 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHiroki Kajita
Deep Selection: A Fully Supervised Camera Selection Network for Surgery Recordings
Mar 28, 2023
Recording surgery in operating rooms is an essential task for education and evaluation of medical treatment. However, recording the desired targets, such as the surgery field, surgical tools, or doctor's hands, is difficult because the targets are heavily occluded during surgery. We use a recording system in which multiple cameras are embedded in the surgical lamp, and we assume that at least one camera is recording the target without occlusion at any given time. As the embedded cameras obtain multiple video sequences, we address the task of selecting the camera with the best view of the surgery. Unlike the conventional method, which selects the camera based on the area size of the surgery field, we propose a deep neural network that predicts the camera selection probability from multiple video sequences by learning the supervision of the expert annotation. We created a dataset in which six different types of plastic surgery are recorded, and we provided the annotation of camera switching. Our experiments show that our approach successfully switched between cameras and outperformed three baseline methods.
Deep Learning in Diabetic Foot Ulcers Detection: A Comprehensive Evaluation
Oct 15, 2020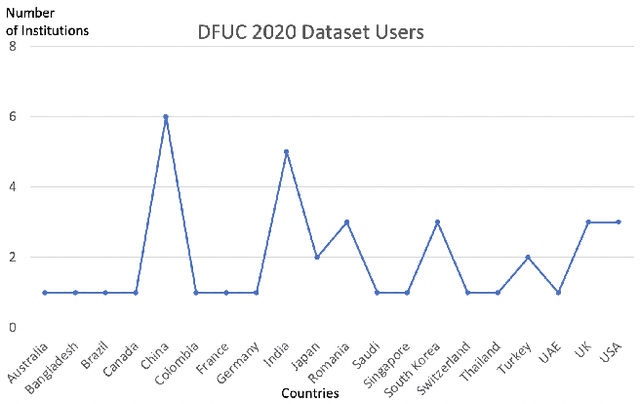
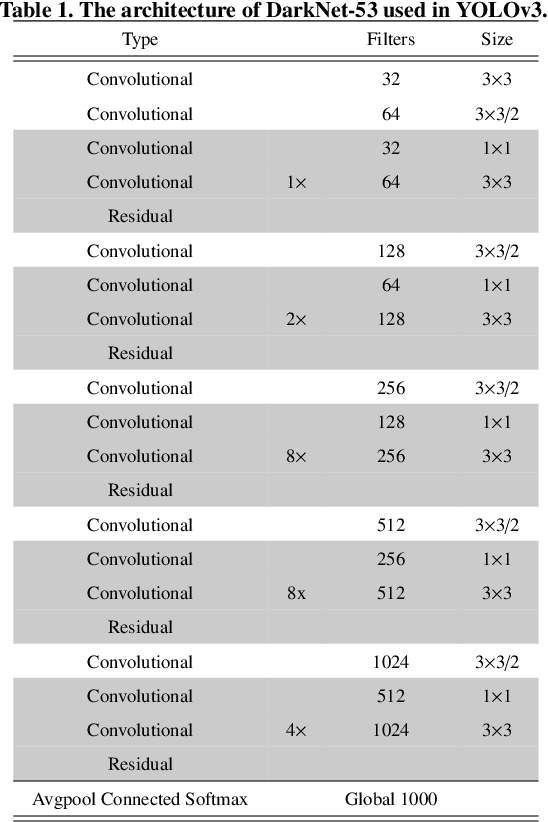
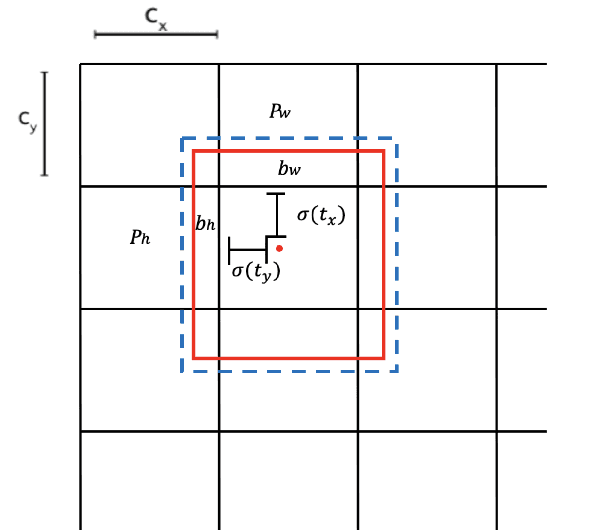
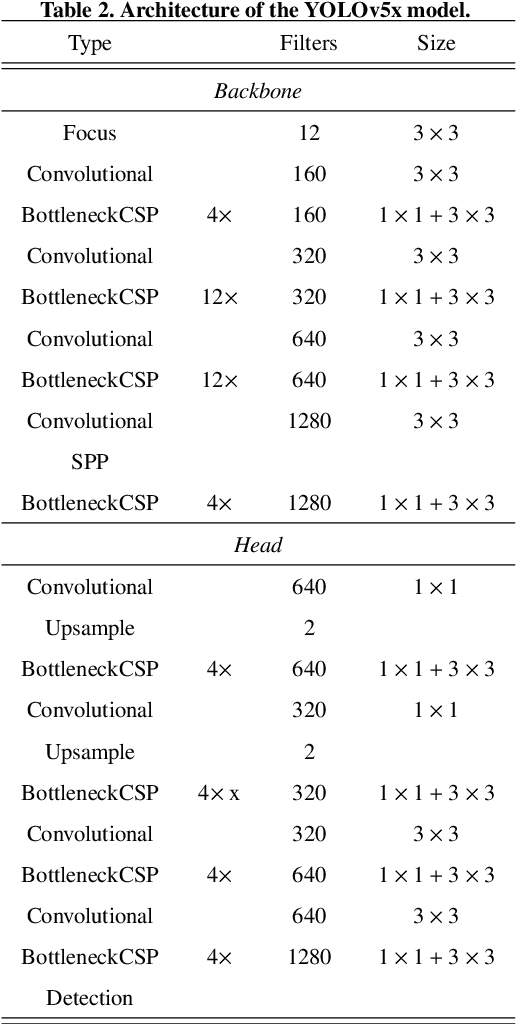
There has been a substantial amount of research on computer methods and technology for the detection and recognition of diabetic foot ulcers (DFUs), but there is a lack of systematic comparisons of state-of-the-art deep learning object detection frameworks applied to this problem. With recent development and data sharing performed as part of the DFU Challenge (DFUC2020) such a comparison becomes possible: DFUC2020 provided participants with a comprehensive dataset consisting of 2,000 images for training each method and 2,000 images for testing them. The following deep learning-based algorithms are compared in this paper: Faster R-CNN, three variants of Faster R-CNN and an ensemble method; YOLOv3; YOLOv5; EfficientDet; and a new Cascade Attention Network. For each deep learning method, we provide a detailed description of model architecture, parameter settings for training and additional stages including pre-processing, data augmentation and post-processing. We provide a comprehensive evaluation for each method. All the methods required a data augmentation stage to increase the number of images available for training and a post-processing stage to remove false positives. The best performance is obtained Deformable Convolution, a variant of Faster R-CNN, with a mAP of 0.6940 and an F1-Score of 0.7434. Finally, we demonstrate that the ensemble method based on different deep learning methods can enhanced the F1-Score but not the mAP. Our results show that state-of-the-art deep learning methods can detect DFU with some accuracy, but there are many challenges ahead before they can be implemented in real world settings.