 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHejia Zhang
Multi-Robot Geometric Task-and-Motion Planning for Collaborative Manipulation Tasks
Oct 13, 2023
We address multi-robot geometric task-and-motion planning (MR-GTAMP) problems in synchronous, monotone setups. The goal of the MR-GTAMP problem is to move objects with multiple robots to goal regions in the presence of other movable objects. We focus on collaborative manipulation tasks where the robots have to adopt intelligent collaboration strategies to be successful and effective, i.e., decide which robot should move which objects to which positions, and perform collaborative actions, such as handovers. To endow robots with these collaboration capabilities, we propose to first collect occlusion and reachability information for each robot by calling motion-planning algorithms. We then propose a method that uses the collected information to build a graph structure which captures the precedence of the manipulations of different objects and supports the implementation of a mixed-integer program to guide the search for highly effective collaborative task-and-motion plans. The search process for collaborative task-and-motion plans is based on a Monte-Carlo Tree Search (MCTS) exploration strategy to achieve exploration-exploitation balance. We evaluate our framework in two challenging MR-GTAMP domains and show that it outperforms two state-of-the-art baselines with respect to the planning time, the resulting plan length and the number of objects moved. We also show that our framework can be applied to underground mining operations where a robotic arm needs to coordinate with an autonomous roof bolter. We demonstrate plan execution in two roof-bolting scenarios both in simulation and on robots.
Effective Long-Context Scaling of Foundation Models
Sep 27, 2023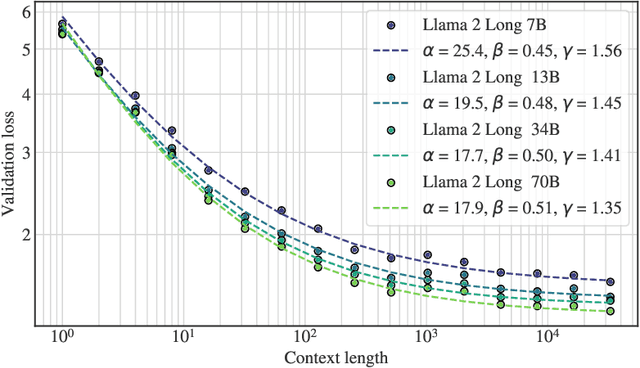
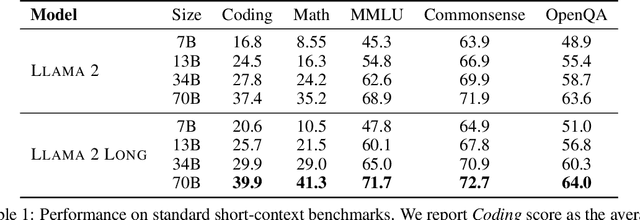

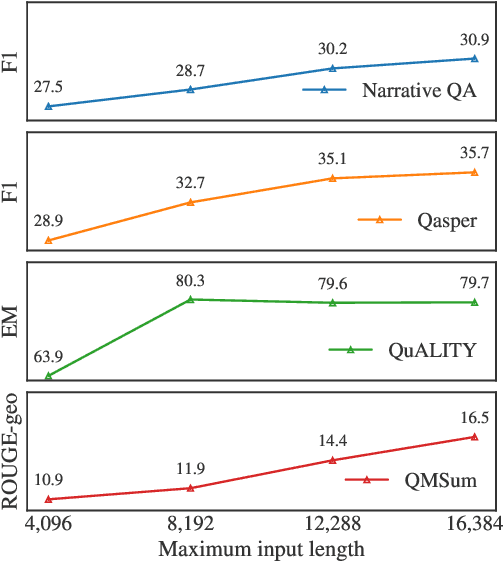
We present a series of long-context LLMs that support effective context windows of up to 32,768 tokens. Our model series are built through continual pretraining from Llama 2 with longer training sequences and on a dataset where long texts are upsampled. We perform extensive evaluation on language modeling, synthetic context probing tasks, and a wide range of research benchmarks. On research benchmarks, our models achieve consistent improvements on most regular tasks and significant improvements on long-context tasks over Llama 2. Notably, with a cost-effective instruction tuning procedure that does not require human-annotated long instruction data, the 70B variant can already surpass gpt-3.5-turbo-16k's overall performance on a suite of long-context tasks. Alongside these results, we provide an in-depth analysis on the individual components of our method. We delve into Llama's position encodings and discuss its limitation in modeling long dependencies. We also examine the impact of various design choices in the pretraining process, including the data mix and the training curriculum of sequence lengths -- our ablation experiments suggest that having abundant long texts in the pretrain dataset is not the key to achieving strong performance, and we empirically verify that long context continual pretraining is more efficient and similarly effective compared to pretraining from scratch with long sequences.
Surrogate Assisted Generation of Human-Robot Interaction Scenarios
May 11, 2023
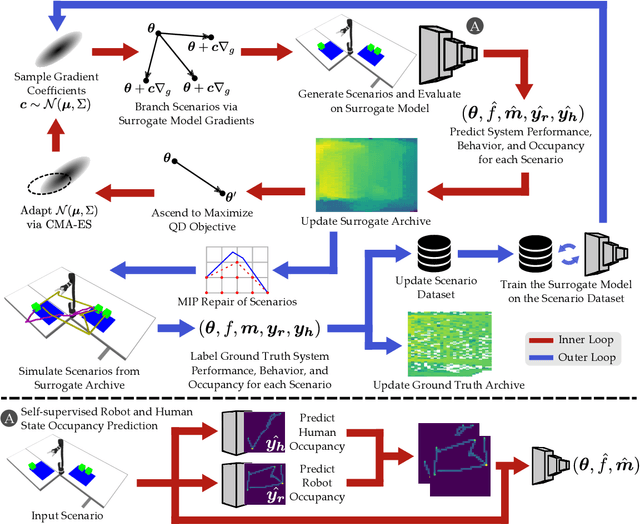
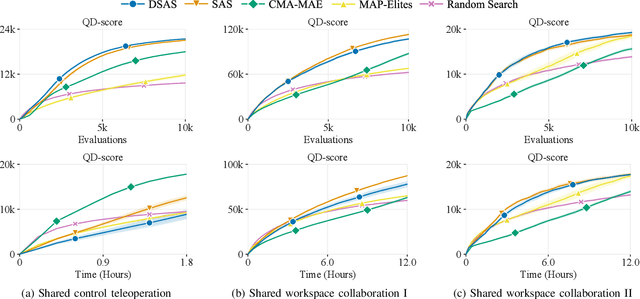
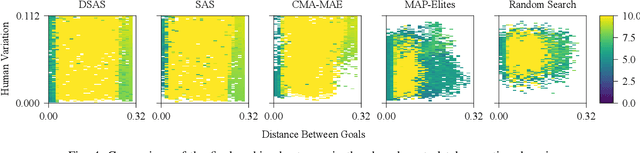
As human-robot interaction (HRI) systems advance, so does the difficulty of evaluating and understanding the strengths and limitations of these systems in different environments and with different users. To this end, previous methods have algorithmically generated diverse scenarios that reveal system failures in a shared control teleoperation task. However, these methods require directly evaluating generated scenarios by simulating robot policies and human actions. The computational cost of these evaluations limits their applicability in more complex domains. Thus, we propose augmenting scenario generation systems with surrogate models that predict both human and robot behaviors. In the shared control teleoperation domain and a more complex shared workspace collaboration task, we show that surrogate assisted scenario generation efficiently synthesizes diverse datasets of challenging scenarios. We demonstrate that these failures are reproducible in real-world interactions.
PATO: Policy Assisted TeleOperation for Scalable Robot Data Collection
Dec 09, 2022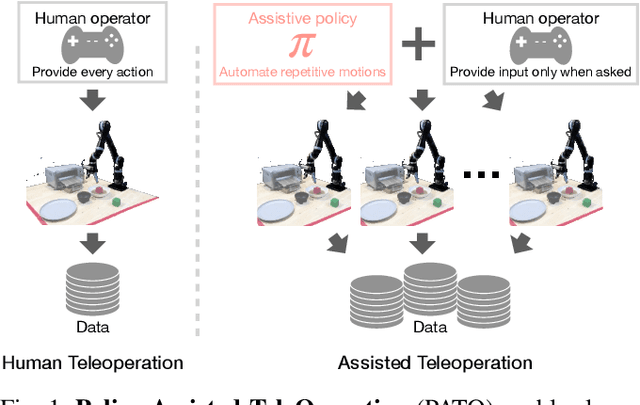

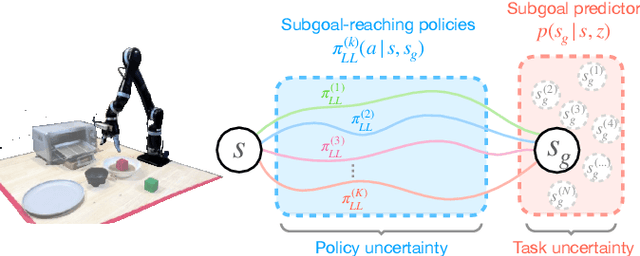
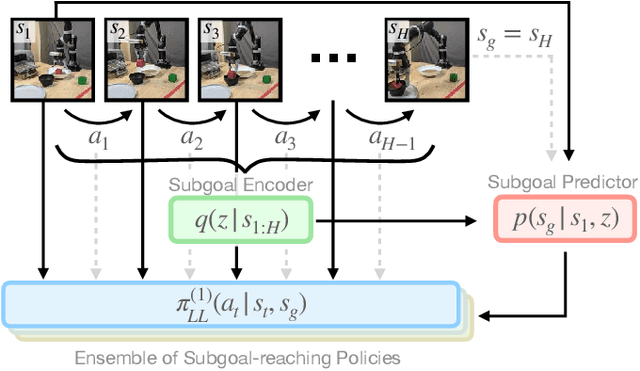
Large-scale data is an essential component of machine learning as demonstrated in recent advances in natural language processing and computer vision research. However, collecting large-scale robotic data is much more expensive and slower as each operator can control only a single robot at a time. To make this costly data collection process efficient and scalable, we propose Policy Assisted TeleOperation (PATO), a system which automates part of the demonstration collection process using a learned assistive policy. PATO autonomously executes repetitive behaviors in data collection and asks for human input only when it is uncertain about which subtask or behavior to execute. We conduct teleoperation user studies both with a real robot and a simulated robot fleet and demonstrate that our assisted teleoperation system reduces human operators' mental load while improving data collection efficiency. Further, it enables a single operator to control multiple robots in parallel, which is a first step towards scalable robotic data collection. For code and video results, see https://clvrai.com/pato
Video Game Level Repair via Mixed Integer Linear Programming
Oct 13, 2020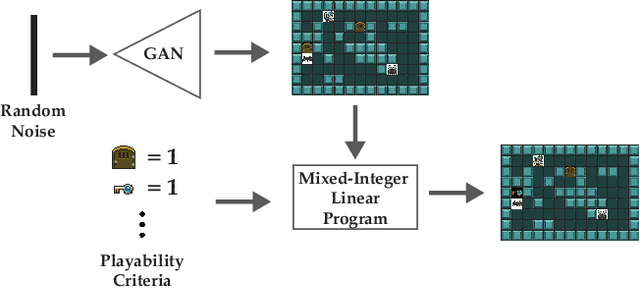


Recent advancements in procedural content generation via machine learning enable the generation of video-game levels that are aesthetically similar to human-authored examples. However, the generated levels are often unplayable without additional editing. We propose a generate-then-repair framework for automatic generation of playable levels adhering to specific styles. The framework constructs levels using a generative adversarial network (GAN) trained with human-authored examples and repairs them using a mixed-integer linear program (MIP) with playability constraints. A key component of the framework is computing minimum cost edits between the GAN generated level and the solution of the MIP solver, which we cast as a minimum cost network flow problem. Results show that the proposed framework generates a diverse range of playable levels, that capture the spatial relationships between objects exhibited in the human-authored levels.
Incorporating structured assumptions with probabilistic graphical models in fMRI data analysis
May 29, 2020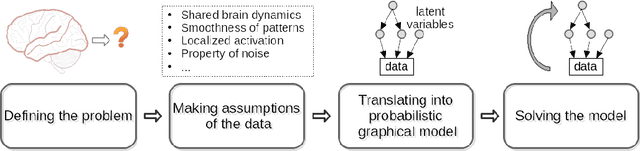

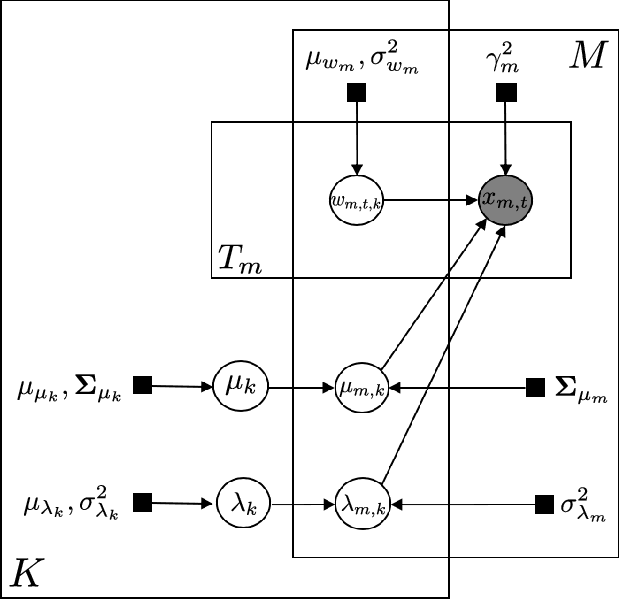
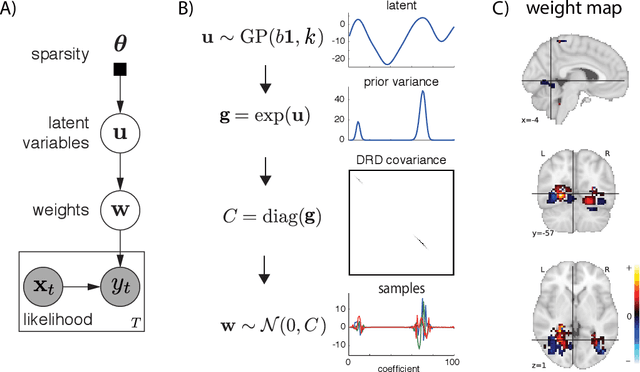
With the wide adoption of functional magnetic resonance imaging (fMRI) by cognitive neuroscience researchers, large volumes of brain imaging data have been accumulated in recent years. Aggregating these data to derive scientific insights often faces the challenge that fMRI data are high-dimensional, heterogeneous across people, and noisy. These challenges demand the development of computational tools that are tailored both for the neuroscience questions and for the properties of the data. We review a few recently developed algorithms in various domains of fMRI research: fMRI in naturalistic tasks, analyzing full-brain functional connectivity, pattern classification, inferring representational similarity and modeling structured residuals. These algorithms all tackle the challenges in fMRI similarly: they start by making clear statements of assumptions about neural data and existing domain knowledge, incorporating those assumptions and domain knowledge into probabilistic graphical models, and using those models to estimate properties of interest or latent structures in the data. Such approaches can avoid erroneous findings, reduce the impact of noise, better utilize known properties of the data, and better aggregate data across groups of subjects. With these successful cases, we advocate wider adoption of explicit model construction in cognitive neuroscience. Although we focus on fMRI, the principle illustrated here is generally applicable to brain data of other modalities.
* update with the version accepted by Neuropsychologia
Robot Learning and Execution of Collaborative Manipulation Plans from YouTube Videos
Dec 22, 2019
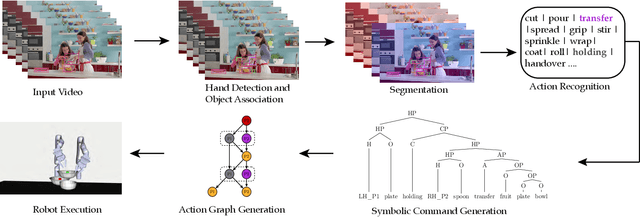
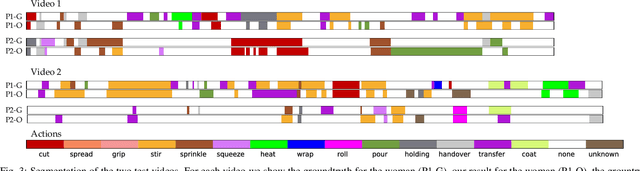
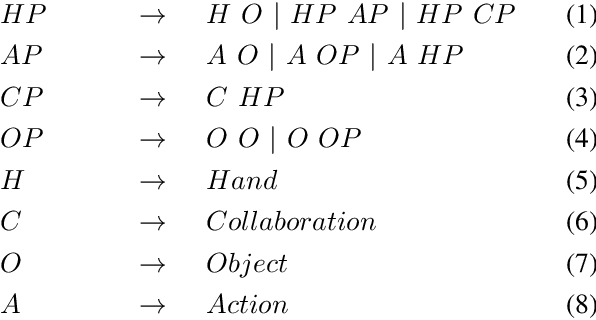
People often watch videos on the web to learn how to cook new recipes, assemble furniture or repair a computer. We wish to enable robots with the very same capability. This is challenging; there is a large variation in manipulation actions and some videos even involve multiple persons, who collaborate by sharing and exchanging objects and tools. Furthermore, the learned representations need to be general enough to be transferable to robotic systems. Previous systems have enabled generation of semantic and human-interpretable robot commands in the form of visual sentences. However, they require manual selection of short action clips, which are then individually processed. We propose a framework for executing demonstrated action sequences from full-length, unconstrained videos on the web. The framework takes as input a video annotated with object labels and bounding boxes, and outputs a collaborative manipulation action plan for one or more robotic arms. We demonstrate the performance of the system in three full-length collaborative cooking videos on the web and propose an open-source platform for executing the learned plans in a simulation environment.
Interactive Differentiable Simulation
May 26, 2019
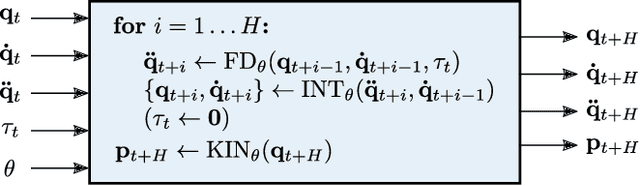
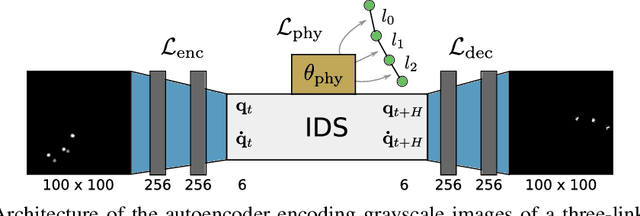
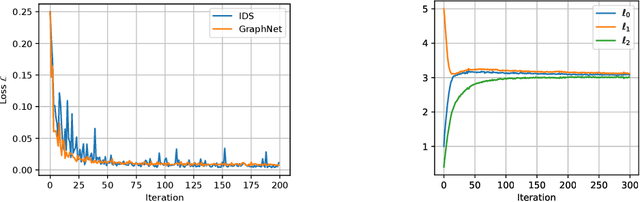
Intelligent agents need a physical understanding of the world to predict the impact of their actions in the future. While learning-based models of the environment dynamics have contributed to significant improvements in sample efficiency compared to model-free reinforcement learning algorithms, they typically fail to generalize to system states beyond the training data, while often grounding their predictions on non-interpretable latent variables. We introduce Interactive Differentiable Simulation (IDS), a differentiable physics engine, that allows for efficient, accurate inference of physical properties of rigid-body systems. Integrated into deep learning architectures, our model is able to accomplish system identification using visual input, leading to an interpretable model of the world whose parameters have physical meaning. We present experiments showing automatic task-based robot design and parameter estimation for nonlinear dynamical systems by automatically calculating gradients in IDS. When integrated into an adaptive model-predictive control algorithm, our approach exhibits orders of magnitude improvements in sample efficiency over model-free reinforcement learning algorithms on challenging nonlinear control domains.
Auto-conditioned Recurrent Mixture Density Networks for Learning Generalizable Robot Skills
Mar 20, 2019
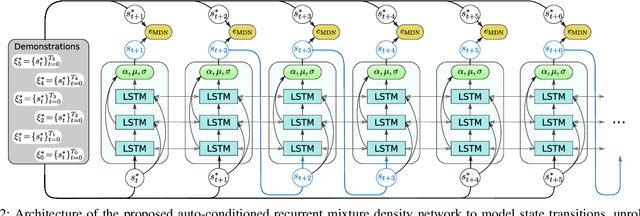
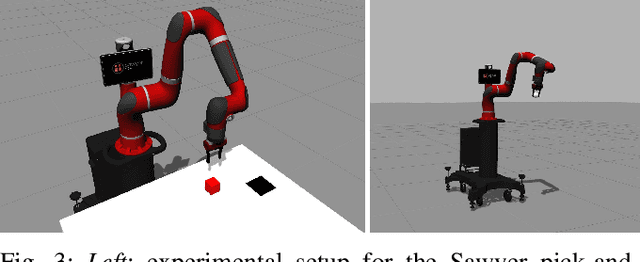
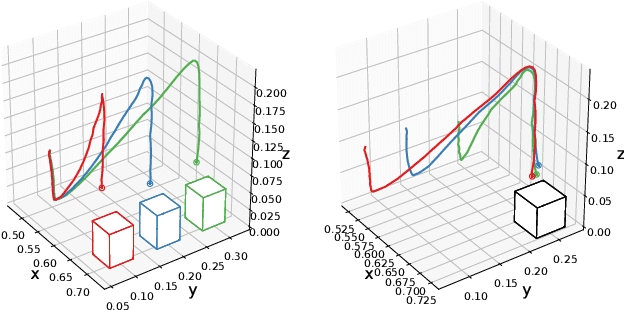
Personal robots assisting humans must perform complex manipulation tasks that are typically difficult to specify in traditional motion planning pipelines, where multiple objectives must be met and the high-level context be taken into consideration. Learning from demonstration (LfD) provides a promising way to learn these kind of complex manipulation skills even from non-technical users. However, it is challenging for existing LfD methods to efficiently learn skills that can generalize to task specifications that are not covered by demonstrations. In this paper, we introduce a state transition model (STM) that generates joint-space trajectories by imitating motions from expert behavior. Given a few demonstrations, we show in real robot experiments that the learned STM can quickly generalize to unseen tasks and synthesize motions having longer time horizons than the expert trajectories. Compared to conventional motion planners, our approach enables the robot to accomplish complex behaviors from high-level instructions without laborious hand-engineering of planning objectives, while being able to adapt to changing goals during the skill execution. In conjunction with a trajectory optimizer, our STM can construct a high-quality skeleton of a trajectory that can be further improved in smoothness and precision. In combination with a learned inverse dynamics model, we additionally present results where the STM is used as a high-level planner. A video of our experiments is available at https://youtu.be/85DX9Ojq-90
Scaling simulation-to-real transfer by learning composable robot skills
Nov 13, 2018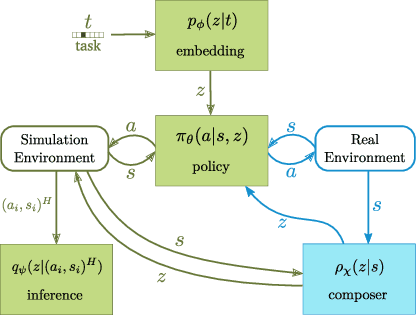
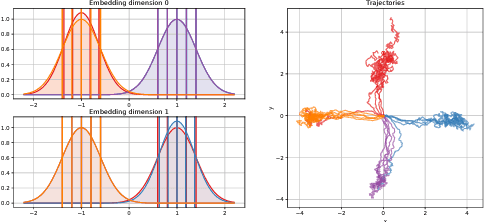

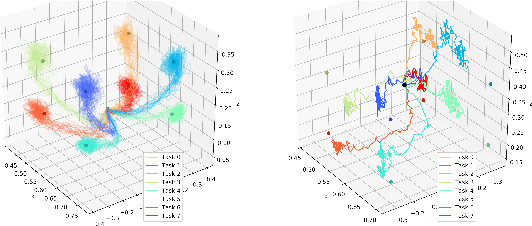
We present a novel solution to the problem of simulation-to-real transfer, which builds on recent advances in robot skill decomposition. Rather than focusing on minimizing the simulation-reality gap, we learn a set of diverse policies that are parameterized in a way that makes them easily reusable. This diversity and parameterization of low-level skills allows us to find a transferable policy that is able to use combinations and variations of different skills to solve more complex, high-level tasks. In particular, we first use simulation to jointly learn a policy for a set of low-level skills, and a "skill embedding" parameterization which can be used to compose them. Later, we learn high-level policies which actuate the low-level policies via this skill embedding parameterization. The high-level policies encode how and when to reuse the low-level skills together to achieve specific high-level tasks. Importantly, our method learns to control a real robot in joint-space to achieve these high-level tasks with little or no on-robot time, despite the fact that the low-level policies may not be perfectly transferable from simulation to real, and that the low-level skills were not trained on any examples of high-level tasks. We illustrate the principles of our method using informative simulation experiments. We then verify its usefulness for real robotics problems by learning, transferring, and composing free-space and contact motion skills on a Sawyer robot using only joint-space control. We experiment with several techniques for composing pre-learned skills, and find that our method allows us to use both learning-based approaches and efficient search-based planning to achieve high-level tasks using only pre-learned skills.