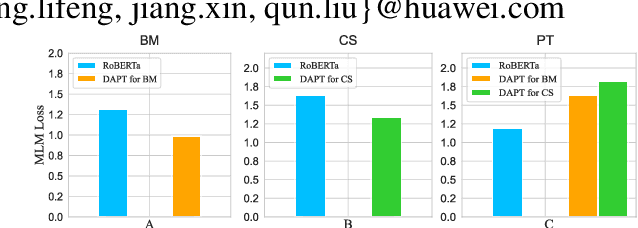

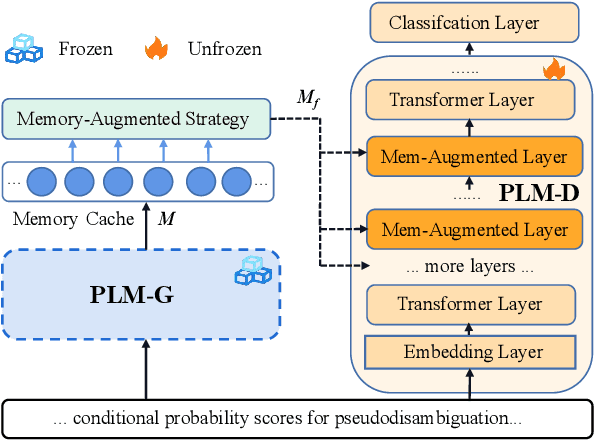

Recently, domain-specific PLMs have been proposed to boost the task performance of specific domains (e.g., biomedical and computer science) by continuing to pre-train general PLMs with domain-specific corpora. However, this Domain-Adaptive Pre-Training (DAPT; Gururangan et al. (2020)) tends to forget the previous general knowledge acquired by general PLMs, which leads to a catastrophic forgetting phenomenon and sub-optimal performance. To alleviate this problem, we propose a new framework of General Memory Augmented Pre-trained Language Model (G-MAP), which augments the domain-specific PLM by a memory representation built from the frozen general PLM without losing any general knowledge. Specifically, we propose a new memory-augmented layer, and based on it, different augmented strategies are explored to build the memory representation and then adaptively fuse it into the domain-specific PLM. We demonstrate the effectiveness of G-MAP on various domains (biomedical and computer science publications, news, and reviews) and different kinds (text classification, QA, NER) of tasks, and the extensive results show that the proposed G-MAP can achieve SOTA results on all tasks.
Self-consistent Reasoning For Solving Math Word Problems
Oct 27, 2022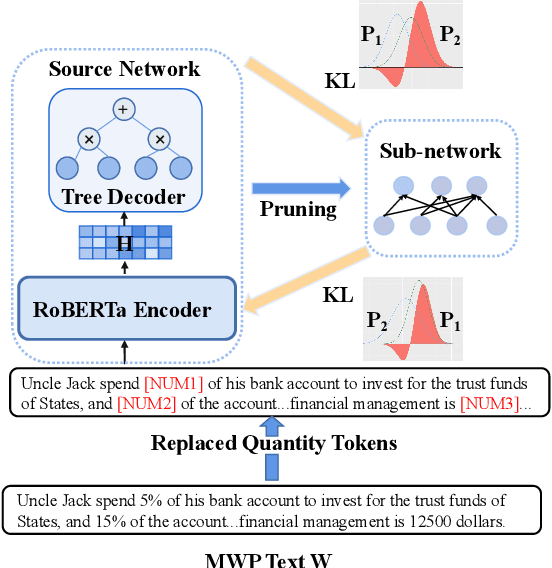
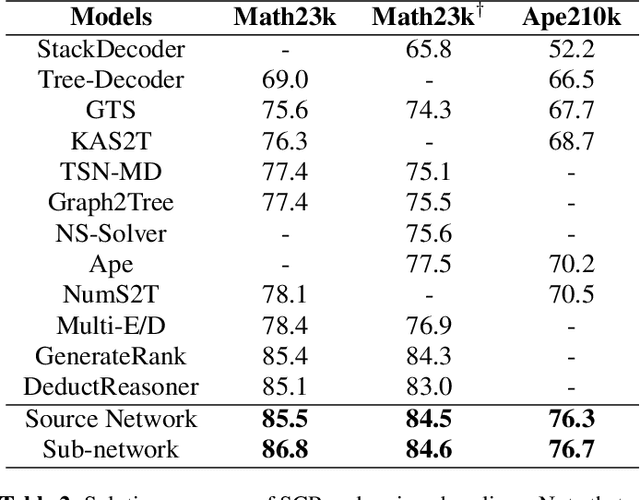
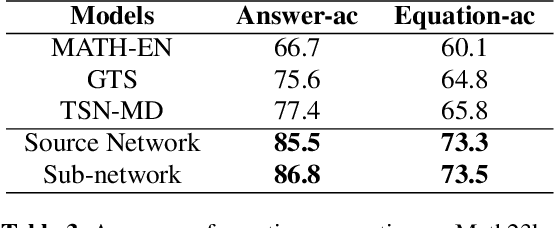

Math word problems (MWPs) is a task that automatically derives solution expression from a giving math problems in text. The previous studies suffer from spurious correlations between input text and output expression. To mitigate this issue, we propose a self-consistent reasoning framework called SCR, which attempts to adopt a pruning strategy to correct the output distribution shift so as to implicitly fix those spurious correlative samples. Specifically, we firstly obtain a sub-network by pruning a roberta2tree model, for the sake to use the gap on output distribution between the original roberta2tree model and the pruned sub-network to expose spurious correlative samples. Then, we calibrate the output distribution shift by applying symmetric Kullback-Leibler divergence to alleviate spurious correlations. In addition, SCR generates equivalent expressions, thereby, capturing the original text's logic rather than relying on hints from original text. Extensive experiments on two large-scale benchmarks demonstrate that our model substantially outperforms the strong baseline methods.