 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMartin Takáč
Enhancing Policy Gradient with the Polyak Step-Size Adaption
Apr 11, 2024
Policy gradient is a widely utilized and foundational algorithm in the field of reinforcement learning (RL). Renowned for its convergence guarantees and stability compared to other RL algorithms, its practical application is often hindered by sensitivity to hyper-parameters, particularly the step-size. In this paper, we introduce the integration of the Polyak step-size in RL, which automatically adjusts the step-size without prior knowledge. To adapt this method to RL settings, we address several issues, including unknown f* in the Polyak step-size. Additionally, we showcase the performance of the Polyak step-size in RL through experiments, demonstrating faster convergence and the attainment of more stable policies.
FRESCO: Federated Reinforcement Energy System for Cooperative Optimization
Mar 27, 2024The rise in renewable energy is creating new dynamics in the energy grid that promise to create a cleaner and more participative energy grid, where technology plays a crucial part in making the required flexibility to achieve the vision of the next-generation grid. This work presents FRESCO, a framework that aims to ease the implementation of energy markets using a hierarchical control architecture of reinforcement learning agents trained using federated learning. The core concept we are proving is that having greedy agents subject to changing conditions from a higher level agent creates a cooperative setup that will allow for fulfilling all the individual objectives. This paper presents a general overview of the framework, the current progress, and some insights we obtained from the recent results.
Generalized Policy Learning for Smart Grids: FL TRPO Approach
Mar 27, 2024The smart grid domain requires bolstering the capabilities of existing energy management systems; Federated Learning (FL) aligns with this goal as it demonstrates a remarkable ability to train models on heterogeneous datasets while maintaining data privacy, making it suitable for smart grid applications, which often involve disparate data distributions and interdependencies among features that hinder the suitability of linear models. This paper introduces a framework that combines FL with a Trust Region Policy Optimization (FL TRPO) aiming to reduce energy-associated emissions and costs. Our approach reveals latent interconnections and employs personalized encoding methods to capture unique insights, understanding the relationships between features and optimal strategies, allowing our model to generalize to previously unseen data. Experimental results validate the robustness of our approach, affirming its proficiency in effectively learning policy models for smart grid challenges.
Federated Learning Can Find Friends That Are Beneficial
Feb 14, 2024In Federated Learning (FL), the distributed nature and heterogeneity of client data present both opportunities and challenges. While collaboration among clients can significantly enhance the learning process, not all collaborations are beneficial; some may even be detrimental. In this study, we introduce a novel algorithm that assigns adaptive aggregation weights to clients participating in FL training, identifying those with data distributions most conducive to a specific learning objective. We demonstrate that our aggregation method converges no worse than the method that aggregates only the updates received from clients with the same data distribution. Furthermore, empirical evaluations consistently reveal that collaborations guided by our algorithm outperform traditional FL approaches. This underscores the critical role of judicious client selection and lays the foundation for more streamlined and effective FL implementations in the coming years.
AdaBatchGrad: Combining Adaptive Batch Size and Adaptive Step Size
Feb 07, 2024This paper presents a novel adaptation of the Stochastic Gradient Descent (SGD), termed AdaBatchGrad. This modification seamlessly integrates an adaptive step size with an adjustable batch size. An increase in batch size and a decrease in step size are well-known techniques to tighten the area of convergence of SGD and decrease its variance. A range of studies by R. Byrd and J. Nocedal introduced various testing techniques to assess the quality of mini-batch gradient approximations and choose the appropriate batch sizes at every step. Methods that utilized exact tests were observed to converge within $O(LR^2/\varepsilon)$ iterations. Conversely, inexact test implementations sometimes resulted in non-convergence and erratic performance. To address these challenges, AdaBatchGrad incorporates both adaptive batch and step sizes, enhancing the method's robustness and stability. For exact tests, our approach converges in $O(LR^2/\varepsilon)$ iterations, analogous to standard gradient descent. For inexact tests, it achieves convergence in $O(\max\lbrace LR^2/\varepsilon, \sigma^2 R^2/\varepsilon^2 \rbrace )$ iterations. This makes AdaBatchGrad markedly more robust and computationally efficient relative to prevailing methods. To substantiate the efficacy of our method, we experimentally show, how the introduction of adaptive step size and adaptive batch size gradually improves the performance of regular SGD. The results imply that AdaBatchGrad surpasses alternative methods, especially when applied to inexact tests.
SANIA: Polyak-type Optimization Framework Leads to Scale Invariant Stochastic Algorithms
Dec 28, 2023Adaptive optimization methods are widely recognized as among the most popular approaches for training Deep Neural Networks (DNNs). Techniques such as Adam, AdaGrad, and AdaHessian utilize a preconditioner that modifies the search direction by incorporating information about the curvature of the objective function. However, despite their adaptive characteristics, these methods still require manual fine-tuning of the step-size. This, in turn, impacts the time required to solve a particular problem. This paper presents an optimization framework named SANIA to tackle these challenges. Beyond eliminating the need for manual step-size hyperparameter settings, SANIA incorporates techniques to address poorly scaled or ill-conditioned problems. We also explore several preconditioning methods, including Hutchinson's method, which approximates the Hessian diagonal of the loss function. We conclude with an extensive empirical examination of the proposed techniques across classification tasks, covering both convex and non-convex contexts.
Dirichlet-based Uncertainty Quantification for Personalized Federated Learning with Improved Posterior Networks
Dec 18, 2023In modern federated learning, one of the main challenges is to account for inherent heterogeneity and the diverse nature of data distributions for different clients. This problem is often addressed by introducing personalization of the models towards the data distribution of the particular client. However, a personalized model might be unreliable when applied to the data that is not typical for this client. Eventually, it may perform worse for these data than the non-personalized global model trained in a federated way on the data from all the clients. This paper presents a new approach to federated learning that allows selecting a model from global and personalized ones that would perform better for a particular input point. It is achieved through a careful modeling of predictive uncertainties that helps to detect local and global in- and out-of-distribution data and use this information to select the model that is confident in a prediction. The comprehensive experimental evaluation on the popular real-world image datasets shows the superior performance of the model in the presence of out-of-distribution data while performing on par with state-of-the-art personalized federated learning algorithms in the standard scenarios.
Byzantine-Tolerant Methods for Distributed Variational Inequalities
Nov 08, 2023
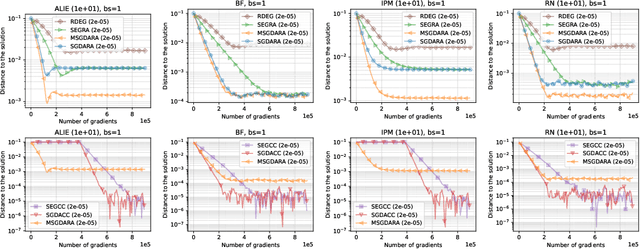
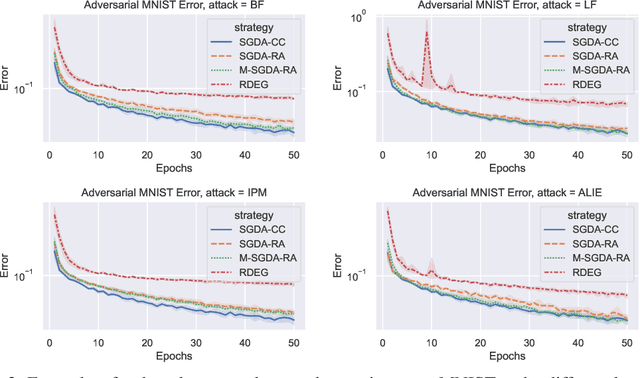
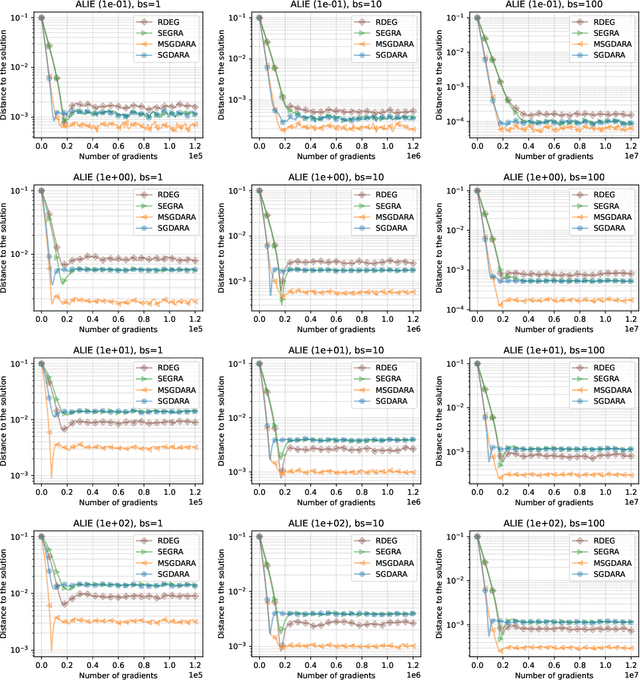
Robustness to Byzantine attacks is a necessity for various distributed training scenarios. When the training reduces to the process of solving a minimization problem, Byzantine robustness is relatively well-understood. However, other problem formulations, such as min-max problems or, more generally, variational inequalities, arise in many modern machine learning and, in particular, distributed learning tasks. These problems significantly differ from the standard minimization ones and, therefore, require separate consideration. Nevertheless, only one work (Adibi et al., 2022) addresses this important question in the context of Byzantine robustness. Our work makes a further step in this direction by providing several (provably) Byzantine-robust methods for distributed variational inequality, thoroughly studying their theoretical convergence, removing the limitations of the previous work, and providing numerical comparisons supporting the theoretical findings.
Stochastic Gradient Descent with Preconditioned Polyak Step-size
Oct 03, 2023Stochastic Gradient Descent (SGD) is one of the many iterative optimization methods that are widely used in solving machine learning problems. These methods display valuable properties and attract researchers and industrial machine learning engineers with their simplicity. However, one of the weaknesses of this type of methods is the necessity to tune learning rate (step-size) for every loss function and dataset combination to solve an optimization problem and get an efficient performance in a given time budget. Stochastic Gradient Descent with Polyak Step-size (SPS) is a method that offers an update rule that alleviates the need of fine-tuning the learning rate of an optimizer. In this paper, we propose an extension of SPS that employs preconditioning techniques, such as Hutchinson's method, Adam, and AdaGrad, to improve its performance on badly scaled and/or ill-conditioned datasets.