 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHolger Rauhut
Uncertainty quantification for learned ISTA
Sep 14, 2023



Model-based deep learning solutions to inverse problems have attracted increasing attention in recent years as they bridge state-of-the-art numerical performance with interpretability. In addition, the incorporated prior domain knowledge can make the training more efficient as the smaller number of parameters allows the training step to be executed with smaller datasets. Algorithm unrolling schemes stand out among these model-based learning techniques. Despite their rapid advancement and their close connection to traditional high-dimensional statistical methods, they lack certainty estimates and a theory for uncertainty quantification is still elusive. This work provides a step towards closing this gap proposing a rigorous way to obtain confidence intervals for the LISTA estimator.
Don't be so Monotone: Relaxing Stochastic Line Search in Over-Parameterized Models
Jun 22, 2023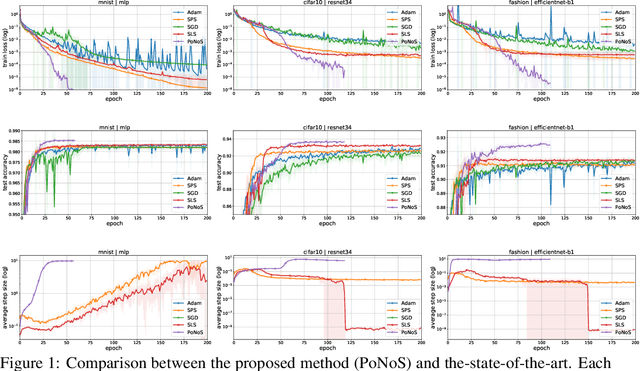
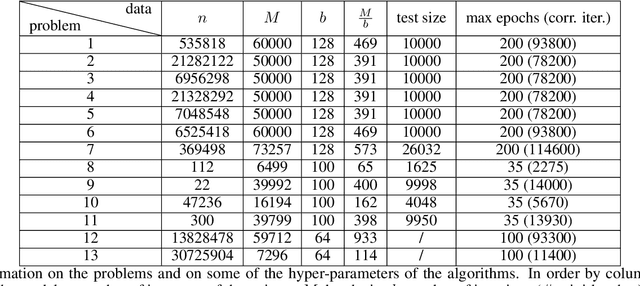
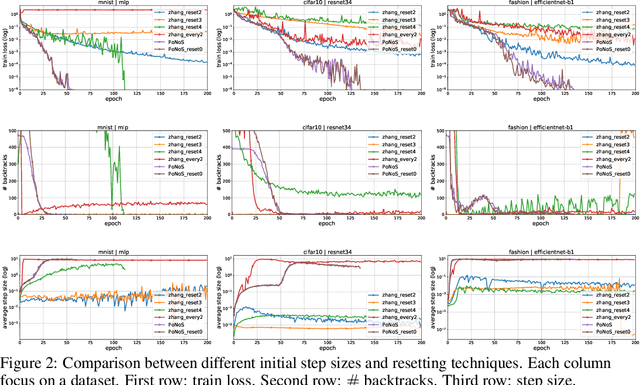

Recent works have shown that line search methods can speed up Stochastic Gradient Descent (SGD) and Adam in modern over-parameterized settings. However, existing line searches may take steps that are smaller than necessary since they require a monotone decrease of the (mini-)batch objective function. We explore nonmonotone line search methods to relax this condition and possibly accept larger step sizes. Despite the lack of a monotonic decrease, we prove the same fast rates of convergence as in the monotone case. Our experiments show that nonmonotone methods improve the speed of convergence and generalization properties of SGD/Adam even beyond the previous monotone line searches. We propose a POlyak NOnmonotone Stochastic (PoNoS) method, obtained by combining a nonmonotone line search with a Polyak initial step size. Furthermore, we develop a new resetting technique that in the majority of the iterations reduces the amount of backtracks to zero while still maintaining a large initial step size. To the best of our knowledge, a first runtime comparison shows that the epoch-wise advantage of line-search-based methods gets reflected in the overall computational time.
Robust Implicit Regularization via Weight Normalization
May 09, 2023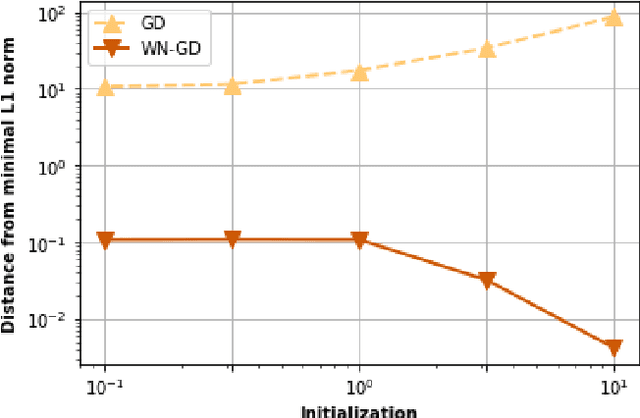
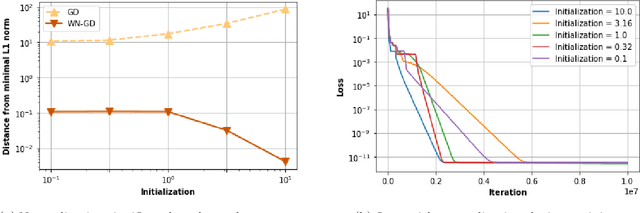
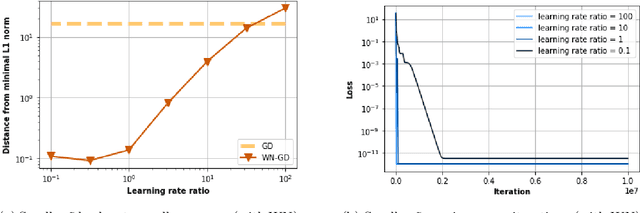
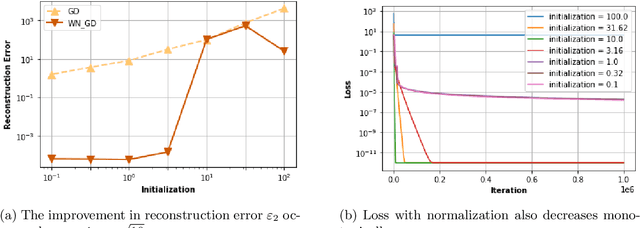
Overparameterized models may have many interpolating solutions; implicit regularization refers to the hidden preference of a particular optimization method towards a certain interpolating solution among the many. A by now established line of work has shown that (stochastic) gradient descent tends to have an implicit bias towards low rank and/or sparse solutions when used to train deep linear networks, explaining to some extent why overparameterized neural network models trained by gradient descent tend to have good generalization performance in practice. However, existing theory for square-loss objectives often requires very small initialization of the trainable weights, which is at odds with the larger scale at which weights are initialized in practice for faster convergence and better generalization performance. In this paper, we aim to close this gap by incorporating and analyzing gradient descent with weight normalization, where the weight vector is reparamterized in terms of polar coordinates, and gradient descent is applied to the polar coordinates. By analyzing key invariants of the gradient flow and using Lojasiewicz's Theorem, we show that weight normalization also has an implicit bias towards sparse solutions in the diagonal linear model, but that in contrast to plain gradient descent, weight normalization enables a robust bias that persists even if the weights are initialized at practically large scale. Experiments suggest that the gains in both convergence speed and robustness of the implicit bias are improved dramatically by using weight normalization in overparameterized diagonal linear network models.
More is Less: Inducing Sparsity via Overparameterization
Dec 21, 2021



In deep learning it is common to overparameterize the neural networks, that is, to use more parameters than training samples. Quite surprisingly training the neural network via (stochastic) gradient descent leads to models that generalize very well, while classical statistics would suggest overfitting. In order to gain understanding of this implicit bias phenomenon we study the special case of sparse recovery (compressive sensing) which is of interest on its own. More precisely, in order to reconstruct a vector from underdetermined linear measurements, we introduce a corresponding overparameterized square loss functional, where the vector to be reconstructed is deeply factorized into several vectors. We show that, under a very mild assumption on the measurement matrix, vanilla gradient flow for the overparameterized loss functional converges to a solution of minimal $\ell_1$-norm. The latter is well-known to promote sparse solutions. As a by-product, our results significantly improve the sample complexity for compressive sensing in previous works. The theory accurately predicts the recovery rate in numerical experiments. For the proofs, we introduce the concept of {\textit{solution entropy}}, which bypasses the obstacles caused by non-convexity and should be of independent interest.
Generalization Error Bounds for Iterative Recovery Algorithms Unfolded as Neural Networks
Dec 08, 2021



Motivated by the learned iterative soft thresholding algorithm (LISTA), we introduce a general class of neural networks suitable for sparse reconstruction from few linear measurements. By allowing a wide range of degrees of weight-sharing between the layers, we enable a unified analysis for very different neural network types, ranging from recurrent ones to networks more similar to standard feedforward neural networks. Based on training samples, via empirical risk minimization we aim at learning the optimal network parameters and thereby the optimal network that reconstructs signals from their low-dimensional linear measurements. We derive generalization bounds by analyzing the Rademacher complexity of hypothesis classes consisting of such deep networks, that also take into account the thresholding parameters. We obtain estimates of the sample complexity that essentially depend only linearly on the number of parameters and on the depth. We apply our main result to obtain specific generalization bounds for several practical examples, including different algorithms for (implicit) dictionary learning, and convolutional neural networks.
Spark Deficient Gabor Frames for Inverse Problems
Oct 13, 2021


In this paper, we apply star-Digital Gabor Transform in analysis Compressed Sensing and speech denoising. Based on assumptions on the ambient dimension, we produce a window vector that generates a spark deficient Gabor frame with many linear dependencies among its elements. We conduct computational experiments on both synthetic and real-world signals, using as baseline three Gabor transforms generated by state-of-the-art window vectors and compare their performance to star-Gabor transform. Results show that the proposed star-Gabor transform outperforms all others in all signal cases.
ADMM-DAD net: a deep unfolding network for analysis compressed sensing
Oct 13, 2021


In this paper, we propose a new deep unfolding neural network based on the ADMM algorithm for analysis Compressed Sensing. The proposed network jointly learns a redundant analysis operator for sparsification and reconstructs the signal of interest. We compare our proposed network with a state-of-the-art unfolded ISTA decoder, that also learns an orthogonal sparsifier. Moreover, we consider not only image, but also speech datasets as test examples. Computational experiments demonstrate that our proposed network outperforms the state-of-the-art deep unfolding networks, consistently for both real-world image and speech datasets.
Path classification by stochastic linear recurrent neural networks
Aug 06, 2021



We investigate the functioning of a classifying biological neural network from the perspective of statistical learning theory, modelled, in a simplified setting, as a continuous-time stochastic recurrent neural network (RNN) with identity activation function. In the purely stochastic (robust) regime, we give a generalisation error bound that holds with high probability, thus showing that the empirical risk minimiser is the best-in-class hypothesis. We show that RNNs retain a partial signature of the paths they are fed as the unique information exploited for training and classification tasks. We argue that these RNNs are easy to train and robust and back these observations with numerical experiments on both synthetic and real data. We also exhibit a trade-off phenomenon between accuracy and robustness.
Convergence of gradient descent for learning linear neural networks
Aug 04, 2021

We study the convergence properties of gradient descent for training deep linear neural networks, i.e., deep matrix factorizations, by extending a previous analysis for the related gradient flow. We show that under suitable conditions on the step sizes gradient descent converges to a critical point of the loss function, i.e., the square loss in this article. Furthermore, we demonstrate that for almost all initializations gradient descent converges to a global minimum in the case of two layers. In the case of three or more layers we show that gradient descent converges to a global minimum on the manifold matrices of some fixed rank, where the rank cannot be determined a priori.
Star DGT: a Robust Gabor Transform for Speech Denoising
Apr 29, 2021



In this paper, we address the speech denoising problem, where white Gaussian additive noise is to be removed from a given speech signal. Our approach is based on a redundant, analysis-sparse representation of the original speech signal. We pick an eigenvector of the Zauner unitary matrix and -- under certain assumptions on the ambient dimension -- we use it as window vector to generate a spark deficient Gabor frame. The analysis operator associated with such a frame, is a (highly) redundant Gabor transform, which we use as a sparsifying transform in denoising procedure. We conduct computational experiments on real-world speech data, solving the analysis basis pursuit denoising problem, with four different choices of analysis operators, including our Gabor analysis operator. The results show that our proposed redundant Gabor transform outperforms -- in all cases -- Gabor transforms generated by state-of-the-art window vectors of time-frequency analysis.