 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJiaoyang Li
Scaling Lifelong Multi-Agent Path Finding to More Realistic Settings: Research Challenges and Opportunities
Apr 24, 2024
Multi-Agent Path Finding (MAPF) is the problem of moving multiple agents from starts to goals without collisions. Lifelong MAPF (LMAPF) extends MAPF by continuously assigning new goals to agents. We present our winning approach to the 2023 League of Robot Runners LMAPF competition, which leads us to several interesting research challenges and future directions. In this paper, we outline three main research challenges. The first challenge is to search for high-quality LMAPF solutions within a limited planning time (e.g., 1s per step) for a large number of agents (e.g., 10,000) or extremely high agent density (e.g., 97.7%). We present future directions such as developing more competitive rule-based and anytime MAPF algorithms and parallelizing state-of-the-art MAPF algorithms. The second challenge is to alleviate congestion and the effect of myopic behaviors in LMAPF algorithms. We present future directions, such as developing moving guidance and traffic rules to reduce congestion, incorporating future prediction and real-time search, and determining the optimal agent number. The third challenge is to bridge the gaps between the LMAPF models used in the literature and real-world applications. We present future directions, such as dealing with more realistic kinodynamic models, execution uncertainty, and evolving systems.
From Space-Time to Space-Order: Directly Planning a Temporal Planning Graph by Redefining CBS
Apr 23, 2024The majority of multi-agent path finding (MAPF) methods compute collision-free space-time paths which require agents to be at a specific location at a specific discretized timestep. However, executing these space-time paths directly on robotic systems is infeasible due to real-time execution differences (e.g. delays) which can lead to collisions. To combat this, current methods translate the space-time paths into a temporal plan graph (TPG) that only requires that agents observe the order in which they navigate through locations where their paths cross. However, planning space-time paths and then post-processing them into a TPG does not reduce the required agent-to-agent coordination, which is fixed once the space-time paths are computed. To that end, we propose a novel algorithm Space-Order CBS that can directly plan a TPG and explicitly minimize coordination. Our main theoretical insight is our novel perspective on viewing a TPG as a set of space-visitation order paths where agents visit locations in relative orders (e.g. 1st vs 2nd) as opposed to specific timesteps. We redefine unique conflicts and constraints for adapting CBS for space-order planning. We experimentally validate how Space-Order CBS can return TPGs which significantly reduce coordination, thus subsequently reducing the amount of agent-agent communication and leading to more robustness to delays during execution.
ITA-ECBS: A Bounded-Suboptimal Algorithm for Combined Target-Assignment and Path-Finding Problem
Apr 08, 2024Multi-Agent Path Finding (MAPF), i.e., finding collision-free paths for multiple robots, plays a critical role in many applications. Sometimes, assigning a specific target to each agent also presents a challenge. The Combined Target-Assignment and Path-Finding (TAPF) problem, a variant of MAPF, requires simultaneously assigning targets to agents and planning collision-free paths. Several algorithms, including CBM, CBS-TA, and ITA-CBS, can optimally solve the TAPF problem, with ITA-CBS being the leading method of flowtime. However, the only existing suboptimal method ECBS-TA, is derived from CBS-TA rather than ITA-CBS, and adapting the optimal ITA-CBS method to its bounded-suboptimal variant is a challenge due to the variability of target assignment solutions in different search nodes. We introduce ITA-ECBS as the first bounded-suboptimal variant of ITA-CBS. ITA-ECBS employs focal search to enhance efficiency and determines target assignments based on a new lower bound matrix. We show that ITA-ECBS outperforms the baseline method ECBS-TA in 87.42% of 54,033 test cases.
Improving Learnt Local MAPF Policies with Heuristic Search
Mar 29, 2024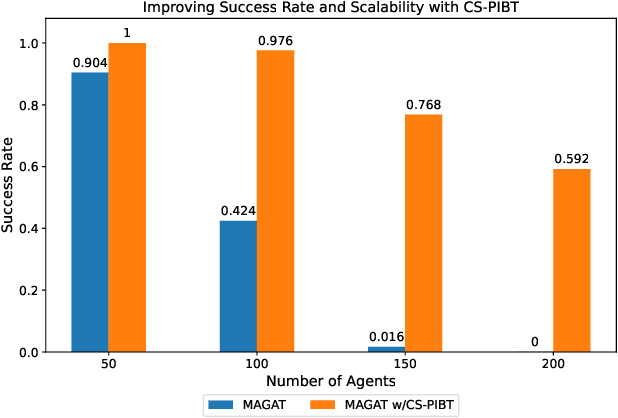
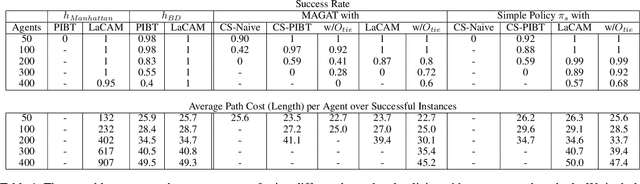
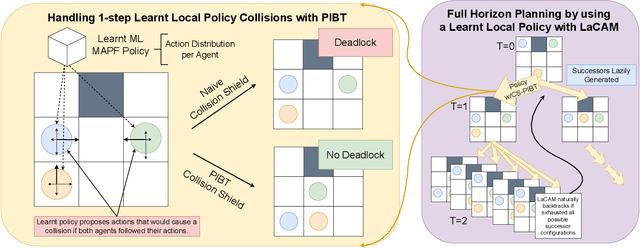
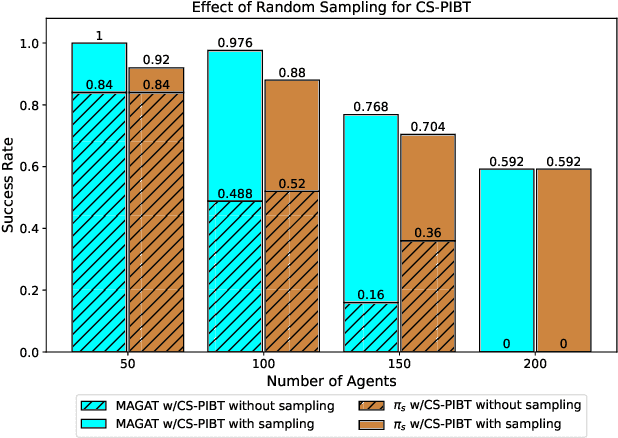
Multi-agent path finding (MAPF) is the problem of finding collision-free paths for a team of agents to reach their goal locations. State-of-the-art classical MAPF solvers typically employ heuristic search to find solutions for hundreds of agents but are typically centralized and can struggle to scale when run with short timeouts. Machine learning (ML) approaches that learn policies for each agent are appealing as these could enable decentralized systems and scale well while maintaining good solution quality. Current ML approaches to MAPF have proposed methods that have started to scratch the surface of this potential. However, state-of-the-art ML approaches produce "local" policies that only plan for a single timestep and have poor success rates and scalability. Our main idea is that we can improve a ML local policy by using heuristic search methods on the output probability distribution to resolve deadlocks and enable full horizon planning. We show several model-agnostic ways to use heuristic search with learnt policies that significantly improve the policies' success rates and scalability. To our best knowledge, we demonstrate the first time ML-based MAPF approaches have scaled to high congestion scenarios (e.g. 20% agent density).
Caching-Augmented Lifelong Multi-Agent Path Finding
Mar 29, 2024
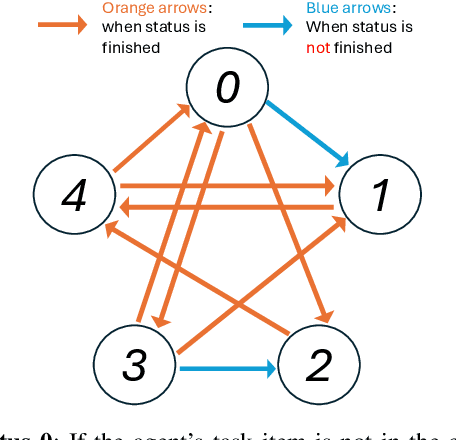

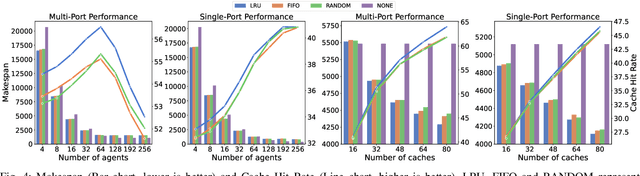
Multi-Agent Path Finding (MAPF), which involves finding collision-free paths for multiple robots, is crucial in various applications. Lifelong MAPF, where targets are reassigned to agents as soon as they complete their initial targets, offers a more accurate approximation of real-world warehouse planning. In this paper, we present a novel mechanism named Caching-Augmented Lifelong MAPF (CAL-MAPF), designed to improve the performance of Lifelong MAPF. We have developed a new type of map grid called cache for temporary item storage and replacement, and designed a locking mechanism for it to improve the stability of the planning solution. This cache mechanism was evaluated using various cache replacement policies and a spectrum of input task distributions. We identified three main factors significantly impacting CAL-MAPF performance through experimentation: suitable input task distribution, high cache hit rate, and smooth traffic. In general, CAL-MAPF has demonstrated potential for performance improvements in certain task distributions, maps, and agent configurations.
Accelerating Search-Based Planning for Multi-Robot Manipulation by Leveraging Online-Generated Experiences
Mar 29, 2024An exciting frontier in robotic manipulation is the use of multiple arms at once. However, planning concurrent motions is a challenging task using current methods. The high-dimensional composite state space renders many well-known motion planning algorithms intractable. Recently, Multi-Agent Path-Finding (MAPF) algorithms have shown promise in discrete 2D domains, providing rigorous guarantees. However, widely used conflict-based methods in MAPF assume an efficient single-agent motion planner. This poses challenges in adapting them to manipulation cases where this assumption does not hold, due to the high dimensionality of configuration spaces and the computational bottlenecks associated with collision checking. To this end, we propose an approach for accelerating conflict-based search algorithms by leveraging their repetitive and incremental nature -- making them tractable for use in complex scenarios involving multi-arm coordination in obstacle-laden environments. We show that our method preserves completeness and bounded sub-optimality guarantees, and demonstrate its practical efficacy through a set of experiments with up to 10 robotic arms.
A Real-Time Rescheduling Algorithm for Multi-robot Plan Execution
Mar 26, 2024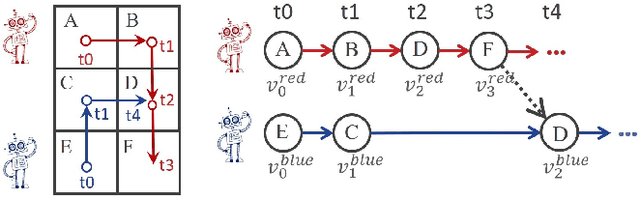
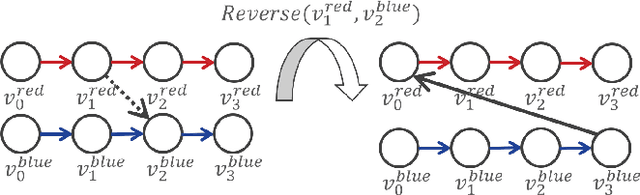
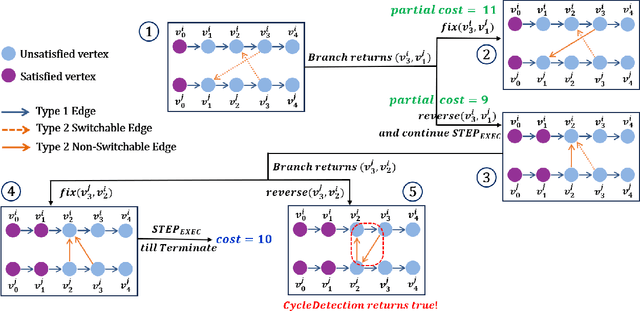
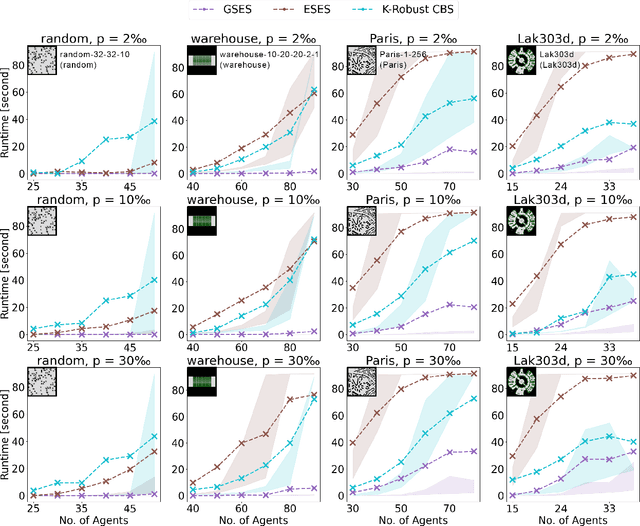
One area of research in multi-agent path finding is to determine how replanning can be efficiently achieved in the case of agents being delayed during execution. One option is to reschedule the passing order of agents, i.e., the sequence in which agents visit the same location. In response, we propose Switchable-Edge Search (SES), an A*-style algorithm designed to find optimal passing orders. We prove the optimality of SES and evaluate its efficiency via simulations. The best variant of SES takes less than 1 second for small- and medium-sized problems and runs up to 4 times faster than baselines for large-sized problems.
Optimal Task Assignment and Path Planning using Conflict-Based Search with Precedence and Temporal Constraints
Feb 13, 2024The Multi-Agent Path Finding (MAPF) problem entails finding collision-free paths for a set of agents, guiding them from their start to goal locations. However, MAPF does not account for several practical task-related constraints. For example, agents may need to perform actions at goal locations with specific execution times, adhering to predetermined orders and timeframes. Moreover, goal assignments may not be predefined for agents, and the optimization objective may lack an explicit definition. To incorporate task assignment, path planning, and a user-defined objective into a coherent framework, this paper examines the Task Assignment and Path Finding with Precedence and Temporal Constraints (TAPF-PTC) problem. We augment Conflict-Based Search (CBS) to simultaneously generate task assignments and collision-free paths that adhere to precedence and temporal constraints, maximizing an objective quantified by the return from a user-defined reward function in reinforcement learning (RL). Experimentally, we demonstrate that our algorithm, CBS-TA-PTC, can solve highly challenging bomb-defusing tasks with precedence and temporal constraints efficiently relative to MARL and adapted Target Assignment and Path Finding (TAPF) methods.
Guidance Graph Optimization for Lifelong Multi-Agent Path Finding
Feb 02, 2024We study how to use guidance to improve the throughput of lifelong Multi-Agent Path Finding (MAPF). Previous studies have demonstrated that while incorporating guidance, such as highways, can accelerate MAPF algorithms, this often results in a trade-off with solution quality. In addition, how to generate good guidance automatically remains largely unexplored, with current methods falling short of surpassing manually designed ones. In this work, we introduce the directed guidance graph as a versatile representation of guidance for lifelong MAPF, framing Guidance Graph Optimization (GGO) as the task of optimizing its edge weights. We present two GGO algorithms to automatically generate guidance for arbitrary lifelong MAPF algorithms and maps. The first method directly solves GGO by employing CMA-ES, a black-box optimization algorithm. The second method, PIU, optimizes an update model capable of generating guidance, demonstrating the ability to transfer optimized guidance graphs to larger maps with similar layouts. Empirically, we show that (1) our guidance graphs improve the throughput of three representative lifelong MAPF algorithms in four benchmark maps, and (2) our update model can generate guidance graphs for as large as $93 \times 91$ maps and as many as 3000 agents.
Scalable Mechanism Design for Multi-Agent Path Finding
Jan 30, 2024Multi-Agent Path Finding (MAPF) involves determining paths for multiple agents to travel simultaneously through a shared area toward particular goal locations. This problem is computationally complex, especially when dealing with large numbers of agents, as is common in realistic applications like autonomous vehicle coordination. Finding an optimal solution is often computationally infeasible, making the use of approximate algorithms essential. Adding to the complexity, agents might act in a self-interested and strategic way, possibly misrepresenting their goals to the MAPF algorithm if it benefits them. Although the field of mechanism design offers tools to align incentives, using these tools without careful consideration can fail when only having access to approximately optimal outcomes. Since approximations are crucial for scalable MAPF algorithms, this poses a significant challenge. In this work, we introduce the problem of scalable mechanism design for MAPF and propose three strategyproof mechanisms, two of which even use approximate MAPF algorithms. We test our mechanisms on realistic MAPF domains with problem sizes ranging from dozens to hundreds of agents. Our findings indicate that they improve welfare beyond a simple baseline.