 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMark Schmidt
Enhancing Policy Gradient with the Polyak Step-Size Adaption
Apr 11, 2024
Policy gradient is a widely utilized and foundational algorithm in the field of reinforcement learning (RL). Renowned for its convergence guarantees and stability compared to other RL algorithms, its practical application is often hindered by sensitivity to hyper-parameters, particularly the step-size. In this paper, we introduce the integration of the Polyak step-size in RL, which automatically adjusts the step-size without prior knowledge. To adapt this method to RL settings, we address several issues, including unknown f* in the Polyak step-size. Additionally, we showcase the performance of the Polyak step-size in RL through experiments, demonstrating faster convergence and the attainment of more stable policies.
Faster Convergence of Stochastic Accelerated Gradient Descent under Interpolation
Apr 03, 2024We prove new convergence rates for a generalized version of stochastic Nesterov acceleration under interpolation conditions. Unlike previous analyses, our approach accelerates any stochastic gradient method which makes sufficient progress in expectation. The proof, which proceeds using the estimating sequences framework, applies to both convex and strongly convex functions and is easily specialized to accelerated SGD under the strong growth condition. In this special case, our analysis reduces the dependence on the strong growth constant from $\rho$ to $\sqrt{\rho}$ as compared to prior work. This improvement is comparable to a square-root of the condition number in the worst case and address criticism that guarantees for stochastic acceleration could be worse than those for SGD.
Heavy-Tailed Class Imbalance and Why Adam Outperforms Gradient Descent on Language Models
Feb 29, 2024Adam has been shown to outperform gradient descent in optimizing large language transformers empirically, and by a larger margin than on other tasks, but it is unclear why this happens. We show that the heavy-tailed class imbalance found in language modeling tasks leads to difficulties in the optimization dynamics. When training with gradient descent, the loss associated with infrequent words decreases slower than the loss associated with frequent ones. As most samples come from relatively infrequent words, the average loss decreases slowly with gradient descent. On the other hand, Adam and sign-based methods do not suffer from this problem and improve predictions on all classes. To establish that this behavior is indeed caused by class imbalance, we show empirically that it persist through different architectures and data types, on language transformers, vision CNNs, and linear models. We further study this phenomenon on a linear classification with cross-entropy loss, showing that heavy-tailed class imbalance leads to ill-conditioning, and that the normalization used by Adam can counteract it.
Analyzing and Improving Greedy 2-Coordinate Updates for Equality-Constrained Optimization via Steepest Descent in the 1-Norm
Jul 03, 2023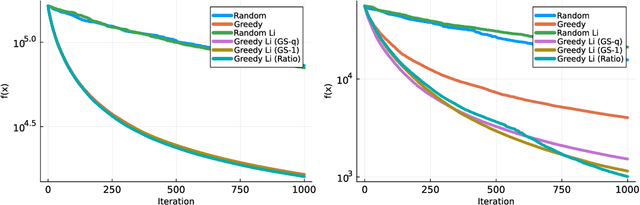
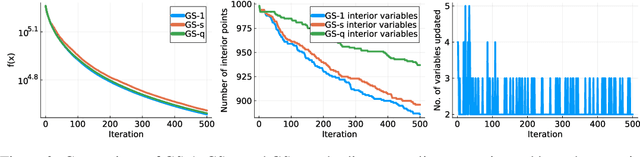
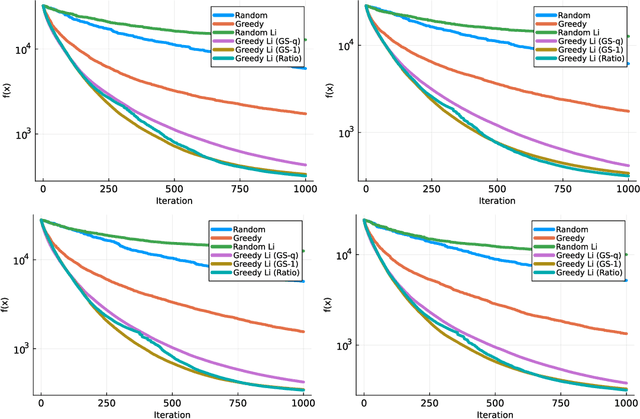
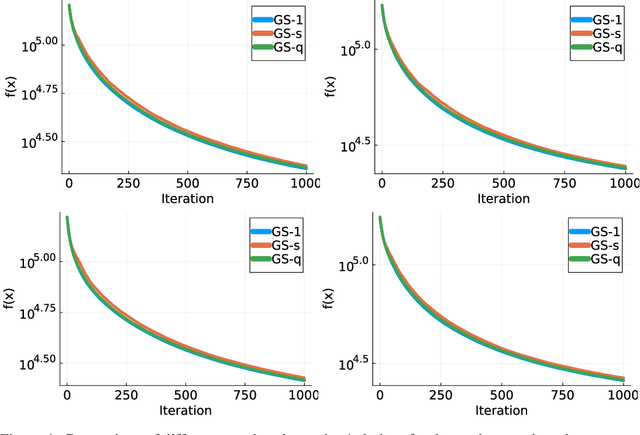
We consider minimizing a smooth function subject to a summation constraint over its variables. By exploiting a connection between the greedy 2-coordinate update for this problem and equality-constrained steepest descent in the 1-norm, we give a convergence rate for greedy selection under a proximal Polyak-Lojasiewicz assumption that is faster than random selection and independent of the problem dimension $n$. We then consider minimizing with both a summation constraint and bound constraints, as arises in the support vector machine dual problem. Existing greedy rules for this setting either guarantee trivial progress only or require $O(n^2)$ time to compute. We show that bound- and summation-constrained steepest descent in the L1-norm guarantees more progress per iteration than previous rules and can be computed in only $O(n \log n)$ time.
Don't be so Monotone: Relaxing Stochastic Line Search in Over-Parameterized Models
Jun 22, 2023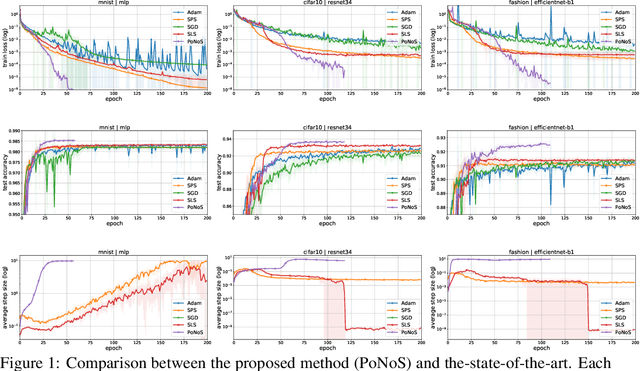
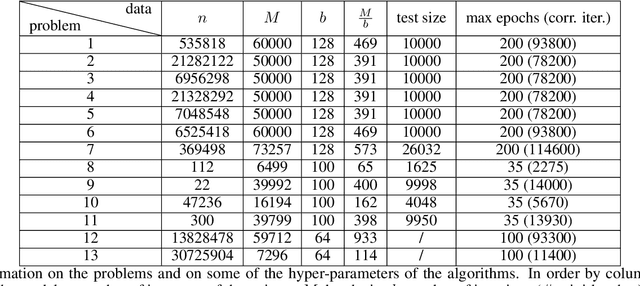
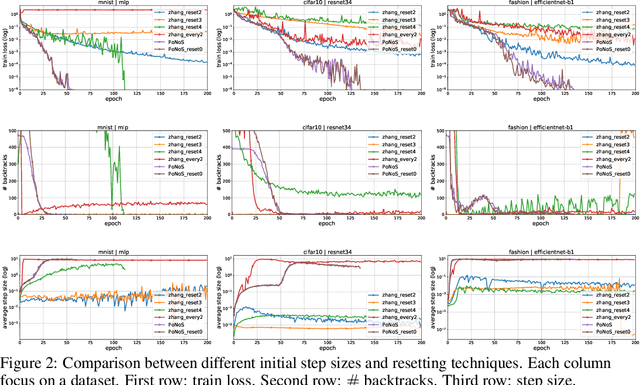

Recent works have shown that line search methods can speed up Stochastic Gradient Descent (SGD) and Adam in modern over-parameterized settings. However, existing line searches may take steps that are smaller than necessary since they require a monotone decrease of the (mini-)batch objective function. We explore nonmonotone line search methods to relax this condition and possibly accept larger step sizes. Despite the lack of a monotonic decrease, we prove the same fast rates of convergence as in the monotone case. Our experiments show that nonmonotone methods improve the speed of convergence and generalization properties of SGD/Adam even beyond the previous monotone line searches. We propose a POlyak NOnmonotone Stochastic (PoNoS) method, obtained by combining a nonmonotone line search with a Polyak initial step size. Furthermore, we develop a new resetting technique that in the majority of the iterations reduces the amount of backtracks to zero while still maintaining a large initial step size. To the best of our knowledge, a first runtime comparison shows that the epoch-wise advantage of line-search-based methods gets reflected in the overall computational time.
Searching for Optimal Per-Coordinate Step-sizes with Multidimensional Backtracking
Jun 05, 2023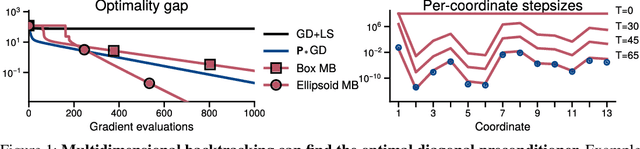
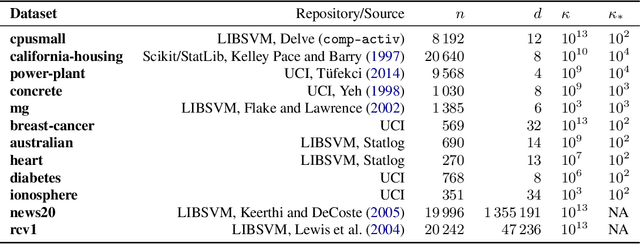


The backtracking line-search is an effective technique to automatically tune the step-size in smooth optimization. It guarantees similar performance to using the theoretically optimal step-size. Many approaches have been developed to instead tune per-coordinate step-sizes, also known as diagonal preconditioners, but none of the existing methods are provably competitive with the optimal per-coordinate stepsizes. We propose multidimensional backtracking, an extension of the backtracking line-search to find good diagonal preconditioners for smooth convex problems. Our key insight is that the gradient with respect to the step-sizes, also known as hypergradients, yields separating hyperplanes that let us search for good preconditioners using cutting-plane methods. As black-box cutting-plane approaches like the ellipsoid method are computationally prohibitive, we develop an efficient algorithm tailored to our setting. Multidimensional backtracking is provably competitive with the best diagonal preconditioner and requires no manual tuning.
BiSLS/SPS: Auto-tune Step Sizes for Stable Bi-level Optimization
May 30, 2023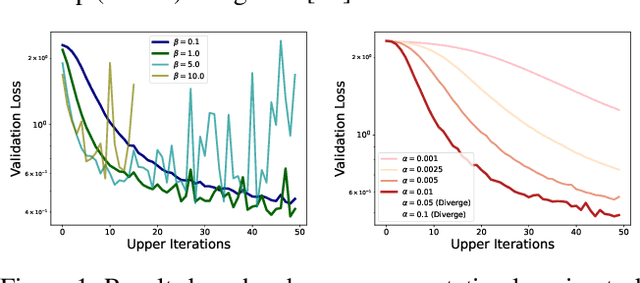


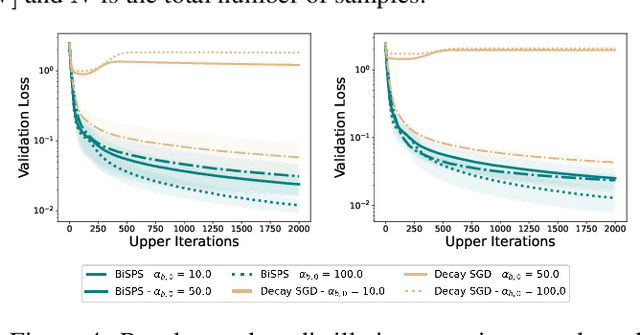
The popularity of bi-level optimization (BO) in deep learning has spurred a growing interest in studying gradient-based BO algorithms. However, existing algorithms involve two coupled learning rates that can be affected by approximation errors when computing hypergradients, making careful fine-tuning necessary to ensure fast convergence. To alleviate this issue, we investigate the use of recently proposed adaptive step-size methods, namely stochastic line search (SLS) and stochastic Polyak step size (SPS), for computing both the upper and lower-level learning rates. First, we revisit the use of SLS and SPS in single-level optimization without the additional interpolation condition that is typically assumed in prior works. For such settings, we investigate new variants of SLS and SPS that improve upon existing suggestions in the literature and are simpler to implement. Importantly, these two variants can be seen as special instances of general family of methods with an envelope-type step-size. This unified envelope strategy allows for the extension of the algorithms and their convergence guarantees to BO settings. Finally, our extensive experiments demonstrate that the new algorithms, which are available in both SGD and Adam versions, can find large learning rates with minimal tuning and converge faster than corresponding vanilla SGD or Adam BO algorithms that require fine-tuning.
Noise Is Not the Main Factor Behind the Gap Between SGD and Adam on Transformers, but Sign Descent Might Be
Apr 27, 2023
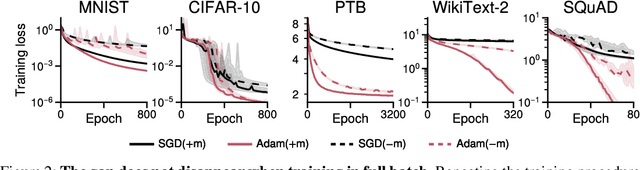
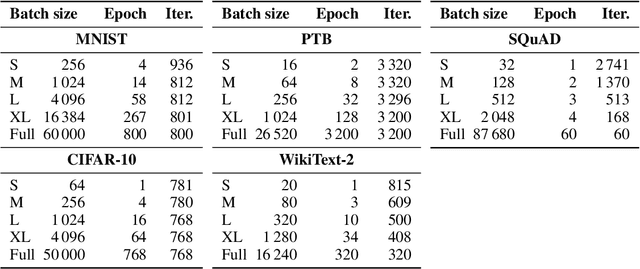
The success of the Adam optimizer on a wide array of architectures has made it the default in settings where stochastic gradient descent (SGD) performs poorly. However, our theoretical understanding of this discrepancy is lagging, preventing the development of significant improvements on either algorithm. Recent work advances the hypothesis that Adam and other heuristics like gradient clipping outperform SGD on language tasks because the distribution of the error induced by sampling has heavy tails. This suggests that Adam outperform SGD because it uses a more robust gradient estimate. We evaluate this hypothesis by varying the batch size, up to the entire dataset, to control for stochasticity. We present evidence that stochasticity and heavy-tailed noise are not major factors in the performance gap between SGD and Adam. Rather, Adam performs better as the batch size increases, while SGD is less effective at taking advantage of the reduction in noise. This raises the question as to why Adam outperforms SGD in the full-batch setting. Through further investigation of simpler variants of SGD, we find that the behavior of Adam with large batches is similar to sign descent with momentum.
Fast Convergence of Random Reshuffling under Over-Parameterization and the Polyak-Łojasiewicz Condition
Apr 02, 2023
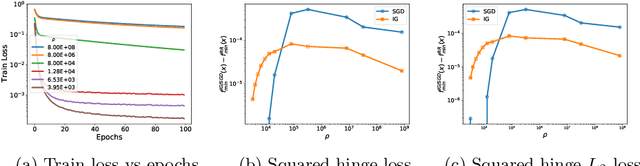
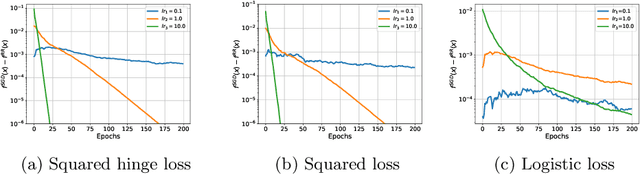

Modern machine learning models are often over-parameterized and as a result they can interpolate the training data. Under such a scenario, we study the convergence properties of a sampling-without-replacement variant of stochastic gradient descent (SGD) known as random reshuffling (RR). Unlike SGD that samples data with replacement at every iteration, RR chooses a random permutation of data at the beginning of each epoch and each iteration chooses the next sample from the permutation. For under-parameterized models, it has been shown RR can converge faster than SGD under certain assumptions. However, previous works do not show that RR outperforms SGD in over-parameterized settings except in some highly-restrictive scenarios. For the class of Polyak-\L ojasiewicz (PL) functions, we show that RR can outperform SGD in over-parameterized settings when either one of the following holds: (i) the number of samples ($n$) is less than the product of the condition number ($\kappa$) and the parameter ($\alpha$) of a weak growth condition (WGC), or (ii) $n$ is less than the parameter ($\rho$) of a strong growth condition (SGC).
Simplifying Momentum-based Riemannian Submanifold Optimization
Feb 20, 2023



Riemannian submanifold optimization with momentum is computationally challenging because ensuring iterates remain on the submanifold often requires solving difficult differential equations. We simplify such optimization algorithms for the submanifold of symmetric positive-definite matrices with the affine invariant metric. We propose a generalized version of the Riemannian normal coordinates which dynamically trivializes the problem into a Euclidean unconstrained problem. We use our approach to explain and simplify existing approaches for structured covariances and develop efficient second-order optimizers for deep learning without explicit matrix inverses.