 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRyo Hachiuma
Weakly Semi-supervised Tool Detection in Minimally Invasive Surgery Videos
Jan 08, 2024
Surgical tool detection is essential for analyzing and evaluating minimally invasive surgery videos. Current approaches are mostly based on supervised methods that require large, fully instance-level labels (i.e., bounding boxes). However, large image datasets with instance-level labels are often limited because of the burden of annotation. Thus, surgical tool detection is important when providing image-level labels instead of instance-level labels since image-level annotations are considerably more time-efficient than instance-level annotations. In this work, we propose to strike a balance between the extremely costly annotation burden and detection performance. We further propose a co-occurrence loss, which considers a characteristic that some tool pairs often co-occur together in an image to leverage image-level labels. Encapsulating the knowledge of co-occurrence using the co-occurrence loss helps to overcome the difficulty in classification that originates from the fact that some tools have similar shapes and textures. Extensive experiments conducted on the Endovis2018 dataset in various data settings show the effectiveness of our method.
Surgical tool classification and localization: results and methods from the MICCAI 2022 SurgToolLoc challenge
May 11, 2023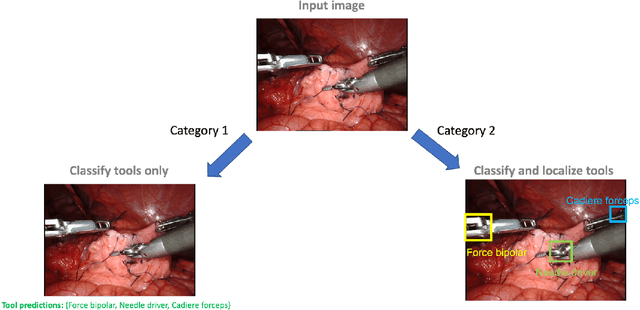
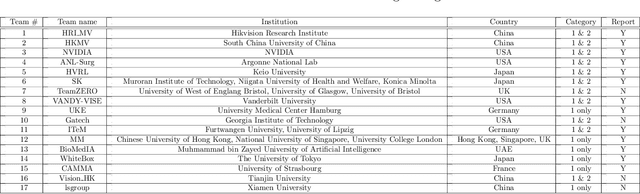
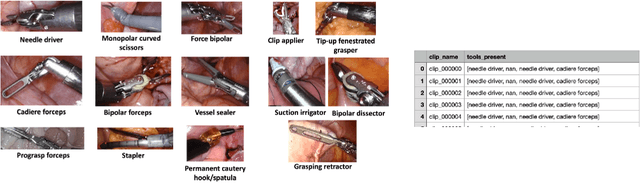
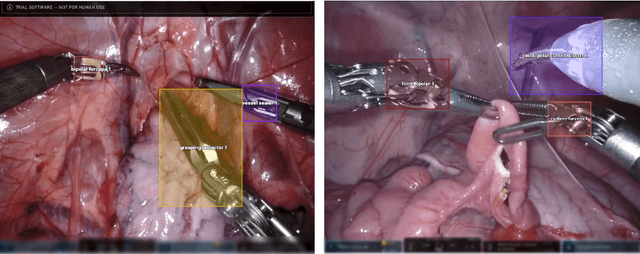
The ability to automatically detect and track surgical instruments in endoscopic videos can enable transformational interventions. Assessing surgical performance and efficiency, identifying skilled tool use and choreography, and planning operational and logistical aspects of OR resources are just a few of the applications that could benefit. Unfortunately, obtaining the annotations needed to train machine learning models to identify and localize surgical tools is a difficult task. Annotating bounding boxes frame-by-frame is tedious and time-consuming, yet large amounts of data with a wide variety of surgical tools and surgeries must be captured for robust training. Moreover, ongoing annotator training is needed to stay up to date with surgical instrument innovation. In robotic-assisted surgery, however, potentially informative data like timestamps of instrument installation and removal can be programmatically harvested. The ability to rely on tool installation data alone would significantly reduce the workload to train robust tool-tracking models. With this motivation in mind we invited the surgical data science community to participate in the challenge, SurgToolLoc 2022. The goal was to leverage tool presence data as weak labels for machine learning models trained to detect tools and localize them in video frames with bounding boxes. We present the results of this challenge along with many of the team's efforts. We conclude by discussing these results in the broader context of machine learning and surgical data science. The training data used for this challenge consisting of 24,695 video clips with tool presence labels is also being released publicly and can be accessed at https://console.cloud.google.com/storage/browser/isi-surgtoolloc-2022.
Toward Unsupervised 3D Point Cloud Anomaly Detection using Variational Autoencoder
Apr 07, 2023



In this paper, we present an end-to-end unsupervised anomaly detection framework for 3D point clouds. To the best of our knowledge, this is the first work to tackle the anomaly detection task on a general object represented by a 3D point cloud. We propose a deep variational autoencoder-based unsupervised anomaly detection network adapted to the 3D point cloud and an anomaly score specifically for 3D point clouds. To verify the effectiveness of the model, we conducted extensive experiments on the ShapeNet dataset. Through quantitative and qualitative evaluation, we demonstrate that the proposed method outperforms the baseline method. Our code is available at https://github.com/llien30/point_cloud_anomaly_detection.
Deep Selection: A Fully Supervised Camera Selection Network for Surgery Recordings
Mar 28, 2023Recording surgery in operating rooms is an essential task for education and evaluation of medical treatment. However, recording the desired targets, such as the surgery field, surgical tools, or doctor's hands, is difficult because the targets are heavily occluded during surgery. We use a recording system in which multiple cameras are embedded in the surgical lamp, and we assume that at least one camera is recording the target without occlusion at any given time. As the embedded cameras obtain multiple video sequences, we address the task of selecting the camera with the best view of the surgery. Unlike the conventional method, which selects the camera based on the area size of the surgery field, we propose a deep neural network that predicts the camera selection probability from multiple video sequences by learning the supervision of the expert annotation. We created a dataset in which six different types of plastic surgery are recorded, and we provided the annotation of camera switching. Our experiments show that our approach successfully switched between cameras and outperformed three baseline methods.
Unified Keypoint-based Action Recognition Framework via Structured Keypoint Pooling
Mar 27, 2023



This paper simultaneously addresses three limitations associated with conventional skeleton-based action recognition; skeleton detection and tracking errors, poor variety of the targeted actions, as well as person-wise and frame-wise action recognition. A point cloud deep-learning paradigm is introduced to the action recognition, and a unified framework along with a novel deep neural network architecture called Structured Keypoint Pooling is proposed. The proposed method sparsely aggregates keypoint features in a cascaded manner based on prior knowledge of the data structure (which is inherent in skeletons), such as the instances and frames to which each keypoint belongs, and achieves robustness against input errors. Its less constrained and tracking-free architecture enables time-series keypoints consisting of human skeletons and nonhuman object contours to be efficiently treated as an input 3D point cloud and extends the variety of the targeted action. Furthermore, we propose a Pooling-Switching Trick inspired by Structured Keypoint Pooling. This trick switches the pooling kernels between the training and inference phases to detect person-wise and frame-wise actions in a weakly supervised manner using only video-level action labels. This trick enables our training scheme to naturally introduce novel data augmentation, which mixes multiple point clouds extracted from different videos. In the experiments, we comprehensively verify the effectiveness of the proposed method against the limitations, and the method outperforms state-of-the-art skeleton-based action recognition and spatio-temporal action localization methods.
Prompt-Guided Zero-Shot Anomaly Action Recognition using Pretrained Deep Skeleton Features
Mar 27, 2023



This study investigates unsupervised anomaly action recognition, which identifies video-level abnormal-human-behavior events in an unsupervised manner without abnormal samples, and simultaneously addresses three limitations in the conventional skeleton-based approaches: target domain-dependent DNN training, robustness against skeleton errors, and a lack of normal samples. We present a unified, user prompt-guided zero-shot learning framework using a target domain-independent skeleton feature extractor, which is pretrained on a large-scale action recognition dataset. Particularly, during the training phase using normal samples, the method models the distribution of skeleton features of the normal actions while freezing the weights of the DNNs and estimates the anomaly score using this distribution in the inference phase. Additionally, to increase robustness against skeleton errors, we introduce a DNN architecture inspired by a point cloud deep learning paradigm, which sparsely propagates the features between joints. Furthermore, to prevent the unobserved normal actions from being misidentified as abnormal actions, we incorporate a similarity score between the user prompt embeddings and skeleton features aligned in the common space into the anomaly score, which indirectly supplements normal actions. On two publicly available datasets, we conduct experiments to test the effectiveness of the proposed method with respect to abovementioned limitations.
A Two-Block RNN-based Trajectory Prediction from Incomplete Trajectory
Mar 16, 2022



Trajectory prediction has gained great attention and significant progress has been made in recent years. However, most works rely on a key assumption that each video is successfully preprocessed by detection and tracking algorithms and the complete observed trajectory is always available. However, in complex real-world environments, we often encounter miss-detection of target agents (e.g., pedestrian, vehicles) caused by the bad image conditions, such as the occlusion by other agents. In this paper, we address the problem of trajectory prediction from incomplete observed trajectory due to miss-detection, where the observed trajectory includes several missing data points. We introduce a two-block RNN model that approximates the inference steps of the Bayesian filtering framework and seeks the optimal estimation of the hidden state when miss-detection occurs. The model uses two RNNs depending on the detection result. One RNN approximates the inference step of the Bayesian filter with the new measurement when the detection succeeds, while the other does the approximation when the detection fails. Our experiments show that the proposed model improves the prediction accuracy compared to the three baseline imputation methods on publicly available datasets: ETH and UCY ($9\%$ and $7\%$ improvement on the ADE and FDE metrics). We also show that our proposed method can achieve better prediction compared to the baselines when there is no miss-detection.
RGB-D Image Inpainting Using Generative Adversarial Network with a Late Fusion Approach
Oct 14, 2021



Diminished reality is a technology that aims to remove objects from video images and fills in the missing region with plausible pixels. Most conventional methods utilize the different cameras that capture the same scene from different viewpoints to allow regions to be removed and restored. In this paper, we propose an RGB-D image inpainting method using generative adversarial network, which does not require multiple cameras. Recently, an RGB image inpainting method has achieved outstanding results by employing a generative adversarial network. However, RGB inpainting methods aim to restore only the texture of the missing region and, therefore, does not recover geometric information (i.e, 3D structure of the scene). We expand conventional image inpainting method to RGB-D image inpainting to jointly restore the texture and geometry of missing regions from a pair of RGB and depth images. Inspired by other tasks that use RGB and depth images (e.g., semantic segmentation and object detection), we propose late fusion approach that exploits the advantage of RGB and depth information each other. The experimental results verify the effectiveness of our proposed method.
Multi-modal estimation of the properties of containers and their content: survey and evaluation
Jul 27, 2021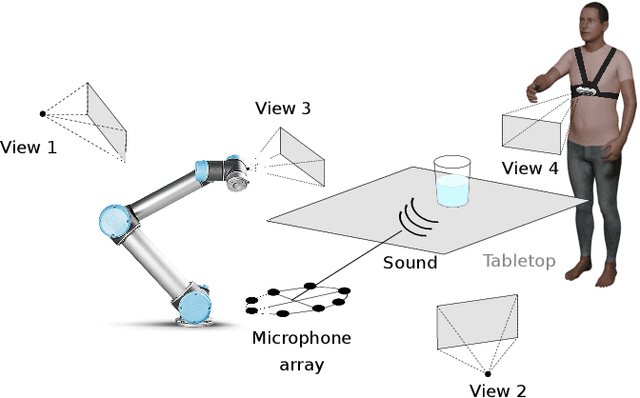



Acoustic and visual sensing can support the contactless estimation of the weight of a container and the amount of its content when the container is manipulated by a person. However, transparencies (both of the container and of the content) and the variability of materials, shapes and sizes make this problem challenging. In this paper, we present an open benchmarking framework and an in-depth comparative analysis of recent methods that estimate the capacity of a container, as well as the type, mass, and amount of its content. These methods use learned and handcrafted features, such as mel-frequency cepstrum coefficients, zero-crossing rate, spectrograms, with different types of classifiers to estimate the type and amount of the content with acoustic data, and geometric approaches with visual data to determine the capacity of the container. Results on a newly distributed dataset show that audio alone is a strong modality and methods achieves a weighted average F1-score up to 81% and 97% for content type and level classification, respectively. Estimating the container capacity with vision-only approaches and filling mass with multi-modal, multi-stage algorithms reaches up to 65% weighted average capacity and mass scores.
Dynamics-Regulated Kinematic Policy for Egocentric Pose Estimation
Jun 10, 2021



We propose a method for object-aware 3D egocentric pose estimation that tightly integrates kinematics modeling, dynamics modeling, and scene object information. Unlike prior kinematics or dynamics-based approaches where the two components are used disjointly, we synergize the two approaches via dynamics-regulated training. At each timestep, a kinematic model is used to provide a target pose using video evidence and simulation state. Then, a prelearned dynamics model attempts to mimic the kinematic pose in a physics simulator. By comparing the pose instructed by the kinematic model against the pose generated by the dynamics model, we can use their misalignment to further improve the kinematic model. By factoring in the 6DoF pose of objects (e.g., chairs, boxes) in the scene, we demonstrate for the first time, the ability to estimate physically-plausible 3D human-object interactions using a single wearable camera. We evaluate our egocentric pose estimation method in both controlled laboratory settings and real-world scenarios.