 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaxim Likhachev
Unconstraining Multi-Robot Manipulation: Enabling Arbitrary Constraints in ECBS with Bounded Sub-Optimality
May 07, 2024
Multi-Robot-Arm Motion Planning (M-RAMP) is a challenging problem featuring complex single-agent planning and multi-agent coordination. Recent advancements in extending the popular Conflict-Based Search (CBS) algorithm have made large strides in solving Multi-Agent Path Finding (MAPF) problems. However, fundamental challenges remain in applying CBS to M-RAMP. A core challenge is the existing reliance of the CBS framework on conservative "complete" constraints. These constraints ensure solution guarantees but often result in slow pruning of the search space -- causing repeated expensive single-agent planning calls. Therefore, even though it is possible to leverage domain knowledge and design incomplete M-RAMP-specific CBS constraints to more efficiently prune the search, using these constraints would render the algorithm itself incomplete. This forces practitioners to choose between efficiency and completeness. In light of these challenges, we propose a novel algorithm, Generalized ECBS, aimed at removing the burden of choice between completeness and efficiency in MAPF algorithms. Our approach enables the use of arbitrary constraints in conflict-based algorithms while preserving completeness and bounding sub-optimality. This enables practitioners to capitalize on the benefits of arbitrary constraints and opens a new space for constraint design in MAPF that has not been explored. We provide a theoretical analysis of our algorithms, propose new "incomplete" constraints, and demonstrate their effectiveness through experiments in M-RAMP.
From Space-Time to Space-Order: Directly Planning a Temporal Planning Graph by Redefining CBS
Apr 23, 2024The majority of multi-agent path finding (MAPF) methods compute collision-free space-time paths which require agents to be at a specific location at a specific discretized timestep. However, executing these space-time paths directly on robotic systems is infeasible due to real-time execution differences (e.g. delays) which can lead to collisions. To combat this, current methods translate the space-time paths into a temporal plan graph (TPG) that only requires that agents observe the order in which they navigate through locations where their paths cross. However, planning space-time paths and then post-processing them into a TPG does not reduce the required agent-to-agent coordination, which is fixed once the space-time paths are computed. To that end, we propose a novel algorithm Space-Order CBS that can directly plan a TPG and explicitly minimize coordination. Our main theoretical insight is our novel perspective on viewing a TPG as a set of space-visitation order paths where agents visit locations in relative orders (e.g. 1st vs 2nd) as opposed to specific timesteps. We redefine unique conflicts and constraints for adapting CBS for space-order planning. We experimentally validate how Space-Order CBS can return TPGs which significantly reduce coordination, thus subsequently reducing the amount of agent-agent communication and leading to more robustness to delays during execution.
A Data Efficient Framework for Learning Local Heuristics
Apr 10, 2024With the advent of machine learning, there have been several recent attempts to learn effective and generalizable heuristics. Local Heuristic A* (LoHA*) is one recent method that instead of learning the entire heuristic estimate, learns a "local" residual heuristic that estimates the cost to escape a region (Veerapaneni et al 2023). LoHA*, like other supervised learning methods, collects a dataset of target values by querying an oracle on many planning problems (in this case, local planning problems). This data collection process can become slow as the size of the local region increases or if the domain requires expensive collision checks. Our main insight is that when an A* search solves a start-goal planning problem it inherently ends up solving multiple local planning problems. We exploit this observation to propose an efficient data collection framework that does <1/10th the amount of work (measured by expansions) to collect the same amount of data in comparison to baselines. This idea also enables us to run LoHA* in an online manner where we can iteratively collect data and improve our model while solving relevant start-goal tasks. We demonstrate the performance of our data collection and online framework on a 4D $(x, y, \theta, v)$ navigation domain.
Accelerating Search-Based Planning for Multi-Robot Manipulation by Leveraging Online-Generated Experiences
Mar 29, 2024An exciting frontier in robotic manipulation is the use of multiple arms at once. However, planning concurrent motions is a challenging task using current methods. The high-dimensional composite state space renders many well-known motion planning algorithms intractable. Recently, Multi-Agent Path-Finding (MAPF) algorithms have shown promise in discrete 2D domains, providing rigorous guarantees. However, widely used conflict-based methods in MAPF assume an efficient single-agent motion planner. This poses challenges in adapting them to manipulation cases where this assumption does not hold, due to the high dimensionality of configuration spaces and the computational bottlenecks associated with collision checking. To this end, we propose an approach for accelerating conflict-based search algorithms by leveraging their repetitive and incremental nature -- making them tractable for use in complex scenarios involving multi-arm coordination in obstacle-laden environments. We show that our method preserves completeness and bounded sub-optimality guarantees, and demonstrate its practical efficacy through a set of experiments with up to 10 robotic arms.
Improving Learnt Local MAPF Policies with Heuristic Search
Mar 29, 2024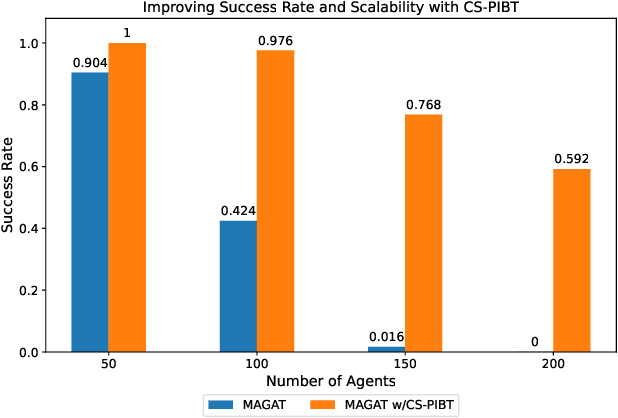
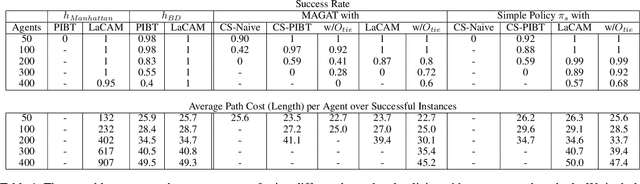
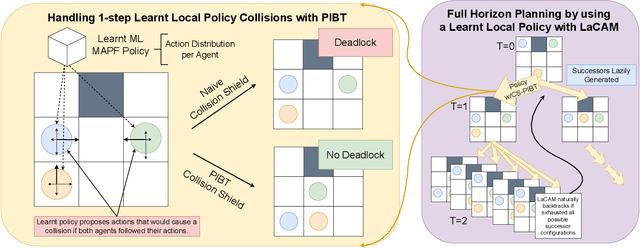
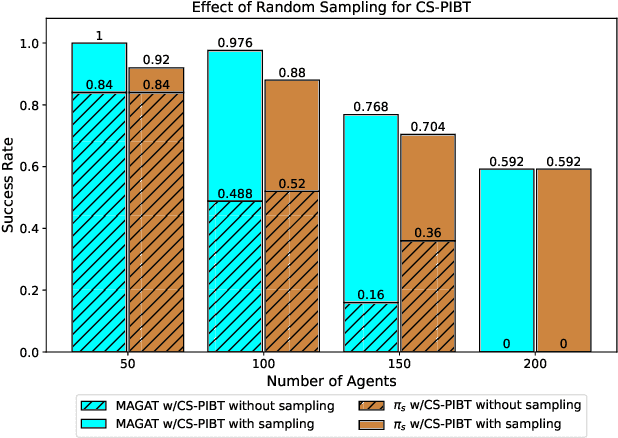
Multi-agent path finding (MAPF) is the problem of finding collision-free paths for a team of agents to reach their goal locations. State-of-the-art classical MAPF solvers typically employ heuristic search to find solutions for hundreds of agents but are typically centralized and can struggle to scale when run with short timeouts. Machine learning (ML) approaches that learn policies for each agent are appealing as these could enable decentralized systems and scale well while maintaining good solution quality. Current ML approaches to MAPF have proposed methods that have started to scratch the surface of this potential. However, state-of-the-art ML approaches produce "local" policies that only plan for a single timestep and have poor success rates and scalability. Our main idea is that we can improve a ML local policy by using heuristic search methods on the output probability distribution to resolve deadlocks and enable full horizon planning. We show several model-agnostic ways to use heuristic search with learnt policies that significantly improve the policies' success rates and scalability. To our best knowledge, we demonstrate the first time ML-based MAPF approaches have scaled to high congestion scenarios (e.g. 20% agent density).
PINSAT: Parallelized Interleaving of Graph Search and Trajectory Optimization for Kinodynamic Motion Planning
Jan 17, 2024Trajectory optimization is a widely used technique in robot motion planning for letting the dynamics and constraints on the system shape and synthesize complex behaviors. Several previous works have shown its benefits in high-dimensional continuous state spaces and under differential constraints. However, long time horizons and planning around obstacles in non-convex spaces pose challenges in guaranteeing convergence or finding optimal solutions. As a result, discrete graph search planners and sampling-based planers are preferred when facing obstacle-cluttered environments. A recently developed algorithm called INSAT effectively combines graph search in the low-dimensional subspace and trajectory optimization in the full-dimensional space for global kinodynamic planning over long horizons. Although INSAT successfully reasoned about and solved complex planning problems, the numerous expensive calls to an optimizer resulted in large planning times, thereby limiting its practical use. Inspired by the recent work on edge-based parallel graph search, we present PINSAT, which introduces systematic parallelization in INSAT to achieve lower planning times and higher success rates, while maintaining significantly lower costs over relevant baselines. We demonstrate PINSAT by evaluating it on 6 DoF kinodynamic manipulation planning with obstacles.
Preprocessing-based Kinodynamic Motion Planning Framework for Intercepting Projectiles using a Robot Manipulator
Jan 16, 2024We are interested in studying sports with robots and starting with the problem of intercepting a projectile moving toward a robot manipulator equipped with a shield. To successfully perform this task, the robot needs to (i) detect the incoming projectile, (ii) predict the projectile's future motion, (iii) plan a minimum-time rapid trajectory that can evade obstacles and intercept the projectile, and (iv) execute the planned trajectory. These four steps must be performed under the manipulator's dynamic limits and extreme time constraints (<350ms in our setting) to successfully intercept the projectile. In addition, we want these trajectories to be smooth to reduce the robot's joint torques and the impulse on the platform on which it is mounted. To this end, we propose a kinodynamic motion planning framework that preprocesses smooth trajectories offline to allow real-time collision-free executions online. We present an end-to-end pipeline along with our planning framework, including perception, prediction, and execution modules. We evaluate our framework experimentally in simulation and show that it has a higher blocking success rate than the baselines. Further, we deploy our pipeline on a robotic system comprising an industrial arm (ABB IRB-1600) and an onboard stereo camera (ZED 2i), which achieves a 78% success rate in projectile interceptions.
Constant-time Motion Planning with Anytime Refinement for Manipulation
Nov 01, 2023Robotic manipulators are essential for future autonomous systems, yet limited trust in their autonomy has confined them to rigid, task-specific systems. The intricate configuration space of manipulators, coupled with the challenges of obstacle avoidance and constraint satisfaction, often makes motion planning the bottleneck for achieving reliable and adaptable autonomy. Recently, a class of constant-time motion planners (CTMP) was introduced. These planners employ a preprocessing phase to compute data structures that enable online planning provably guarantee the ability to generate motion plans, potentially sub-optimal, within a user defined time bound. This framework has been demonstrated to be effective in a number of time-critical tasks. However, robotic systems often have more time allotted for planning than the online portion of CTMP requires, time that can be used to improve the solution. To this end, we propose an anytime refinement approach that works in combination with CTMP algorithms. Our proposed framework, as it operates as a constant time algorithm, rapidly generates an initial solution within a user-defined time threshold. Furthermore, functioning as an anytime algorithm, it iteratively refines the solution's quality within the allocated time budget. This enables our approach to strike a balance between guaranteed fast plan generation and the pursuit of optimization over time. We support our approach by elucidating its analytical properties, showing the convergence of the anytime component towards optimal solutions. Additionally, we provide empirical validation through simulation and real-world demonstrations on a 6 degree-of-freedom robot manipulator, applied to an assembly domain.
A-ePA*SE: Anytime Edge-Based Parallel A* for Slow Evaluations
May 08, 2023


Anytime search algorithms are useful for planning problems where a solution is desired under a limited time budget. Anytime algorithms first aim to provide a feasible solution quickly and then attempt to improve it until the time budget expires. On the other hand, parallel search algorithms utilize the multithreading capability of modern processors to speed up the search. One such algorithm, ePA*SE (Edge-Based Parallel A* for Slow Evaluations), parallelizes edge evaluations to achieve faster planning and is especially useful in domains with expensive-to-compute edges. In this work, we propose an extension that brings the anytime property to ePA*SE, resulting in A-ePA*SE. We evaluate A-ePA*SE experimentally and show that it is significantly more efficient than other anytime search methods. The open-source code for A-ePA*SE, along with the baselines, is available here: https://github.com/shohinm/parallel_search
Planning for Manipulation among Movable Objects: Deciding Which Objects Go Where, in What Order, and How
Mar 23, 2023



We are interested in pick-and-place style robot manipulation tasks in cluttered and confined 3D workspaces among movable objects that may be rearranged by the robot and may slide, tilt, lean or topple. A recently proposed algorithm, M4M, determines which objects need to be moved and where by solving a Multi-Agent Pathfinding MAPF abstraction of this problem. It then utilises a nonprehensile push planner to compute actions for how the robot might realise these rearrangements and a rigid body physics simulator to check whether the actions satisfy physics constraints encoded in the problem. However, M4M greedily commits to valid pushes found during planning, and does not reason about orderings over pushes if multiple objects need to be rearranged. Furthermore, M4M does not reason about other possible MAPF solutions that lead to different rearrangements and pushes. In this paper, we extend M4M and present Enhanced-M4M (E-M4M) -- a systematic graph search-based solver that searches over orderings of pushes for movable objects that need to be rearranged and different possible rearrangements of the scene. We introduce several algorithmic optimisations to circumvent the increased computational complexity, discuss the space of problems solvable by E-M4M and show that experimentally, both on the real robot and in simulation, it significantly outperforms the original M4M algorithm, as well as other state-of-the-art alternatives when dealing with complex scenes.